一文读懂:开源大数据调度系统Taier1.2版本新增的「工作流」到底是什么?
一、什么是工作流?
在阐述什么是工作流之前,先说一下工作流和普通任务的区别,在于依赖视图。
普通任务本身他只会有自己的dag图,依赖视图是无边界的,不可控的,而工作流则是把整个工作流都展示出来,是有边界的,可控的,这是工作流的优势。下面为大家介绍工作流的相关功能:
01 工作流—功能介绍
● 虚拟节点
虚拟节点,它是不产生任何数据的空跑节点(即调度到该节点时,系统直接返回成功,不会真正执行、不会占用资源或阻塞下游节点运行),比如说任务并行执行,那么就会用到虚拟节点。
● 周期生成
指调度系统按照调度配置自动定时运行的任务。

● 补数据运行
当业务变更,可以使用补数据功能。如修改了某个任务的代码,可将本月的数据按照新的代码重新跑一遍,立即生成所需数据。
● 调度属性
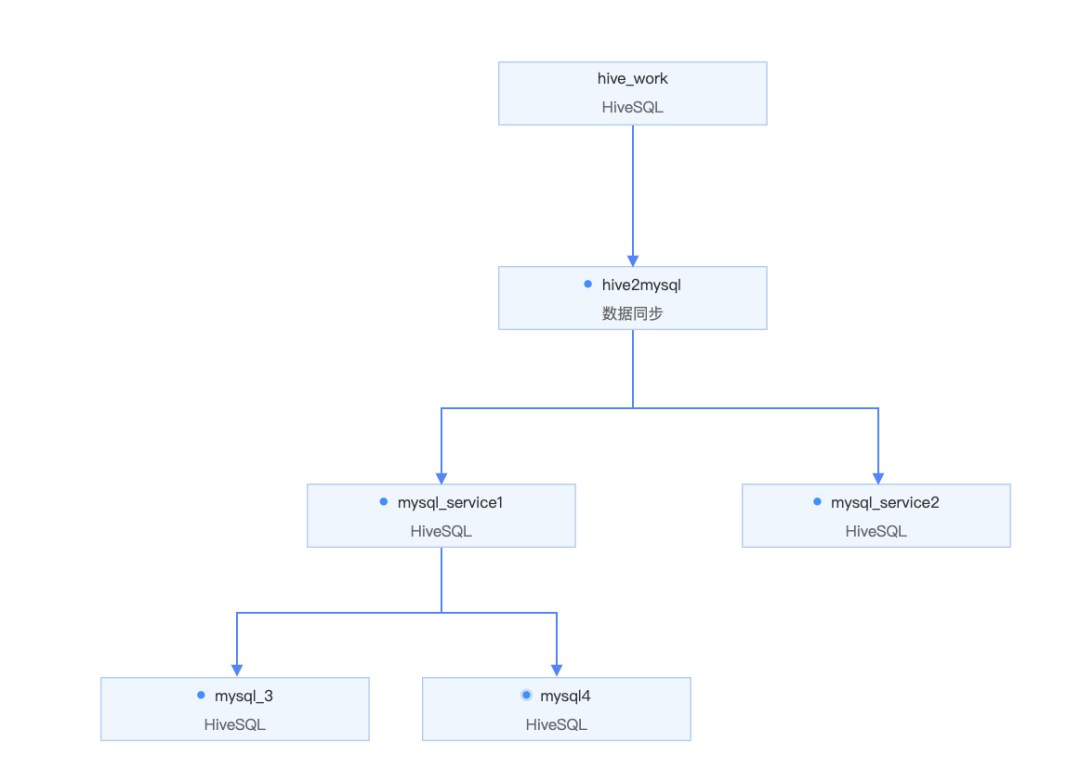
工作流中的子任务依赖于父任务的周期调度属性,父任务修改后,子任务同步修改,以工作流的周期调度属性作为各个子节点的周期调度时间。 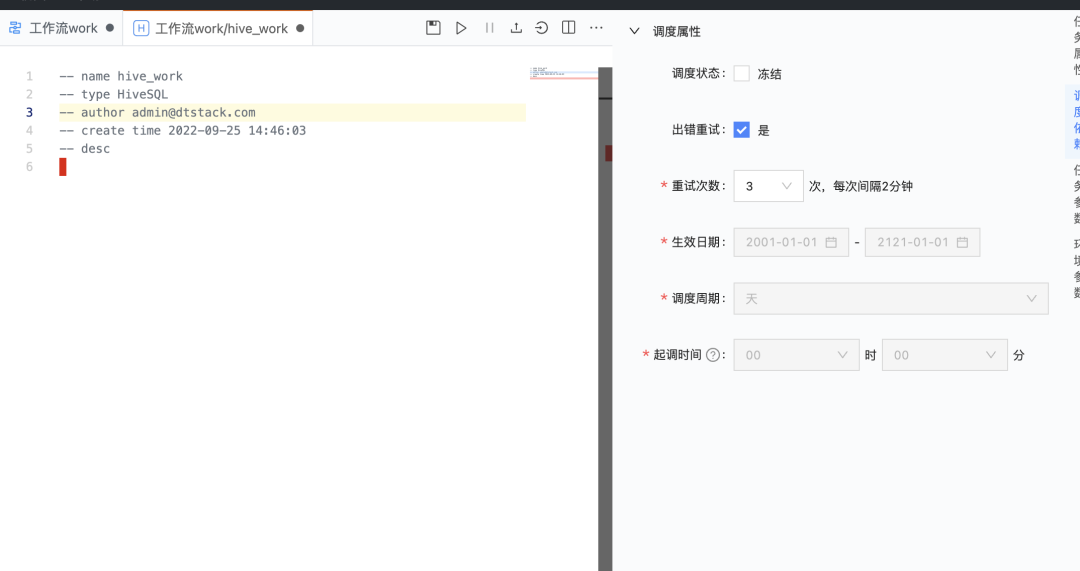
● 工作流所在目录
修改工作流目录同步修改工作流下的子任务目录。 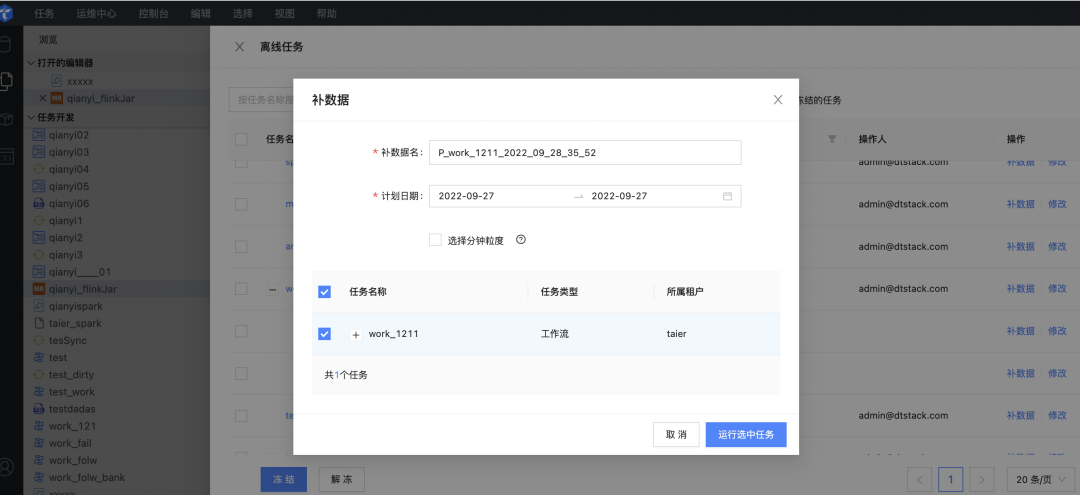
