到底为什么我们需要 Clickhouse?
Clickhouse 是现在最流行的 OLAP 数据库之一,虽然名声如雷贯耳,但在我们心目中总有一个疑问,到底为什么我们需要 Clickhouse,是哪些优点让字节、腾讯这些大公司都选择它作为最推荐的 OLAP 数据库,这篇文章将试图带我们找到答案。
一、什么是 Clickhouse?
Clickhouse 是一个开源使用列式存储的 OLAP 数据库,最初由 Yandex 公司开发,现在从 Yandex 拆分出来并成立了独立的 Clickhouse Inc,其功能类似于 Google Analytics。它的目标是处理数万亿行和数 PB 的数据,并快速执行分析查询。
Clickhouse 等 OLAP 数据库通常用于回答诸如"昨天有多少人访问掘金?昨天有多少人访问 CSDN"之类的业务问题。如果使用传统的 OLTP 数据库来处理,可能需要几分钟甚至几个小时。而如果使用 OLAP 数据库,我们几毫秒就得到结果。OLTP 和 OLAP 之间的巨大速度差异是因为使用的底层存储结构不同,OLTP 数据库通常使用行式存储,OLAP 则通常使用列式存储。
什么是列式存储?
假设我们有如下数据:
| 时间戳 | 域名 | 访问 |
|---|---|---|
| 2022-10-26 12:00 | www.ifb.me | 20 |
| 2022-10-26 12:00 | www.fflow.link | 300 |
| 2022-10-26 12:01 | www.ifb.me | 15 |
| 2022-10-26 12:02 | blog.fflow.link | 21 |
如果我们使用 PostgreSQL 和 MySQL 等的 OLTP 数据库,数据将按如下结构进行存储:
第 1 行 -> 2022-10-26 12:00,www.ifb.me,20;
第 2 行 -> 2022-10-26 12:00,www.fflow.link,300;
第 3 行-> 2022-10-26 12:01,www.ifb.me,15;
第 4 行-> 2022-10-26 12:02,blog.fflow.link,21;
一行中的每一列的数据会在磁盘中相邻写入,这样的存储结构会让单行的数据查找、更新和删除操作很快。但是当我们需要进行聚合的时候,比如统计 www.ifb.me 的访问次数,数据库则需要逐行读取数据并统计求和。这样不仅带来了大量的 IO 操作,而且处理的时候也会比较长。
但是如果我们使用列式存储的数据库,数据将按如下结构进行存储:
时间戳列 -> 2022-10-26 12:00:001,2022-10-26 12:00:002,2022-10-26 12:01:003,2022-10-26 12:02:004;
访问域名列-> www.ifb.me:001,www.fflow.link:002,www.ifb.me:003,blog.fflow.link:004;
访问次数列 -> 20:001,300:002,15:003,21:004;
列式存储中的每一行数据都是分开存储的。如果需要统计 www.ifb.me 的访问次数,数据库首先需要从访问域名列中找到 www.ifb.me 对应的 id,然后再对 id 的访问次数列求和。这样数据库就不需要再跨很多磁盘页来检索数据,因为它只需要先获取满足条件的列数据。这就是为什么使用列式存储的数据库进行分析查询,比使用行式存储的数据库快很多。
二、为什么 Clickhouse 改变了游戏规则
Clickhouse 或 OLAP 数据库的主要用途包括但不限于:
- 数据分析
- 数据挖掘
- 商业智能
- 日志分析
Clickhouse 是一个支持多种数据存储引擎的数据库,几乎支持将任何数据源导入到 Clickhouse 数据库中,并支持快速灵活的下钻分析。比如,现在微信就使用 Clickhouse 来存储日志数据,因为日志里面通常有非常多的重复值,使用 Clickhouse 可以得到非常高的压缩率,减少日志占用的存储空间;Cloudflare、Mux、Plausible、GraphCDN 和 Panelbear 等公司则使用 Clickhouse 存储流量数据,并在其仪表板中向用户呈现相关报告;而 Percona 正在使用 Clickhouse 来存储和分析数据库性能指标。
三、什么场景不适合 Clickhouse
Clickhouse 并不能取代关系型数据,也不是为了处理事务性数据而开发的,Clickhouse 更多的是作为 OLTP 补充,方便用来进行数据分析。如果需要对数据进行更新和删除,或者需要进行多表关联,那么我们通常不推荐使用 Clickhouse。
另外也要避免把 Clickhouse 用作 OLTP 数据库的副本。当然从技术上讲,我们可以把 OLTP 数据库的数据通过事件的方式同步到 Clickhouse,但最好的做法是使用 Clickhouse 作为数据的唯一真实来源,而不是作为 OLTP 数据库的镜像。
四、为什么 MySQL 不使用列式存储?
