基于 Zeppelin 的 Flink/Spark 云原生实践

本文整理自火山引擎基础架构研发工程师陶克路、王正在 ApacheCon Asia 2022 上的演讲。文章主要介绍了 Apache Zeppelin 支持 Flink 和 Spark 云原生实践。
作者 | 火山引擎云原生
计算研发工程师-陶克路、火山引擎云原生
计算研发工程师-王正
Apache Zeppelin 介绍
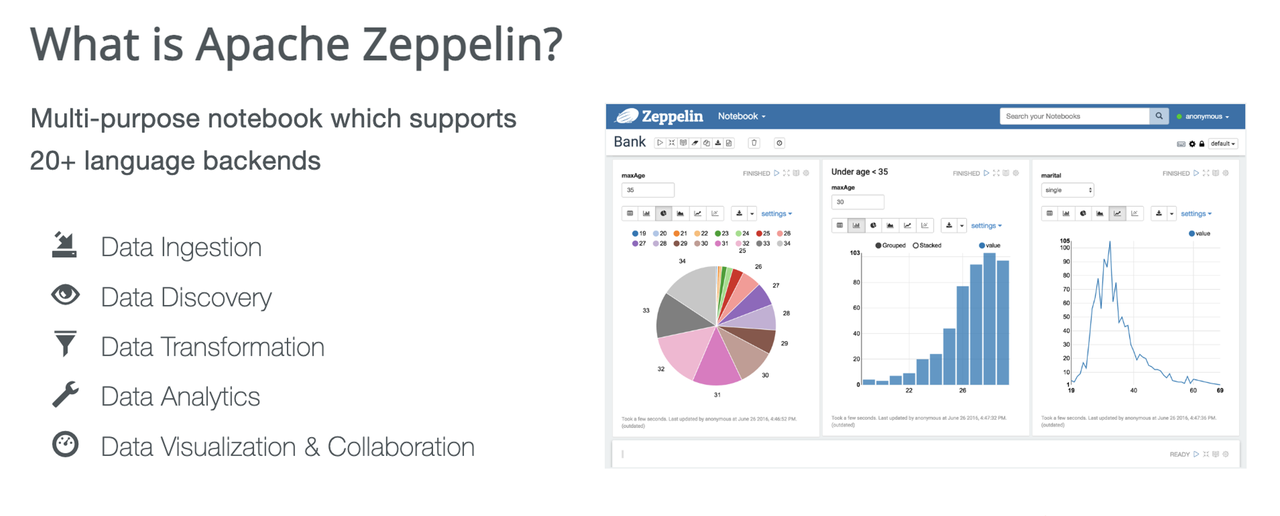
Apache Zeppelin 是一个支持 20 多种语言 Notebook 的后端,可以用于数据摄入、发现、转换及分析,也能够实现数据的可视化,如饼图、柱状图、折线图等。
典型使用场景是通过开发 Zeppelin 的代码片段或者 SQL,通过提交到后端实现实时交互,并通过编写 Notebook 的 Paragraph 集合,借助调度系统实现定时调度任务。
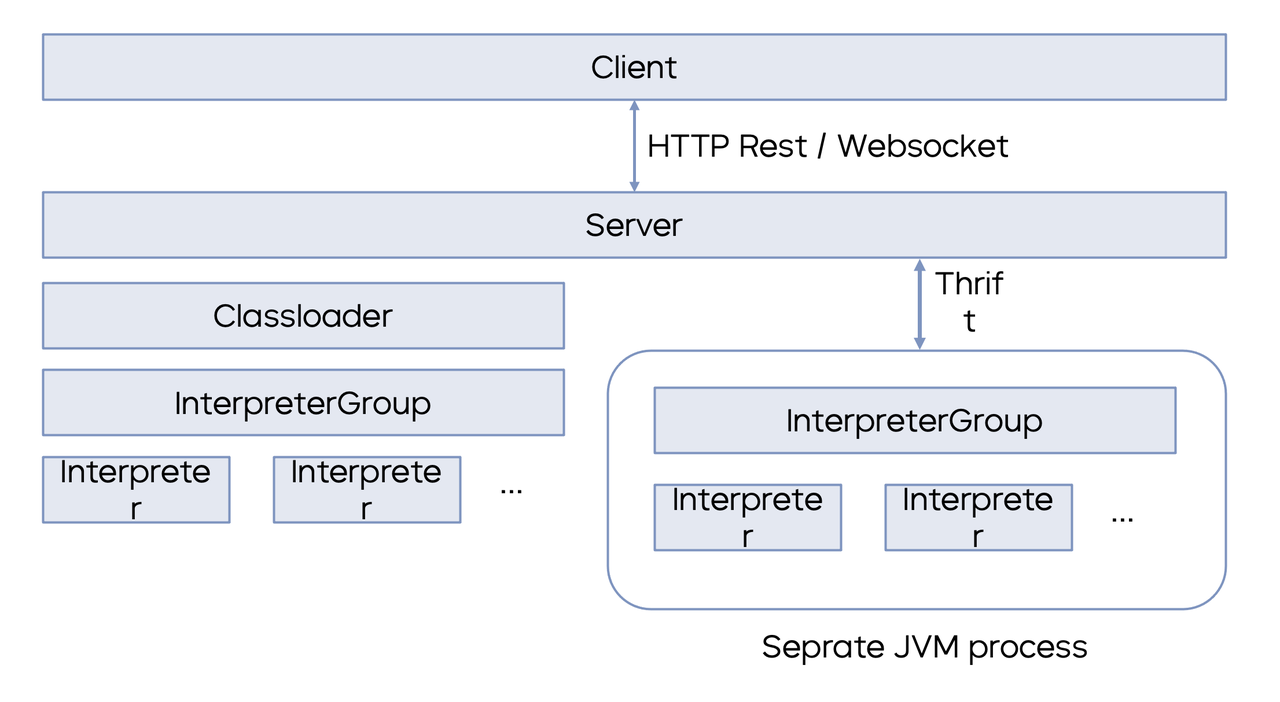
Zeppelin 的技术架构包含三个部分:Client、Server 和 Interpreter。Client 和 Server 通过 Restful 接口或 WebSocket 接口进行交互,Interpreter 解释器则是一个独立于 Zeppelin Server 的进程,在 K8s 环境上面拥有独立的 POD 和环境信息。
Apache Zeppelin 的云原生实践
Apache Zeppelin 的云原生实践包含五个部分:
-
Docker 镜像优化:开源 Zeppelin 包含了较多的解释器,在火山引擎的实践过程中,我们通过裁剪只包含 Flink 和 Spark 的部分,同时利用 Docker 镜像的多阶段构建技术,达到镜像缩小、体积缩小的目的,实现镜像层数的缩减;
