打造通用缓存层:字节跳动 Flink StateBackend 性能提升之路
内容简介:StateBackend 作为 Flink 向上提供 State 能力的基石,其性能会严重影响任务的吞吐。本次分享主要介绍在字节跳动内部通过为 StateBackend 提供通用缓存层,来提高性能的相关优化。
作者|字节跳动基础架构研发工程师-李明
一、相关背景
StateBackend 是 Flink 向上提供 State 能力的基石,其性能会严重影响任务的吞吐。目前 Flink 提供的生产可用的 Statebackend 主要有两类,一类是 FsStateBackend,另一类是 RocksDBStateBackend。他们的基本原理都是提供一个 State API 给用户使用,底层会根据 StateBackend 类型选用不同的存储来存储数据。
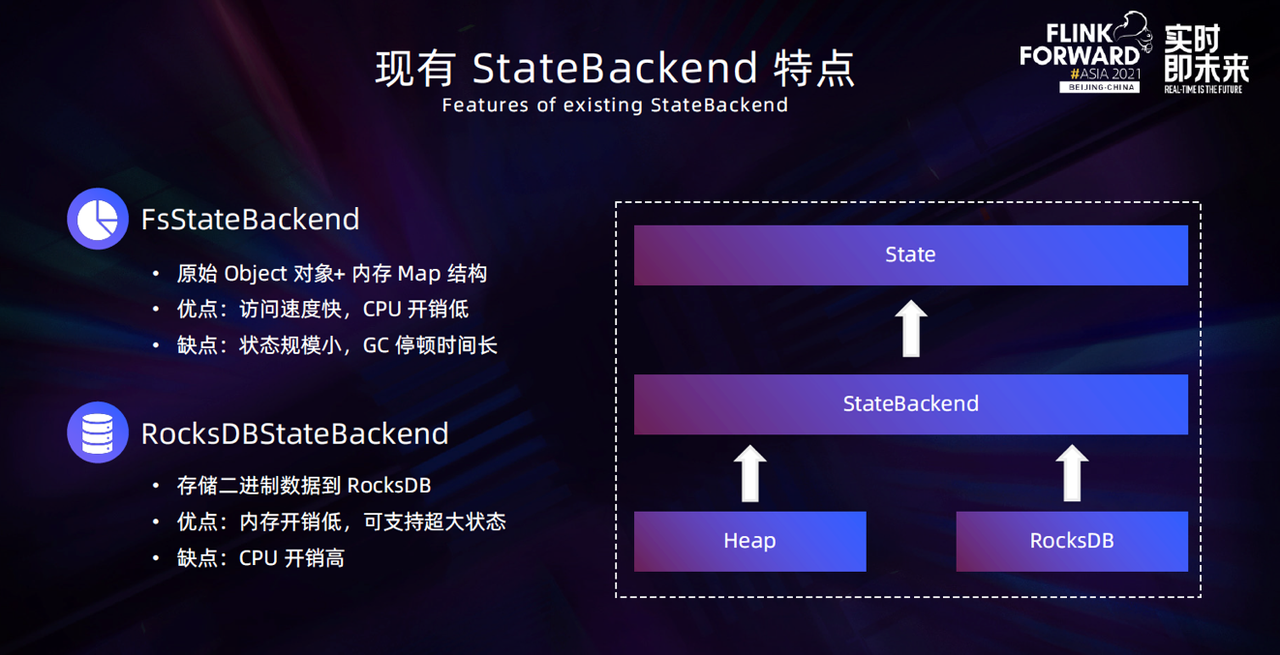
FsStateBackend 底层实现是在内存中通过 Map 的数据结构来存储数据,把原始的数据对象直接存储到内存中。这种 StateBackend 的优点是访问速度特别快,所有操作都是在内存中进行,基本没有额外的 CPU 开销。缺点是随着状态规模的增长,JVM 的 GC 停顿时间也会越来越长,同时状态规模会受到内存的限制。
RocksDBStateBackend 底层选用了 RocksDB 来存储数据,存储的状态规模理论上受限于磁盘,序列化后的结果也会比以 Object 的形式存在内存中要小,因此支撑的状态规模比 FsStateBackend大。另外,RocksDBStateBackend 在 JVM 的 Heap 中没有额外的状态数据存储,对应的 GC 压力非常低。但是都是以二进制的形式与 RocksDBStateBackend 交互,这意味着每一次 State 访问都需要将数据进行序列化/反序列化,会带来一些额外的 CPU 开销。

我们在线上使用这两种 StateBackend 也遇到了不少痛点:
- 线上 SQL 作业的状态相对比较小,因此会默认配置使用 FsStateBackend 。但是随着状态的规模提升,GC 的停顿时间会越来越长,业务开始对这种停顿产生感知。
- 在单 Task 的状态比较大时,一般推荐使用 RocksDBStateBackend,由于 State 操作都是随机 IO 类型,在非 SSD 机器上的访问性能比较差,并且在访问过程中存在额外的序列化和反序列化开销, CPU 的使用量也会明显上升,实际使用的资源成本增加了。
- 业务在 StateBackend 的选型上比较困难。业务很难预估未来任务状态规模会有多大,如果发现状态规模比较大了,需要一些额外的运维操作进行 StateBackend 切换,比如需要制作一个 Savepoint,再从 Savepoint 去进行恢复,这会带来额外的运维工作。