- 分页友好,且可以将数据都放到叶子节点,可以兼顾 Scan 与 Lookup
- 数据更新方便 (这对列式存储是硬伤,所以
很多 OLAP 数据库不支持更新,或者用复杂的方式支持更新) - 事务型数据库的主要性能瓶颈是 I/O,更新一行数据,列式存储需要进行多次 I/O,但是行式少数几次就够了。
五、Clickhouse 的优点
开源社区很活跃
在评估开源软件的时候,我们必须考虑它的社区是否活跃,如果我们使用了一个开源软件,但是这个开源软件突然就不维护了就会让人很尴尬,比如之前阿里的 Dubbo。当然这种情况在开源的世界里面并不少见,我们需要尽可能的使用有大公司/组织背书的开源软件。如果我们选择使用 Clickhouse,我们就不需要担心这些。不管是国内的字节、腾讯、阿里,还是国外的 Cloudflare、eBay、Spotify,这些业界知名的公司都在使用 Clickhouse。
飞快的查询速度
根据 Marko Medojevic 的报告,如果对 11M 的数据集进行分析查询,Clickhouse 的查询速度会比 MySQL 快约 260 倍。然而,也许这种比较并不公平,因为 MySQL 毕竟是 OLTP 数据库,但这也从侧面反应了 OLAP 数据库的优势所在。
Clickhouse 实现的极致性能来自其独特的数据库引擎 MergeTree,而且 Clickhouse 也比较趋向于使用通用的硬件来做查询性能优化。
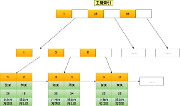
小索引(稀疏索引)
大家都知道在数据库中快速查找数据的关键是索引。索引最好保存在内存中以便快速访问。在 OLTP 数据库中,索引通常使用 B+ 树来进行存储,比如下图。
这适用于 OLTP 数据库,因为主键本质上是必不可少的。在 OLTP 数据库中,通常是通过主键 ID 查询数据库,例如 SELECT username, email FROM user WHERE id = 10086 或类似 UPDATE user SET email = "hunterzhang86@gmail.com" WHERE id = 10086 等查询。但是,一旦数据增长到数十亿行并且索引在内存中放不下的时候,这种类型的索引局限性就非常明显。
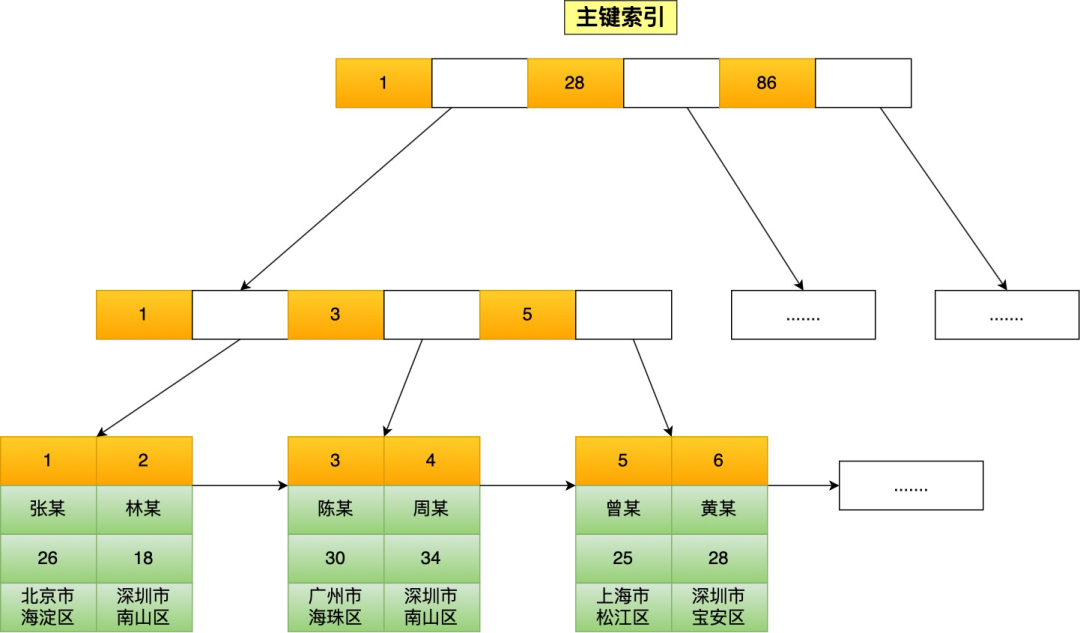
而在 Clickhouse 中,索引的构造如下图所示。

Clickhouse 使用的索引 和 Kafka 类似,其仅存储索引数据的子集。这样的好处是索引相对较小,就算是很大的数据量,其索引在内存里面也放得下。我们想象一下如果要使用 SELECT SUM(visit) FROM visit WHERE date BETWEEN '2022-10-01' AND '2022-10-31' 进行查询,数据库使用稀疏索引的方式就很合适,因为我们的查询条件是日期范围,而不是主键 ID。这就是为什么稀疏索引在 OLAP 数据库中经常使用的原因。