-
元数据 存储:Zeppelin 包含多种元数据,其中重要的元数据 Notebook 可以支持本地文件的存储、远程存储、对象存储等;在扩展之后能够支持火山引擎 TosNotabookRepo 的对象存储;另外一种存储则需要借助 K8s 里的 Persistent Volume 机制,将一块磁盘/云盘,映射成固定的 Volume 挂载到 POD 内部实现自动/手动的存储;
-
跨 N ame s pace 提交作业:Namespace 在 K8s 中的实现机制为逻辑隔离但底层 Node 共享,我们以此实现单租户/多租户不同子账号之间的隔离及资源的不互通;通过支持 Zeppelin 跨 namespace 提交作业的功能来用户功能的完整性;
-
RBAC 权限:RBAC 权限也是 K8s 提供的权限机制,包含:实体、权限和权限的关联。K8s 的权限可以分为两种:分别是在 Namespace 内部的权限和跨 Namespace 资源的权限,跨 Namespace 资源的权限需要通过 Cluster Role 先进行权限的声明,并与 ServiceAccount 绑定后实现;

Namespace 内部
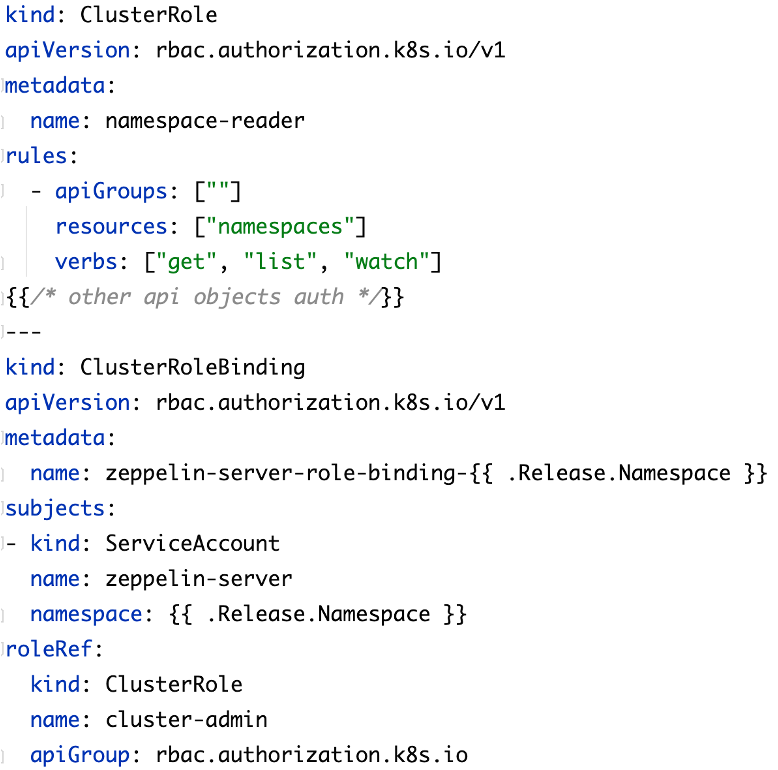
跨 Namespace
-
SSO 单点登录:在集成 Zeppelin 后,用户使用作业平台时已经产生过登录的动作,再次登陆Zeppelin对用户的使用体验很不友好。所以基于 Shiro 做相应的扩展,通过增加 Shiro Plugin 共享 JWT Token 的方式避免用户二次登录,提升用户使用体验。
基于 Zeppelin 的 Flink 云原生实践
Flink on K8s 的工作原理
目前 Flink on K8s 主要有两种工作方式:
-
Standalone:在提交作业之前,先使用 K8s 的 Deployment 方式将 Flink Cluster 部署启动,启动之后再进行作业的提交。这种方式主要的弊端在于在运行作业之前需要预先申请所有的资源,由于整体资源是固定的,所以如果对于作业使用的资源预估不准确,就会造成资源浪费或资源不足,从而导致作业无法执行成功。
-
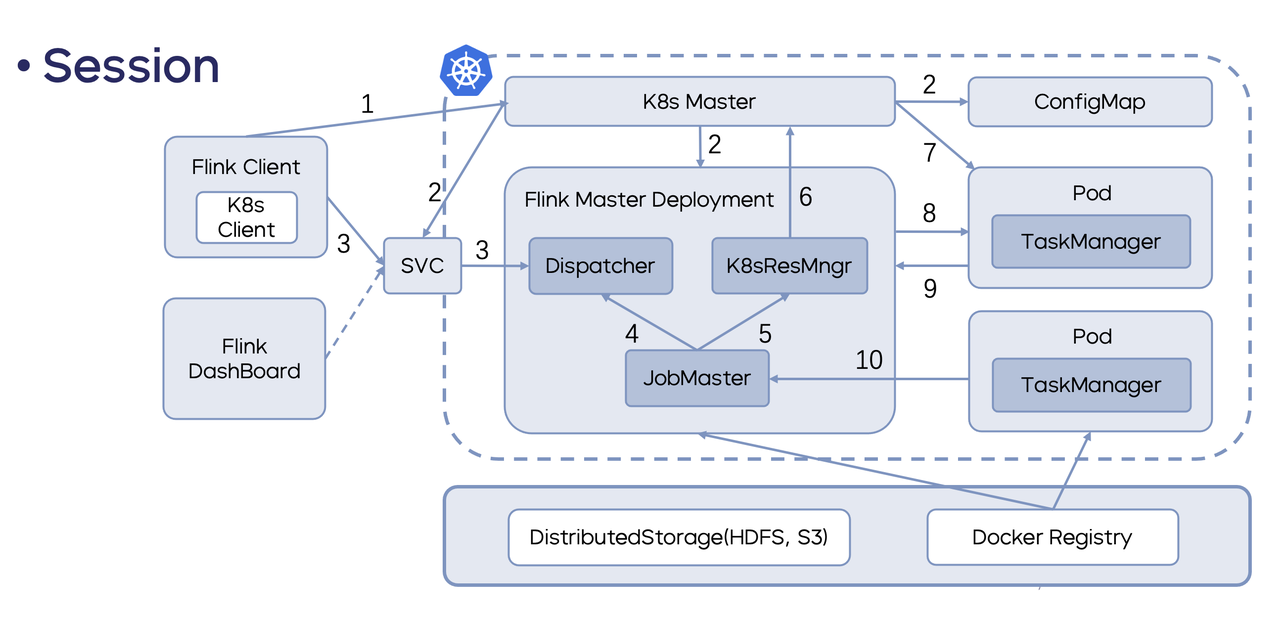
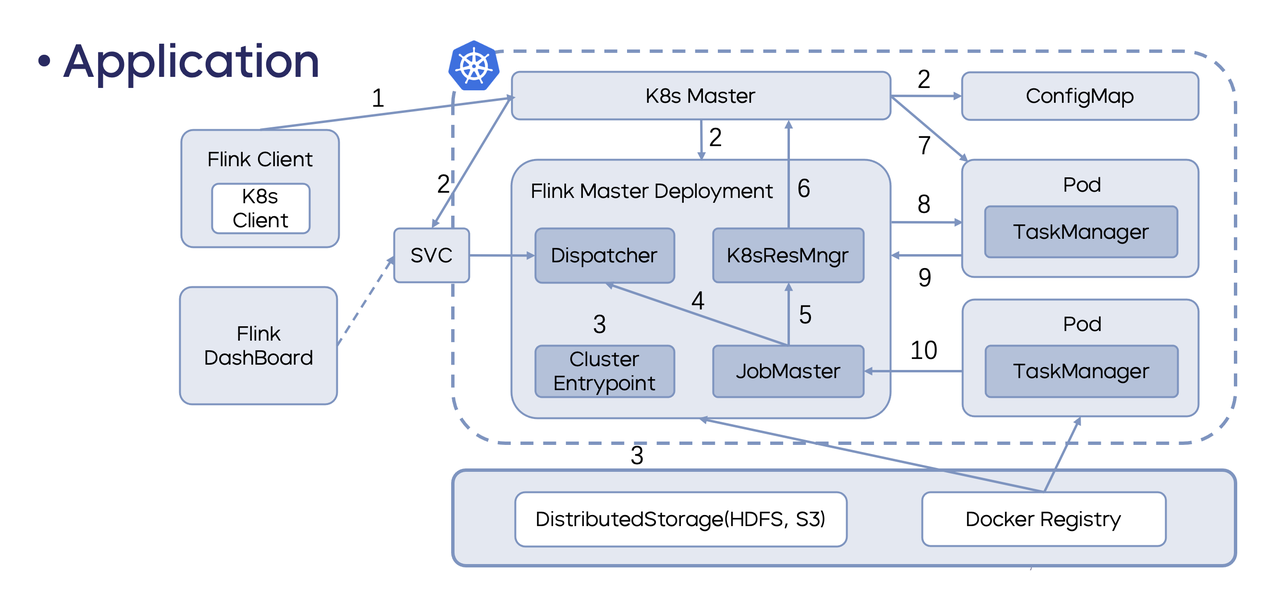
Native K8 s:Native K8s 和 Standalone 方式最大区别是借助 Flink 里的 ResourceManager 请求资源进行按需创建。目前 Flink 的 Native K8s 支持两种方式:Session 和 Application。
-
Session:Flink 自身支持的集群方式。
-
首先,启动一个 Session 集群,然后进行作业的提交。
-
第二步,启动 SVC、Deployment、ConfigMap,包括另外一个 SVC,通过外部网络进行访问。这一步启动的资源中并不包含 TaskManager,后续的 TaskManager 需要按需申请。
-
第三步,用户通过 Flink Client 提交作业,通过 Flink Client 中内置的 K8s Client 找到相应 Session 集群的 Endpoint,并计算程序所需的资源, K8s APIServer 创建 TaskManager 后,TaskManager 将心跳注册到 JobManager 的 ResourceManager 里面,最终在 TaskManager 上进行作业的提交和运行。
-