因此我们思考是否可以将 FsStateBackend CPU 开销低和 RocksDBStateBackend 容量大的优点结合起来,解决前文提到的痛点。
社区之前提出了 SpillableStateBackend 设计思想,它是一个 Anti-Caching 的架构,通过内存+磁盘进行数据存储,在运行过程中会根据当前的GC情况,以 KeyGroup 的粒度动态地与磁盘上的数据进行交换,来调整内存占用。
当 Task 状态特别大的时候,大部分数据会被交换到磁盘上,访问性能会有较大下降,因此还是以支持小规模状态为主。另一方面,数据交换的粒度是比较粗的,假如单 Task 的 State 是 1G,分配了5个 KeyGroup,平均1个 KeyGroup 大概是 200M,它会以 200M 的粒度去控制内存中需要放入哪些 KeyGroup。而在实际场景中,单 Task 的状态可能会达到 GB 级,State 的访问可能随机到很多 KeyGroup 中。SpillableStateBackend 的设计思想并不能把热点数据充分存储到内存中,因此不适用于我们的场景。
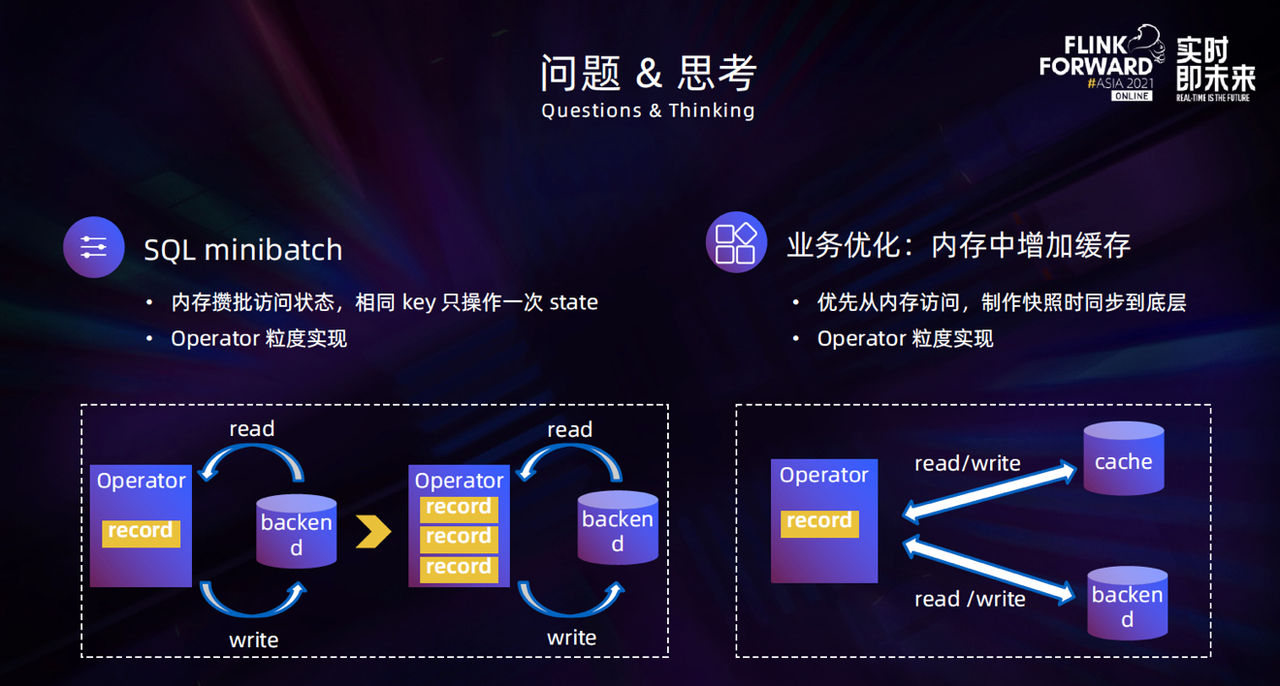
在 Flink SQL 场景中提出了 MiniBatch 的设计思想。 在原来的 SQL 作业流式处理过程中,每来一条数据都会立刻访问 State,然后产生 Read-Update 操作。增加了 MiniBatch 之后,到来的数据并不会立刻访问 State,而是先存储在内存中,当这个 Batch 攒够或者到达设定的等待时间以后,相同 Key 的数据会一起访问 State,操作完成以后再把 Key 对应的 State 写回到 Statebackend,从而减少了 State 访问的次数。MiniBatch 的实现是以 Operator 的粒度进行,如果有新的 Operator 需要利用这个机制,还需要做额外的开发。
此外,业务实践中也在访问 State 上做了一些优化,通过在内存中增加对象缓存,减少序列化和反序列化的开销。实现上也是以 Operator 为粒度,优化后 CPU 使用有了比较明显的下降。
二、优化思路
优化思路
前文提到的优化思路更多的是面向小状态,或者单 Operator 来独立设计的。但我们希望能有一个统一的优化方案,让未来所有 Operator 都能自动使用到这样的优化。
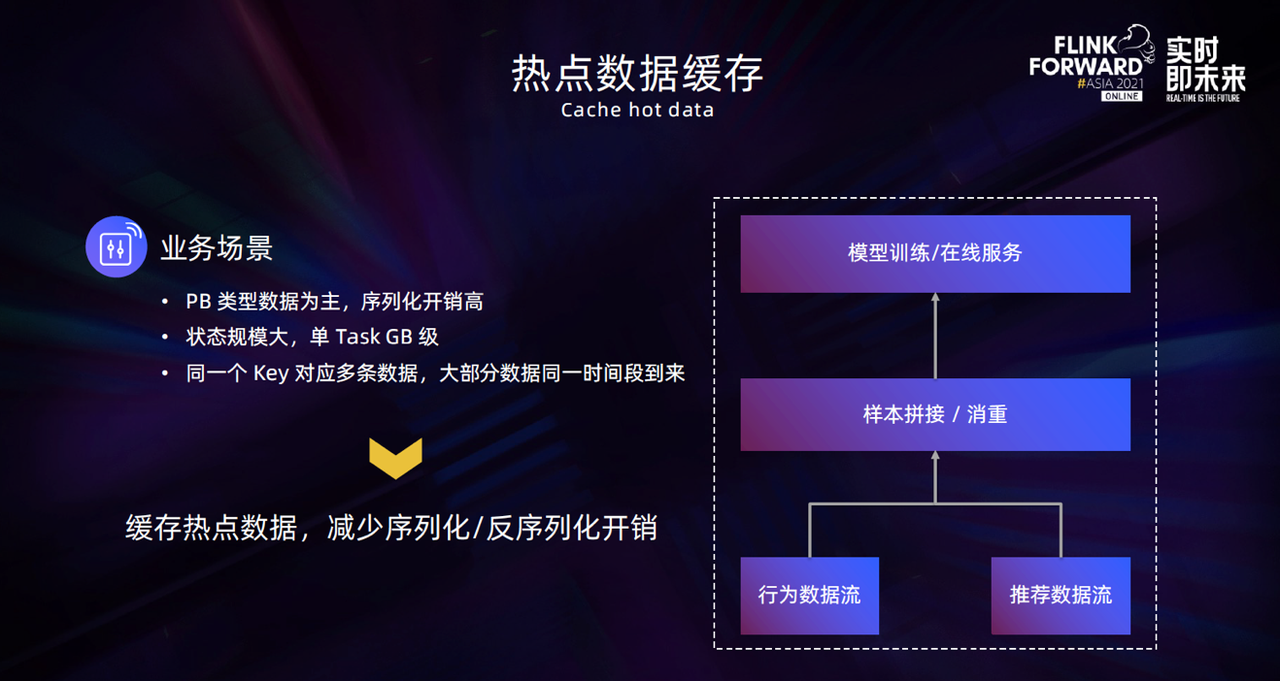
我们的状态使用诉求比较高的核心业务场景主要是面向样本拼接或者流式消重。