数据压缩
由于 Clickhouse 的数据是按列而不是按行存储的,所以它能够比行式数据库能更好地压缩数据。 有数据表明,同样的数据放在 Clickhouse,相比于放在 PostgreSQL 所需的磁盘空间减少了 70%。另外在 Clickhouse 中,可以和方便的指定列的数据压缩算法和压缩级别。
数据 TTL
通常我们不建议无限制的存储数据,这样会浪费非常多的磁盘空间。一般情况下,设置一个合适的数据保留时间是比较好的选择。在 Clickhouse 中,可以通过在创建表时设置数据的 TTL 轻松做到这一点。
适配多种语言
Clickhouse 的社区非常活跃,现在就已经支持 Java、Go、Python 等流行语言的 SDK,如果使用 Perl 小众语言,Clickhouse 也支持通过 HTTP 接口操作访问数据。
水平可扩展和高可用
Clickhouse 在构建时就考虑了水平可扩展性和高可用性。我们可以将数据分片到多个节点并将数据复制到另一组服务器中。当然水平可扩展性和高可用性功能会带来额外的复杂度,如果我们使用 Kubernetes 部署 Clickhouse,可以使用 Clickhouse Kubernetes Operator 进行配置。
六、小结
实话说,现在如果有数据分析的场景,我第一个想到的方案就是使用 Clickhouse,如果再结合一下 Superset 等开源 BI 工具,我们就可以非常快速的搭建起来轻量的数据分析系统,这样对于大多数中小公司来说就已经完全够用了。最后,如果想快速试用一下,推荐试用 docker 进行安装。
$ docker run -d --name clickhouse-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 yandex/clickhouse-server\
$ docker exec -it clickhouse-server clickhouse-client
本文亦通过 NoOne's Blog 发表,更多分享请关注公众号 NoOneNoOne

|








- 上一条: Arctic 基于 Hive 的流批一体实践 2022-10-26
- 下一条: 到底为什么我们需要 Clickhouse? 2022-10-26
- ClickHouse与Elasticsearch压测实践 2022-08-29
- ClickHouse与Elasticsearch压测实践 2022-08-29
- UniqueMergeTree:支持实时更新删除的 ClickHouse 表引擎 2022-05-30
- 2021年ClickHouse最王炸功能来袭,性能轻松提升40倍 2021-09-24
- ReplacingMergeTree:实现Clickhouse数据更新 2021-11-05