Session 集群的使用主要用于共享资源,主要在测试环境使用的比较多,这种方式的优势在于资源使用率较高。
-
-
Application:Flink 在 1.11 版本前的作业,JobGraph 的编译等操作都是在客户端进行的,这种模式会造成 client 所在机器负载高、网络压力大、CPU 资源不足等问题,所以 1.11 版本 Flink 推出了 Application Mode 的方式,主要将 Main 的 Job 生成操作放到 JobManager 中,由此 Flink Client 所需承担的操作就变得相对简单,不需要再承担上述额外的操作,即 Application 模式是不需要提前创建作业的。
-
具体的步骤可以简述为用户首先通过 Flink Client 提交到指定 Target IP 的 K8s,然后 Client 通过内置的 K8s 的 Client 找到 K8s APIServer,再通过创建该作业必需的 Job Manager 资源并传输到 Job Manager 里面,由此实现了资源的申请。
-
Application 模式相比 Session 最大的一个区别就是 Application 模式下每个作业对应一个Flink class,相对应的作业完成后,Flink class 就会进行销毁,资源使用率没有 Session 模式高,但是隔离性会更好,所以在生产上也推荐使用 Application 模式。
-
-
Flink on Zeppelin 的工作原理
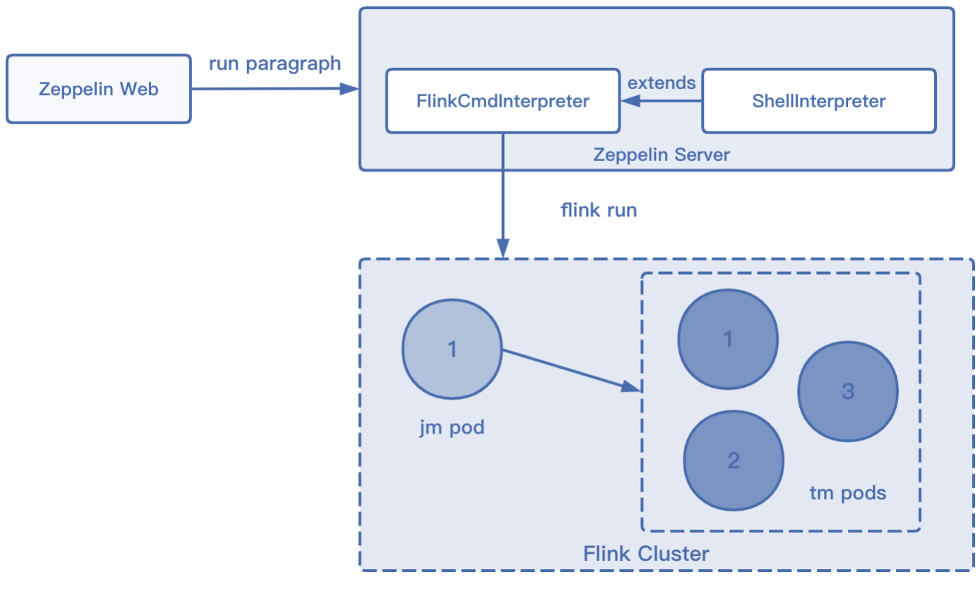
Flink on Zeppelin 的工作基本都是用解释器实现的,Flink 的解释器大体上可分为两种,FlinkCmd 解释器和其他 Flink 解释器。
-
FlinkCmd 解释器顾名思义就是用命令行的方式提交 Flink 程序;