在样本拼接场景中 , 推荐系统会向用户推送消息,比如一批好友、视频等,这些数据会作为推荐数据流进行输入。用户看到这些推荐消息后会产生一些操作,比如加好友、查看视频、删除视频等,这些行为会被作为用户的行为数据流输入。对这两条数据流进行数据拼接之后,发送到下游进行模型训练,推荐系统会根据模型训练结果去做一些更优的推荐。
流式消重与样本拼接类似,推荐系统向用户推荐视频文章等,用户可能会观看其中的一部分视频,系统会对已经观看的视频进行消重处理,下次推荐的视频中就不会再有已看过的视频。
在上述两种业务场景中,数据特点比较明显。
- 首先数据结构大部分是 PB 类型,单个 KV 是几十 KB 到上百 KB 的量级,序列化和反序列化的开销也比较高。
- 第二个特点是状态的规模比较大,因为它面向的用户数特别多,State 中一般会存储每一个用户操作的明细数据,单个 Task 的状态规模一般会达到 GB 级。
- 第三个特点是用户的行为数据大部分会在同一个时间段到来。
针对上述特点,我们的优化思路是将同一个 Key 对应多条数据的模式看作对于热点数据的访问,把这些热点数据进行缓存,这样就可以减少序列化和反序列化的开销。

第二个优化思路是从业务运维需求来的。 首先业务希望降低 StateBackend 的选型难度,不希望在未来频繁切换 StateBackend。其次,缓存功能应该是可扩展到多种 StateBackend 的,降低开发成本。
最终我们没有把 StateBackend 的缓存功能设计为一个独立的 StateBackend,而是通过在 StateBackend 和 State API 之间抽象出 Cache Layer,在这一层做了热点数据缓存。 未来底层的 StateBackend 不管怎么变化,对于我们来说都不需要额外的调整。
缓存层架构
下图是优化方案的整体架构,缓存层被拆分成了三部分。
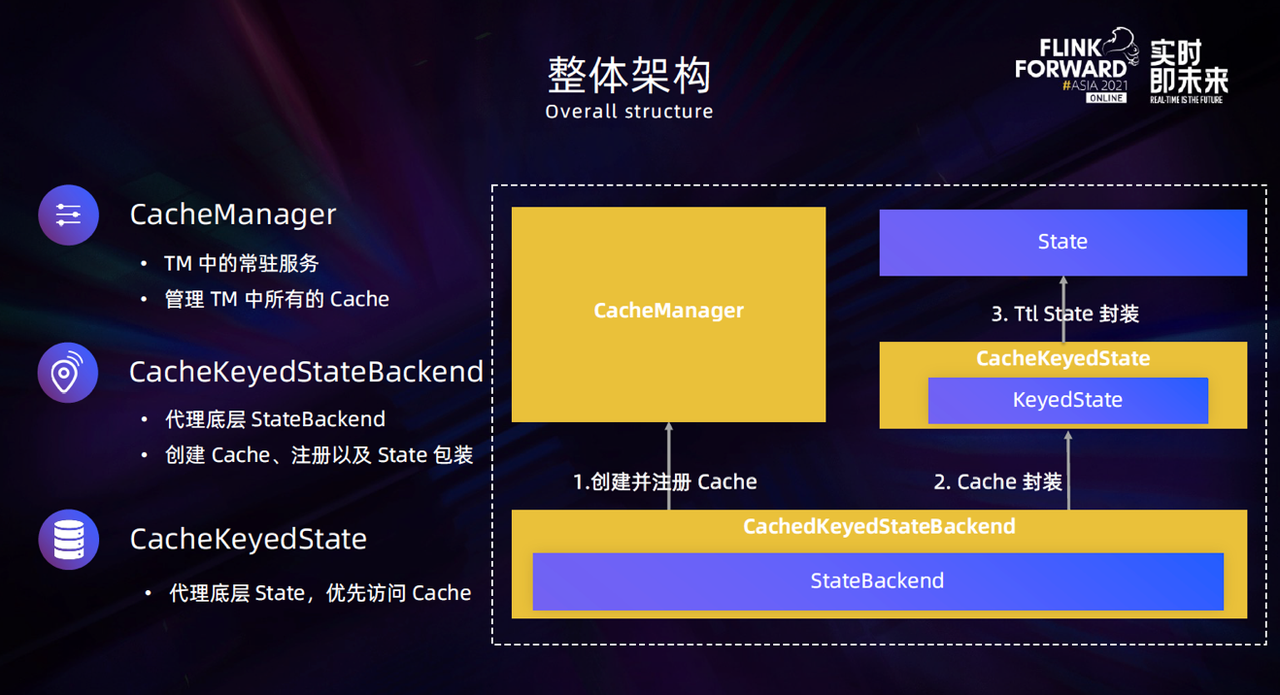
- 第一部分是 CacheManager,它是 TaskManager 中的一个常驻服务,负责管理 TaskManager 中所有 Cache 的注册和释放等操作,同时也会监控 Cache 的使用情况。
- 第二部分是把 StateBackend 封装成了 CacheKeyedStateBackend,这一层封装只是对 StateBackend 的请求做了代理,主要负责底层 StateBackend的State 创建和注册 Cache,将 State 和 Cache 封装为 CacheKeyedState。
- 第三部分是比较重要的 CacheKeyedState,它是面向用户提供的 State 对象,实际是 Cache 和底层 StateBackend 提供的 State 包装,访问的时候会优先操作 Cache 中的数据,如果没有再将底层提供的 State 中的数据加载到 Cache 中,然后进行操作。