02 工作流—依赖成环
具体实现:
任务完成依赖的关系,key为当前节点,value为该节点的所有父节点Map < long list> nodeMap。
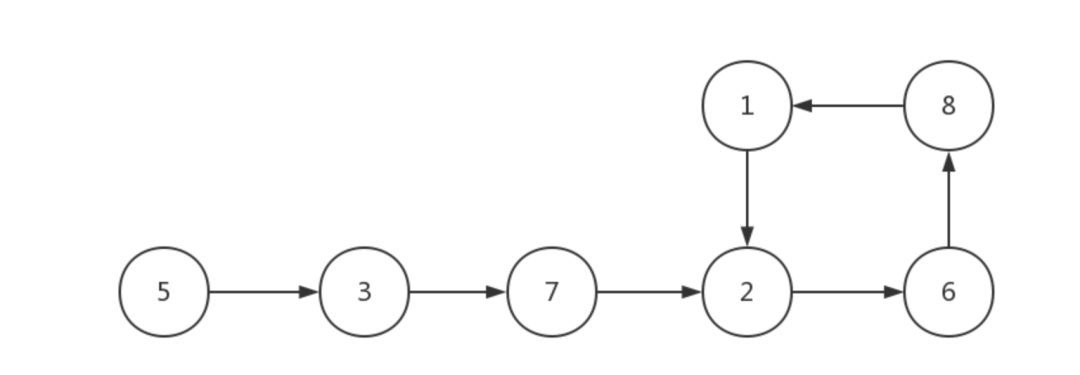
遍历nodeMap,以此遍历单集合中的每一个节点。每遍历一个新节点,就从头检查新节点之前的所有节点,用新节点和此节点之前所有节点依次做比较。如果发现新节点和之前的某个节点相同,则说明该节点被遍历过两次,链表有环。如果之前的所有节点中不存在与新节点相同的节点,就继续遍历下一个新节点,继续重复刚才的操作。
二、Taier工作流周期实例运行
了解完工作流的功能介绍后,我们来为大家分享Taier工作流周期实例运行:
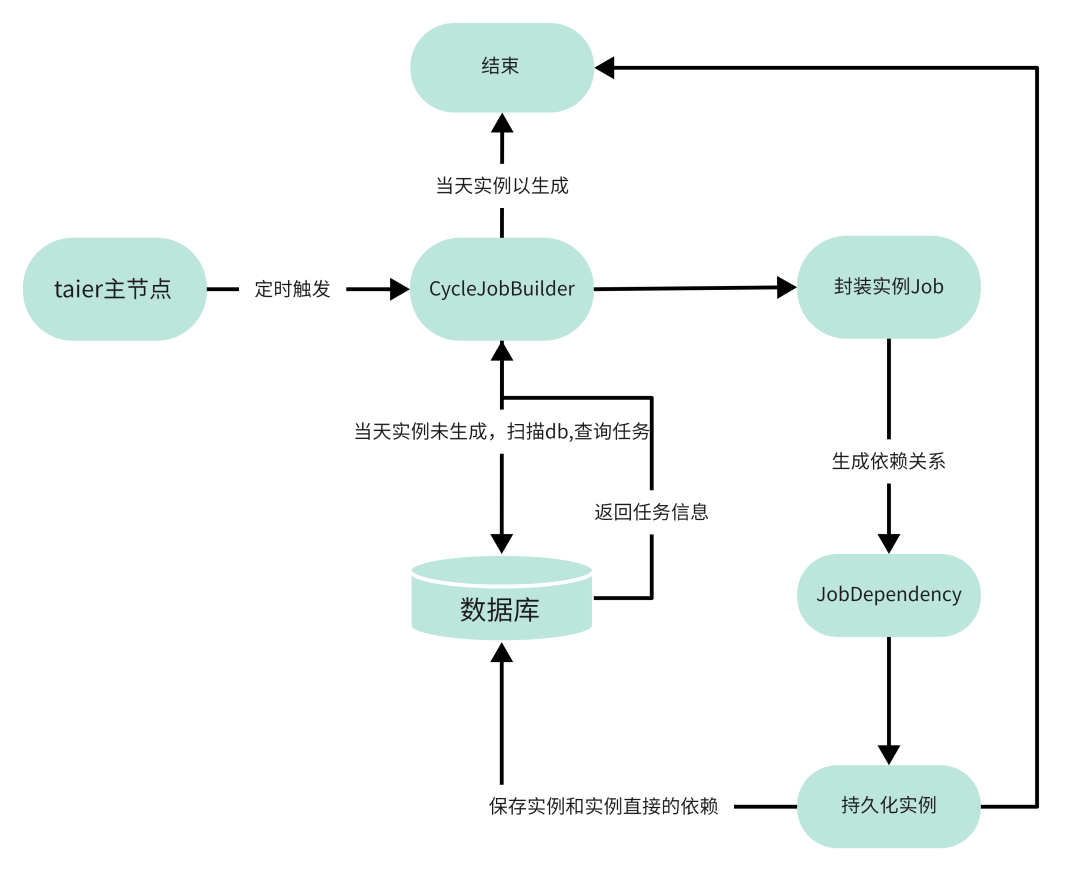
01 Taier—周期实例生成
Taier主节点在启动的时候,会开启一个定时器,定时器会不停的去判断当日的实例是否已经生成。如果没有生成,就会触发事件给CycleJobBuilder生成实例,再通过JobDependency封装实例之间的依赖关系。
● CycleJobBuilder
用于生成周期实例。扫描数据库任务表并且获取zk上所有的Taier节点,把封装后的实例分配到每一台Taier节点上。