-
另外一种也是较为常用的解释器,是 % Flink 的解释器,它的运行方式和 FlinkCmd 解释器区别较大,用户提交代码之后会启动一个 Flink Cluster,是由 Zeppelin 提供的 Main Jar,并进行交互操作,将用户的代码提交给 TM 后返回结果,这种方式和 Session 模式的区别是集群资源固定,即 JM、TM 的数目和所使用的资源是固定的,无法根据 TM 代码的执行情况动态调整,用户也无法指定资源。
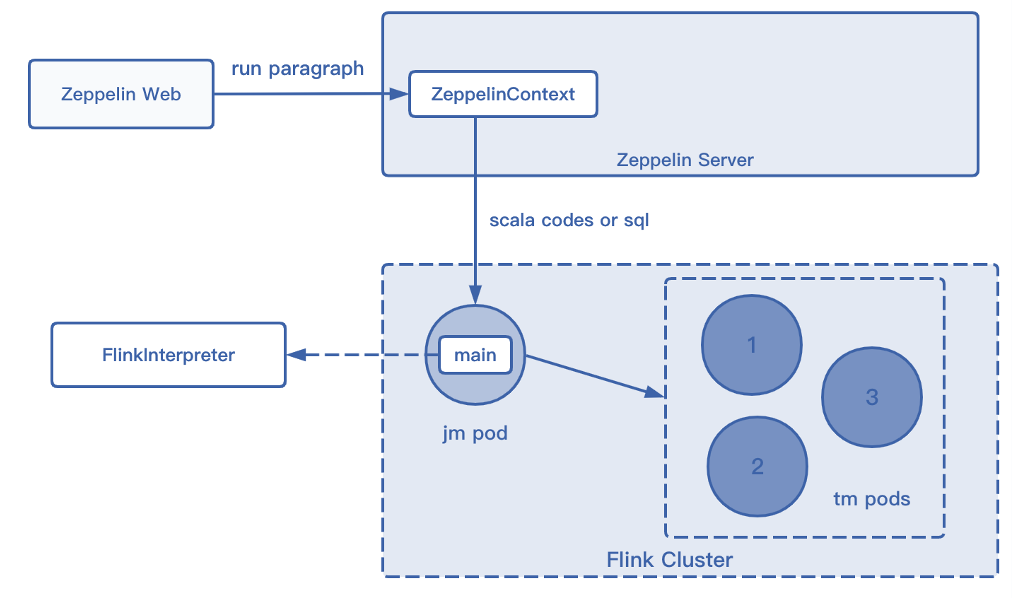
Flink on Zeppelin 的功能增强
火山引擎对 Flink on Zeppelin 进行了功能增强,主要有以下几个方面:
-
支持 N ative K8s 模式
-
Flink UI 透出:支持 Ingress / NodePort 类型;Node Port 适用于私有云相关的场景,比如可以通过 Node 的 IP 和端口直接访问 Flink UI。 Ingress 模式由 Main Class 在运行中创建 Ingress 路由,用户的请求通过 Ingress 请求到对应的 Flink 的 Cluster,整个 Ingress 的生命周期是和 Flink 的 Cluster 中的 Deployment 绑定的。在相应的 Flink Cluster 结束后,对应的 Ingress 也会被销毁掉。
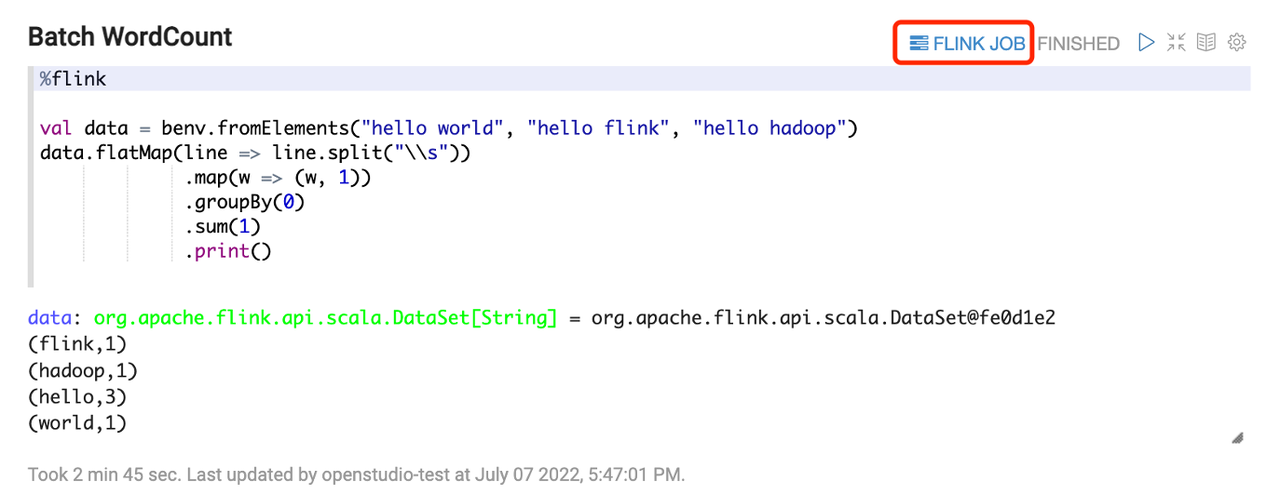
-
Jar 功能增强:Zeppelin 原生支持用 Flink UDF 依赖的 Jar 包。这些 Jar 包可以存储到本地或 HDFS 中,但云原生场景通常不会使用本地存储的内容,对此我们做了相应的增强:
-
支持引用 http / https 资源;