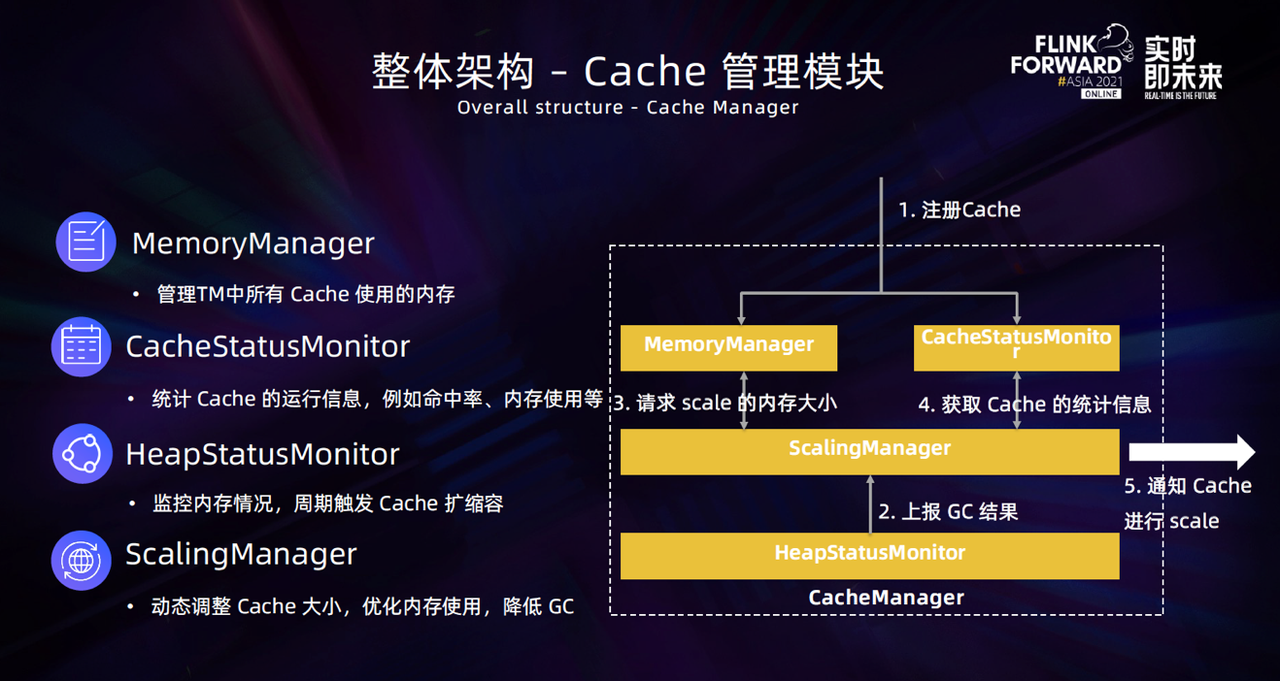
CacheManager 在模块设计上主要参考了 SpillableStateBackend 的设计思路,分为以下4个部分:
- 内存管理模块(MemoryManager):Cache 在初始化或者扩缩容时,都需要向 MemoryManager 发起内存请求。这个模块主要是保证 TM 中的 Cache 内存不会超过配置。
- Cache 监控模块(CacheStatusMonitor):收集 TM 中所有 Cache 的运行情况,比如命中率、内存使用,这些信息会被用来进行动态扩缩容。
- 内存监控模块(HeapStatusManager):周期性地收集 JVM 的内存使用情况,然后触发 Cache 扩缩容。
- 动态扩缩容模块(ScalingManager):负责调整 TM 中所有 Cache 使用的内存大小,以达到优化内存使用、降低 GC 的目的。
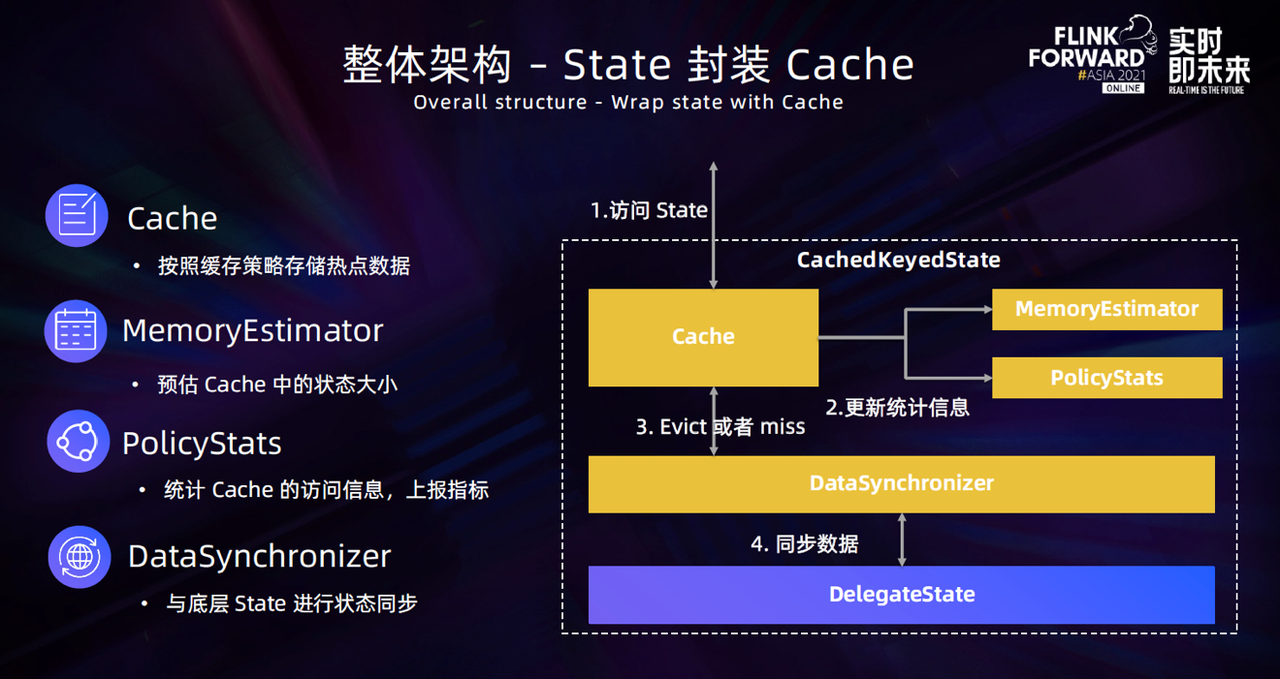
CachedKeyedState 是由 Cache 和 State 封装而成, 它也分为4个部分。
- 第一部分是封装的 Cache,通过把热点数据缓存到 Cache,实现减少序列化/反序列化开销的目的。
- 第二部分是内存预估模块 (MemoryEstimator),根据当前 State 访问使用的 KV 的信息进行状态大小预估,用于估算当前 Cache 占用的内存大小。
- 第三部分是 PolicyStats,用于统计单个 Cache 的访问信息,并作为指标上报。用户可以根据这些指标进行 Cache 运行情况监控,根据实际情况调整 Cache 策略。
- 最后是 DataSynchronizer 模块,负责 Cache 和底层 StateBackend 的数据同步。这里没有由 Cache 直接去操作底层数据,主要是希望可以在这一层做一些优化,比如以 Batch 的模式去写入。
三、难点&方案
在上述方案的实现过程中,我们遇到了不少难点。

第一个难点是如何适配不同的业务场景。 这里的目标是提高缓存命中率,命中率越高优化效果就越好。但是在不同的业务场景中,因为业务数据自身的特点,缓存的策略可能是不同的。
第二个难点是如何正确进行内存管理。 如果内存管理不正确,那么开启缓存后可能会出现内存溢出或内存泄露,导致任务运行的稳定性降低。
第三个难点是如何自动调整 Cache 分配的内存。 如果 Cache 分配的内存是固定的,会导致空间上的浪费;另一方面,用户的使用门槛也会变高,用户很难评估 Cache 的大小。因此这里需要内存使用可以自动调整,降低 JVM 的 GC 压力。
最后一个难点是快照制作。 引入了 Cache 之后的快照制作时间会变长,如何降低快照制作的时间?