● JobDependency
用于生成job之间的依赖关系。
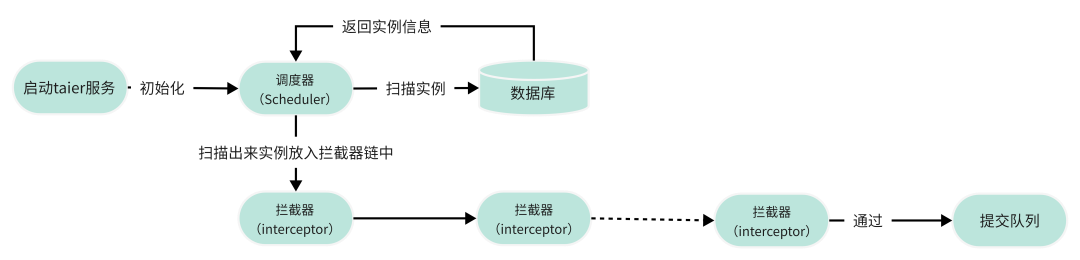
02 Taier—调度流程
在启动Taier服务时,会启动配置的所有调度器,并且开始扫描实例,并提交。
03 Taier—工作流任务状态修改逻辑
任务提交拦截器处理:
1、工作流下无子任务更新为完成状态
2、工作流下任务都是完成状态,任务提交队列可以移除
3、同时更新工作流engine_job状态,工作流只有四种状态,成功/失败/取消/提交中:
(1) 所有子任务状态为运行成功时,工作流状态更新为成功
(2) 工作流状态根据子任务的运行状态来确定,失败状态存在优先级:运行失败>提交失败>上游失败
a.子任务存在运行失败时,工作流状态更新为运行失败
b.子任务不存在运行失败时,存在提交失败,工作流状态更新为提交失败
c.子任务不存在运行失败时,不存在提交失败,存在上游失败时,工作流状态更新为上游失败
(3) 子任务存在取消状态时,工作流状态更新为取消
(4) 若子任务中同时存在运行失败或取消状态,工作流状态更新为失败状态
(5) 其他工作流更新为运行中状态
三、Taier1.3即将上线功能
新增功能
· ChunJun的向导模式数据源增强 hive1、hive2、hive3、sparkThrift、oracle、mysql、postgresql、sqlserver 、es7
· flink on standalone、python.shell、spark jar 、pyspark支持
· 自定义任务类型 web界面配置抽取
· windows开发环境适配
袋鼠云开源框架钉钉技术交流群(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack/Taier
|








- 上一条: 最近迷上了源码,Tomcat源码,看我这篇就够了 2022-10-18
- 下一条: 一文读懂:开源大数据调度系统Taier1.2版本新增的「工作流」到底是什么? 2022-10-19
- 当我们在聊「开源大数据调度系统Taier」的数据开发功能时,到底在讨论什么? 2022-07-21
- 开源项目丨Taier 1.1版本正式发布,新增功能一览为快 2022-05-10
- 各行各业都在关注的“密评”到底是啥?一文带你读懂! 2022-09-22
- 基于开源大数据调度系统Taier的Web前端架构选型及技术实践 2022-06-20
- 深入浅出聊Taier—大数据分布式可视化DAG任务调度系统 2022-04-20