-
支持引用 S3 协议的存储资源,因为在云上的存储大部分都会用支持 S3 协议的对象存储,比如 AWS 的 S3、阿里云的 OSS、火山引擎的头条 TOS等,所以在此做增强后可以在执行时支持动态下载远程的 Jar 包。
-
-
支持 HiveCatalog 原生的 SQL 模式,用于实现元数据的复用。
-
支持跨 N amespace 提交作业 :原始的 Namespace 隔离了一些权限和资源,每个 Namespace 拥有单独的 Quota;在 K8s 场景下,Zeppelin 可以运行在一个 Namespace 中,然后将作业启动在其他的 Namespace 中,由此支持跨 Namespace 提交作业。
-
支持镜像外的 M ain J ar 提交 :在原始的 Flink 的 Application 模式下,用户需要提交的 Image 当中包含运行的 Main Jar,因此每个用户每提交一段代码都需要提交一个 Image,不仅操作繁琐,还会占用整个集群当中过多的存储资源,后续对于 Image 的升级也是一个难点。所以,我们通过支持镜像外的 Main Jar 的提交,将相关的参数提交到远端的一个存储上,Flink 运行的时候先进行下载,然后通过找到镜像里的 Main Jar 的方式找到一个本地的 Jar 包进行执行,从而解决无法引用外部资源的问题。
-
运维增强
-
日志:基于 Log4j 的 Logappender 实现,相当于在使用 Logappender 时将 Flink 的所有日志输出到远端的日志系统中,用户就无需登录到 Pod 或者用 Flink UI 来看日志了。
-
指标收集:对接 Prometheus。Flink 运维的指标非常多,所以通过对接 Prometheus 的方式,实现将指标推送到远端,自行收集指标的能力。