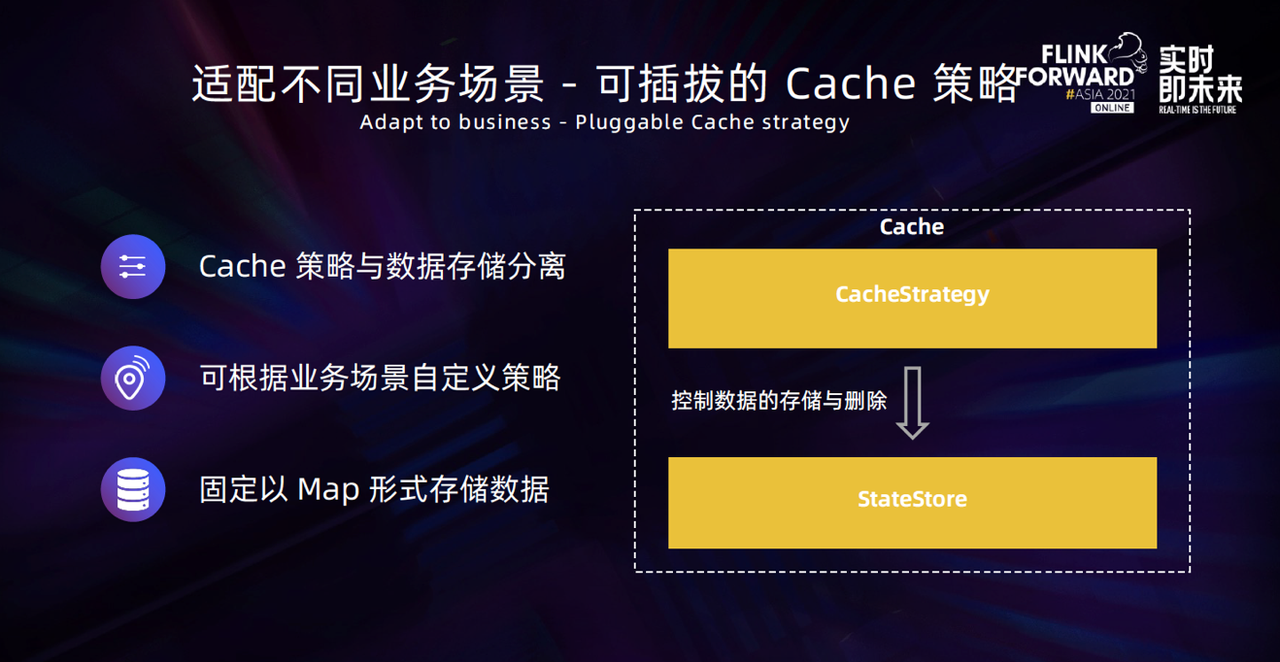
适配不同业务场景
针对适配不同业务场景的问题,我们把 Cache 的实现拆分成了两个部分,将 CacheStrategy 设计成可插拔的缓存策略,将数据存储抽象成一个单独的 StateStore,由 CacheStrategy 来管理 StateStore 中的数据。
StateStore 中的数据是提前内置的数据结构,用户不需要关心这些数据是如何存储和组织,可以根据不同业务场景去选择缓存策略,也支持自定义缓存策略。
内存管理
针对内存管理的问题,主要包含两个方面。
首先是控制 TaskManager 中所有 Cache 使用的内存不超过一个最大配置值, 目前用户在使用这个功能的时候需要给定一个允许 Cache 使用的内存总量最大值,这部分功能由 MemoryManager 来实现。
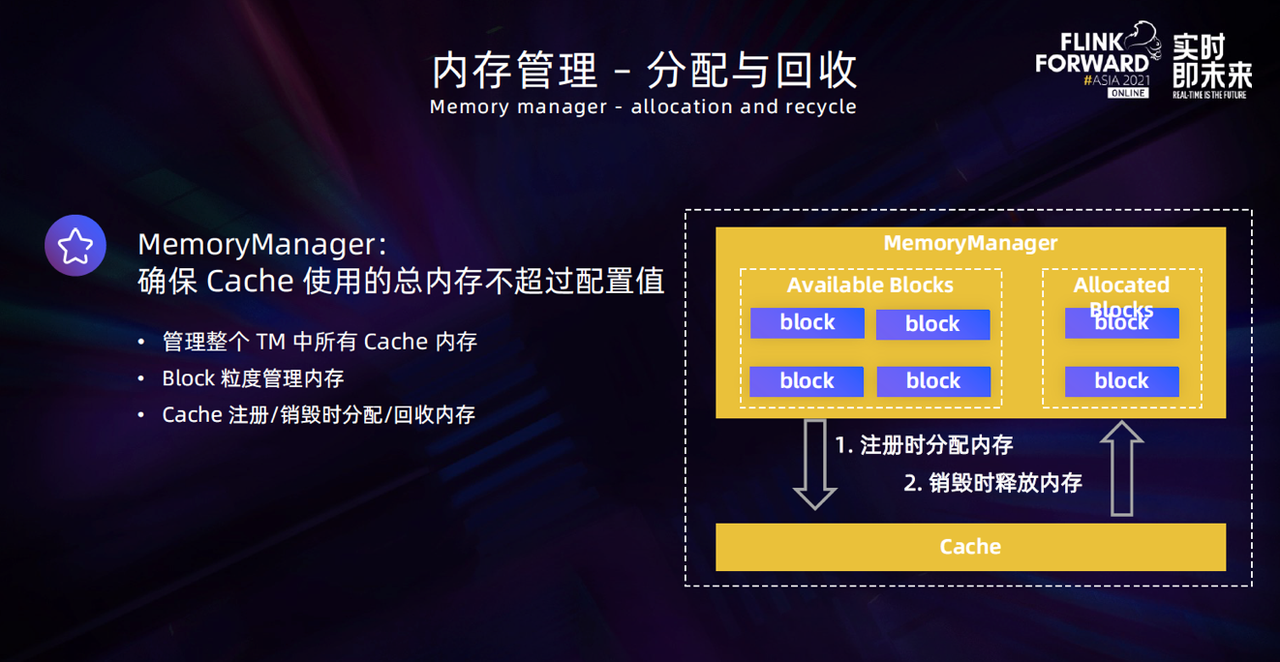
在 MemoryManager 中,为了方便内存管理,内存以 Block 的粒度进行了划分,在 Cache 做扩缩容或进行注册、释放操作的时候,都会通过 MemoryManager 去进行 Cache 的内存分配和回收,最终保证 Cache 使用的总内存不会超过用户配置的最大值。
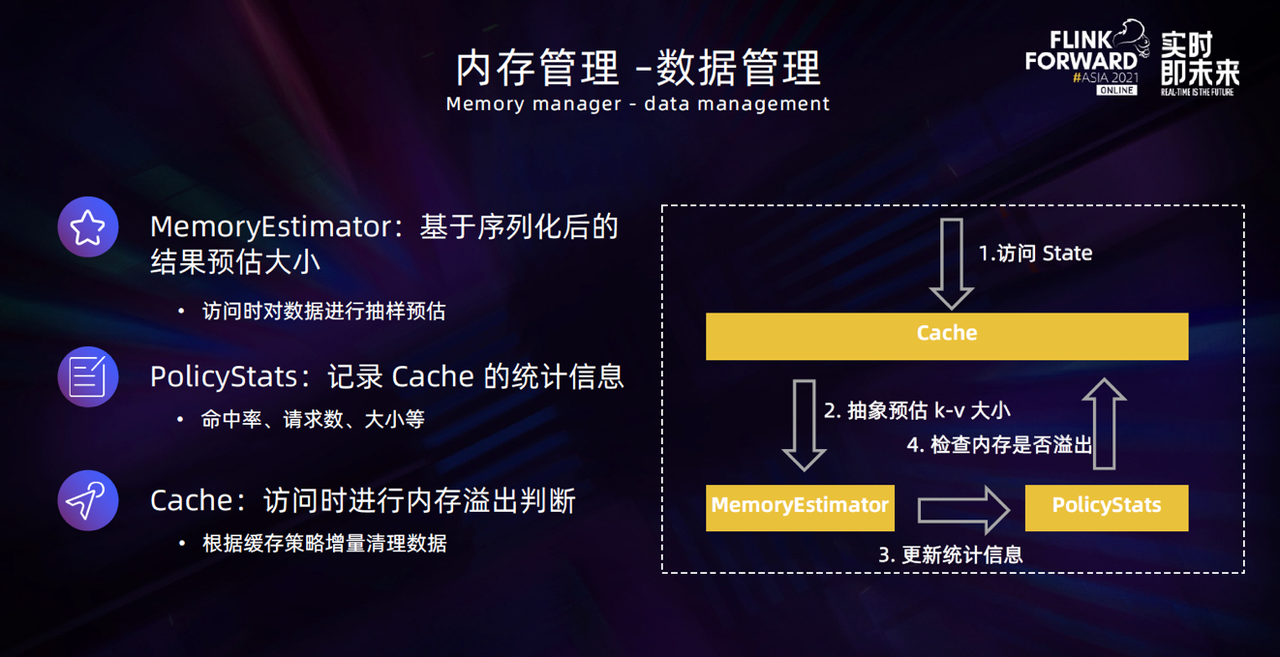
当 TaskManager 中 Cache 使用的总内存有了保证之后,第二部分就是需要保证单个 Cache 使用的内存不会超过分配给它的内存, 这项功能由三个子模块来协同配合完成。