-
基于 Zeppelin 的 Spark 云原生实践
Spark on K8s 工作原理
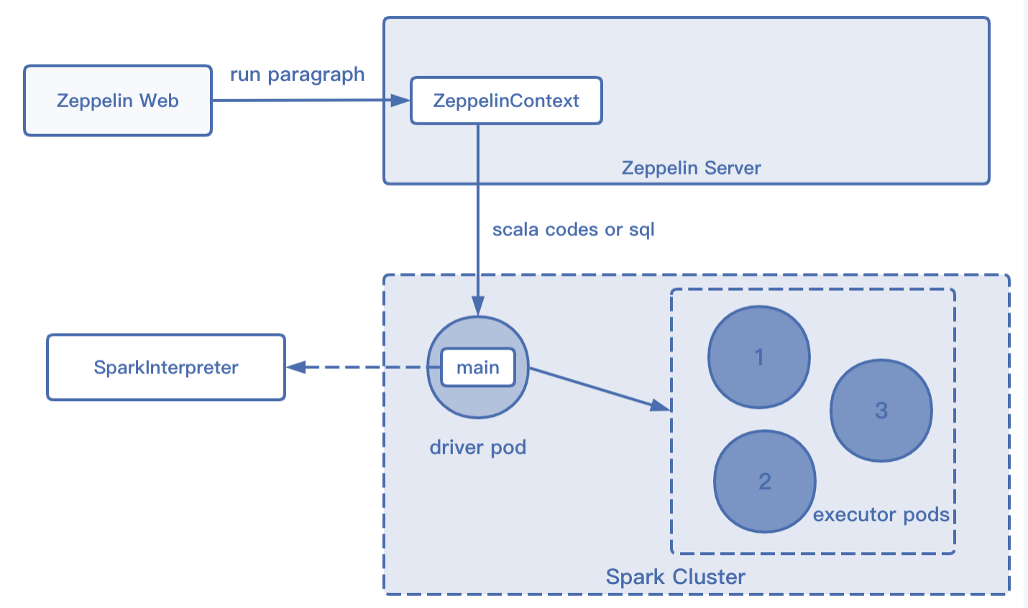
Spark 在 K8s 上的工作原理和 Flink 的 Application 模式类似,用户提交指令给 K8s APIServer 后,创建对应的 Driver Pod 和 ConfigMap。 Driver Pod 运行相应的程序,根据代码需求向 K8s Master 发送请求申请Executor Pod资源。 Executor Pod创建完毕后开始执行任务,执行完毕后最终销毁。
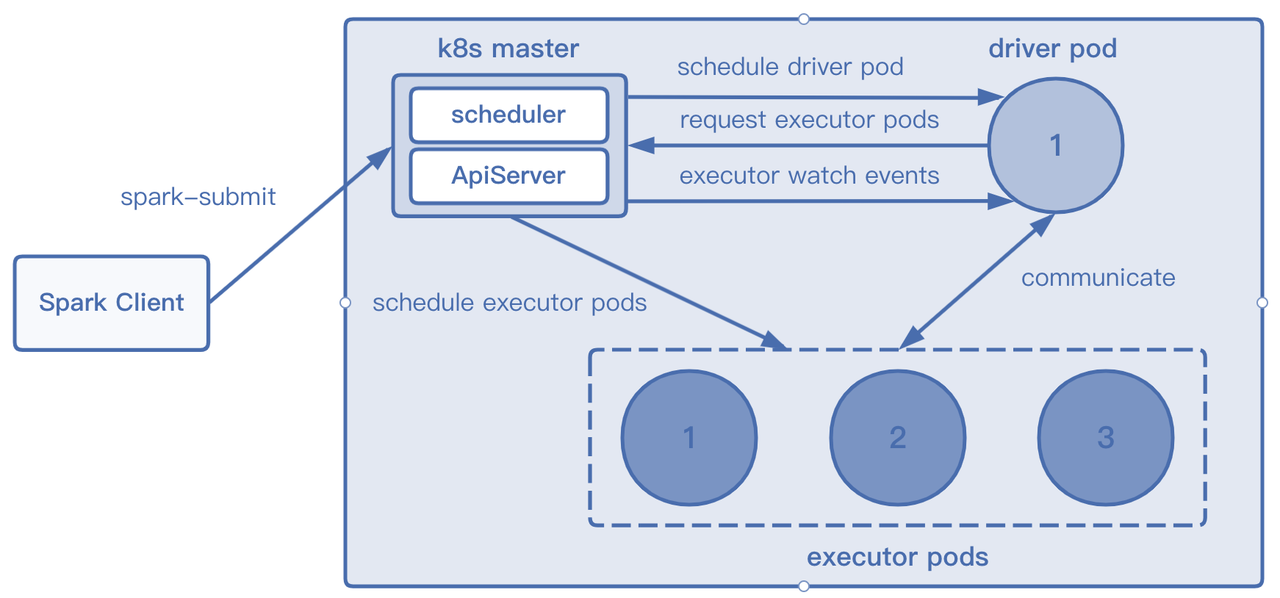
同样 Spark on Zeppelin 的工作也都是基于解释器实现的。
-
第一种使用 SparkSubmit 解释器,通过命令行执行来实现运行,用户每运行完指令后就会启动一个 Spark 的 Cluster 用来执行任务;
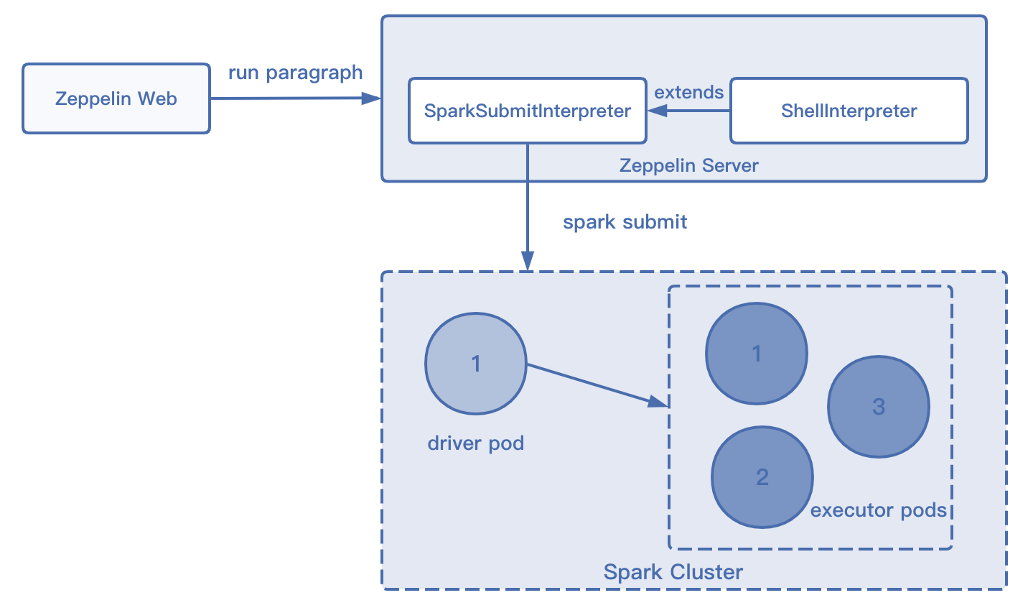
-
第二种解释器也和 Flink 的类似,通过在 Spark Pod 中运行的 Main Jar 发现对应的 Code 从而提交给对应的 Executor Pod 进行执行,执行完成后将结果返回给 Spark 解释器,同样此类解释器也是共用一个 Cluster 进行生命周期的管理。
Spark on Zeppelin 的功能增强
火山引擎同样对 Spark on Zeppelin 进行了功能增强,主要有以下几个方面:
-
支持 K8s N ative 模式:在运行的基础上支持 KV 存储,用 TOS 作为远端 Jar 包或资源的存储;
-
K8s 模式下透出 Spark UI:使用 NodePort / Ingress 实现透出,通过创建 Service 和 Ingress 绑定到对应的 Driver Port 上也可以实现对应资源的销毁;
-
支持 Hive Catalog
-
垃圾回收:Zeppelin 原生的 Spark 会把所有创建的 Owner Reference 设置为 Zeppelin Server。而 Zeppelin Server 会一直运行导致所有的资源都无法被删除,将 Spark 相关 Job 的 OwnerReference 修改为 Driver Pod 的形式就可以实现对资源的销毁,从而提高资源使用的利用率。
目前,火山引擎流式计算 Flink 版、火山引擎批式计算 Spark 版已正式上线公测,支持云中立模式,支持公共云、混合云及多云部署,全面贴合企业上云策略,欢迎技术交流或申请试用。
更多技术干货,欢迎搜索关注「字节跳动云原生计算」公众号!
|








- 上一条: Dive into TensorFlow系列(1)-静态图运行原理 2022-11-11
- 下一条: 基于 Zeppelin 的 Flink/Spark 云原生实践 2022-11-11
相关文章
- 袋鼠云数栈基于CBO在Spark SQL优化上的探索 2022-06-10
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化 2022-03-21
- 【Quarkus技术系列】「云原生架构体系」打造基于Quarkus的云原生微服务框架实践 2021-10-24
- Firestorm - 腾讯自研Remote Shuffle Service在Spark云原生场景的实践 2021-11-19
- 字节跳动 Flink 基于 Slot 的资源管理实践 2022-09-05
热度排行