首先,访问 Cache 的 State 时,会通过 MemoryEstimator 模块进行状态大小的抽样预估,主要是根据当前访问的 KV 进行序列化操作,根据序列化结果再结合过去一段时间内访问信息的平均值,作为当前 Cache 中数据的平均大小,并将其上报到 PolicyStats 中。根据 Cache 数据平均大小以及当前 Cache 中的数据条数,就可以衡量出它的内存占用。
访问的过程中会根据当前 Cache 的内存大小做内存检查,如果当前内存已经溢出,则会根据缓存策略去增量清理一些数据。这里的增量清理是指清理时并不会一次性把所有溢出的数据全部清理掉,而是每次只清理 2~3 条数据,因为在 GC 压力很高的场景中下会触发 Cache 缩容来保证的 GC 能够快速恢复正常。如果一次性全部清理掉,服务的停顿时间比较长,业务会产生一些抖动。
动态扩缩容
针对动态调整 Cache 内存使用。我们把它拆分成三个子问题。
第一个问题是什么时候触发动态扩缩容? Cache 使用的是 JVM 的 Heap 内存,扩缩容操作需要根据 JVM 的 Heap 使用情况来决定。因此会根据 JVM 最近一段时间的 GC 情况来衡量 Heap 的内存资源是否比较紧张。

我们抽象出一个 HeapStatusMonitor 模块,它会周期性地收集 JVM 的 GC 信息。启动的时候在 JVM 中注册一个 GcNotificationListener 监听器,JVM 发生 GC 时会通过 Listener 回调给 HeapStatusMonitor。根据回调信息评估本次 GC 的耗时以及回收的内存、GC 后剩余的内存等。有了GC 结果之后,HeapStatusMonitor 会将这些信息汇总并上报给 ScalingManager,由 ScalingManager 来决定是否要进行扩缩容。
目前的判断条件是 GC 频率和 GC 耗时:我们设置了两个阈值,超过阈值则会触发缩容。如果 GC 后剩余的内存比较多,说明大部分都是生命周期比较短的数据,当 GC 后使用的内存低于阈值则进行扩容。判断时会优先判断缩容条件,以降低内存的压力。
第二个问题是本次扩缩容的大小。 主要由 ScalingManager 向 MemoryManager 发起 Scale 内存的请求。MemoryManager 会根据当前 Cache 内存的使用情况,按照一定比例来计算应该扩缩容的 Block数。
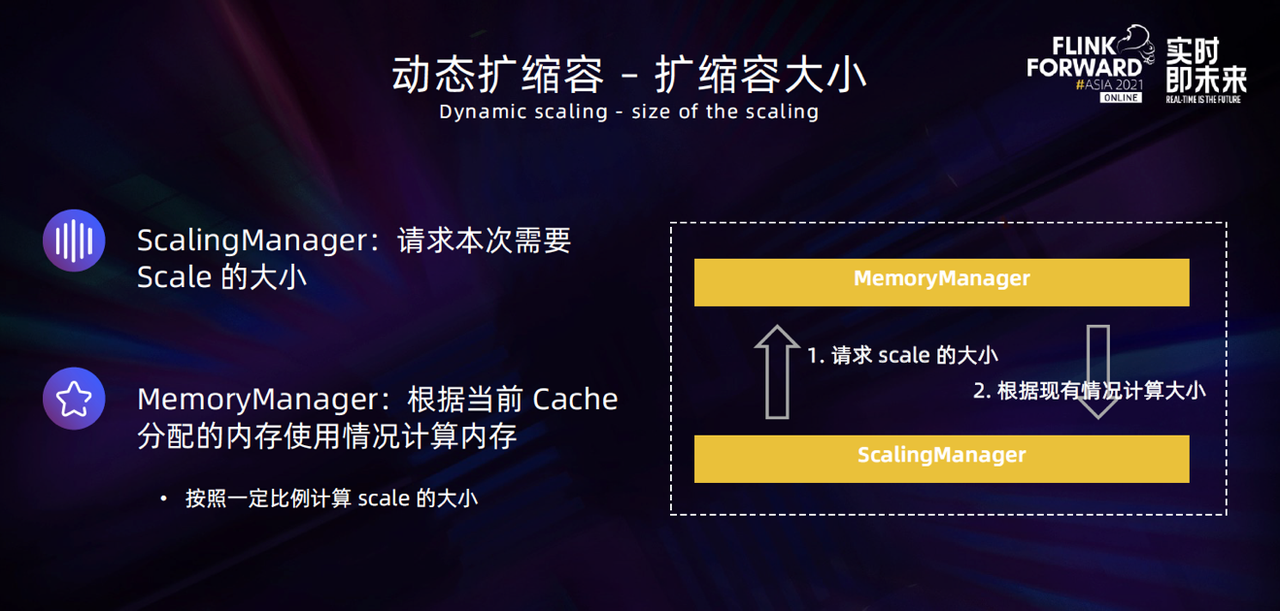
第三个问题是需要选择哪些 Cache 扩缩容。 在实际场景中,由于不同的 State 实例状态大小是不同的,因此我们对 TaskManager 中所有 Cache 进行了权重排序,最终挑选出 2~3 个权重比较高的 Cache 来进行扩缩容。

第一个权重字段是从 Statebackend 中 Load 成功的次数, 这里没有用请求次数的原因主要有两个:第一,在实际的业务场景中可能会经常去访问一些不存在的 State,导致 Cache 的命中率比较低;第二,有一些 State 虽然请求次数特别高,但是 State 的量比较小。而 Load 成功的次数更能表明当前有多少数据存储在外存中并且需要被 Load 到内存。
第二个字段是当前 Cache 分配的内存大小,Cache 越大,越不应该被继续扩容,相反在缩容的时候应该优先挑选它。
此外,我们参考 SpillableStateBackend 的权重计算方式对字段进行了归一化处理, 主要目的是消除量纲的影响。
快照制作
针对快照制作最初有两个实现方案,一是同步阶段 Flush 所有数据到底层的 StateBackend,实现比较简单但同步阶段的耗时会升高;第二个方案是类似于 FsStateBackend 的方式,利用 CopyOnWrite 的 Map 去进行异步快照,实现成本比较高。我们暂时选择了方案一来实现。
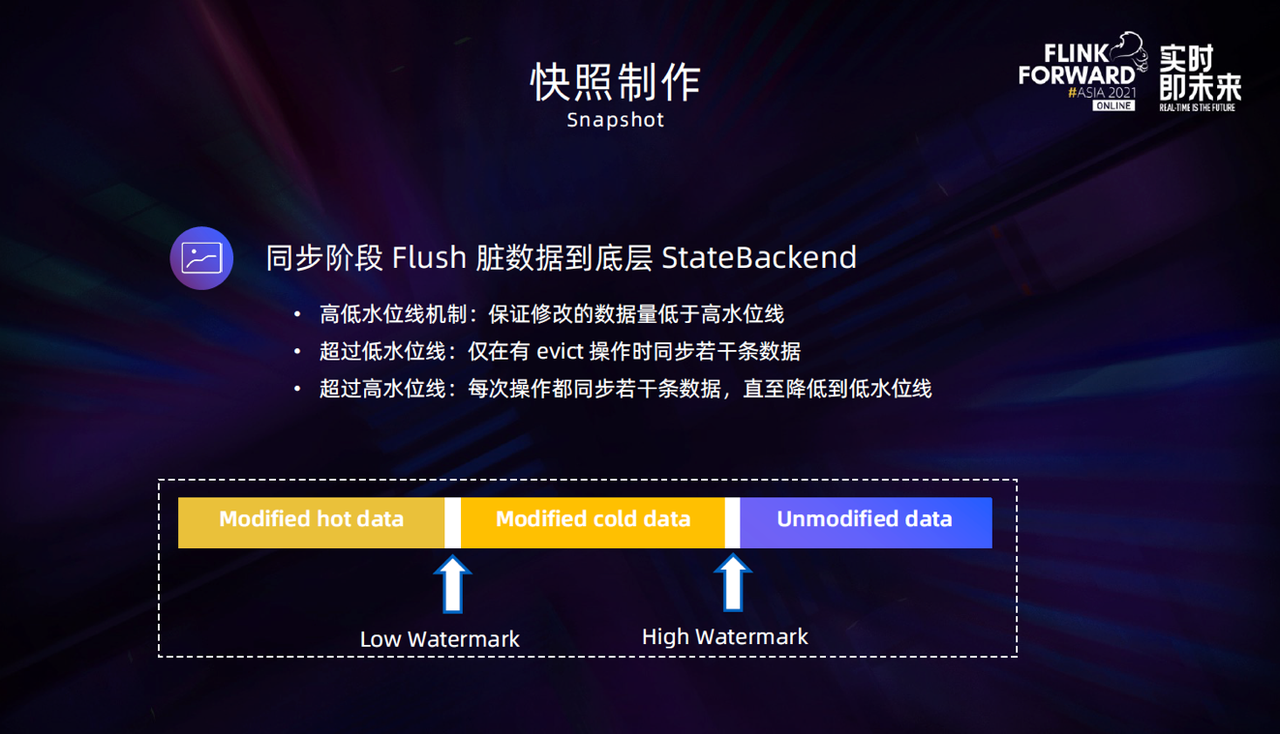
经过线上测试和验证,Cache 在分配 64MB 数据的时候,同步阶段的耗时在一秒钟之内。但是业务会根据实际场景去调整一些配置,比如把 Cache 的内存配置升高,因此我们还设计了一个高低水位线机制 : 把 Cache 中的数据划分成了三个部分,第一部分是经常修改的热点数据,第二部分是发生了修改但相对不那么频繁的数据,最后一部分是经常访问但并未进行修改或修改后已经同步到了底层的数据,并将这三部分的分界线作为高低水位线的划分区间。
当 Cache 中修改的数据量超过低水位线时,只会在 Cache 发生 Evict 事件时去做同步操作,将若干条数据同步到底层的 StateBackend 中;超过高水位线时,意味着当前更新的数据在 Cache 中占比较高,需要保证同步的数据能够快速下降,因此每次访问 Cache 时都会同步若干条数据到底层存储中,直到降低到低水位线。这样,在快照制作的同步阶段就可以保证 Cache 中的待同步数据是低于高水位线的,从而控制快照制作的同步耗时。
四、业务收益
接下来介绍一下方案上线以后取得的一些业务收益。
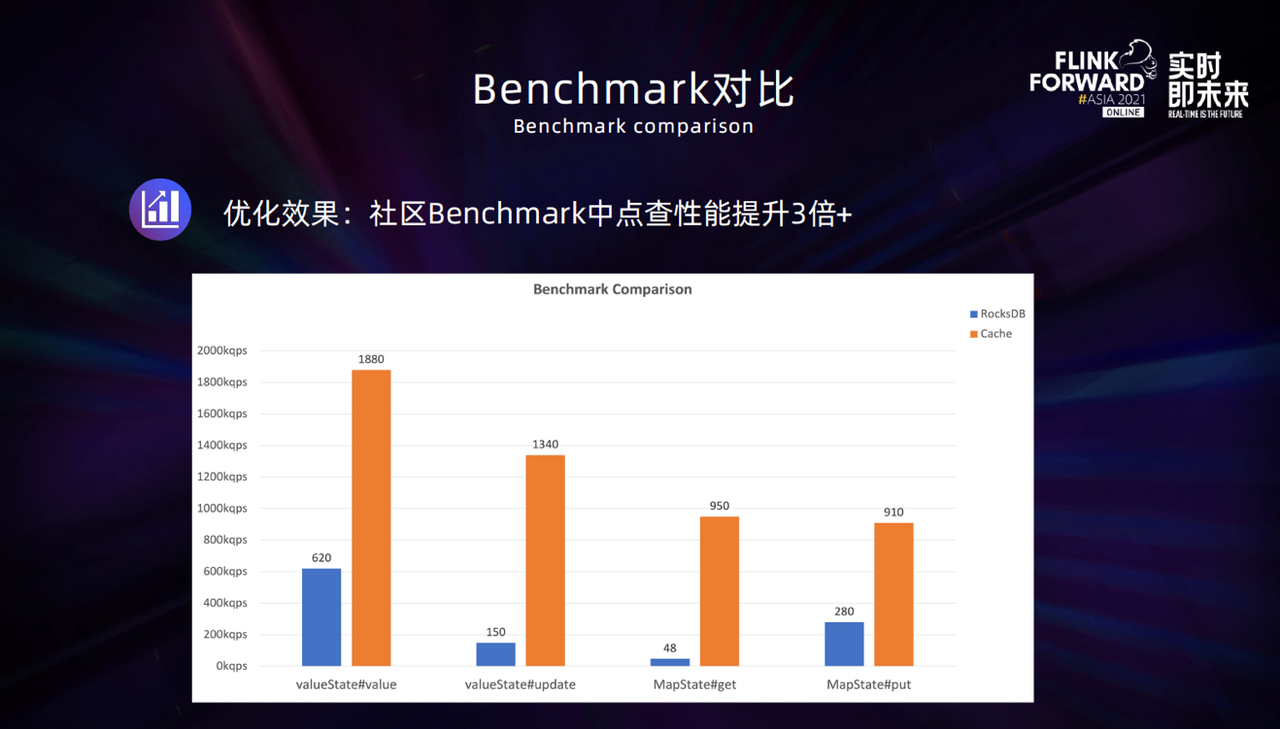
首先是 Benchmark 的对比。 这里直接使用了社区的 Benchmark 默认配置,Cache 设置的内存为 64M。优化的效果比较明显,在 State 点查操作的性能上可以提升三倍以上。

在线上任务中,我们对比了样本拼接和流式消重两个场景, CPU 的使用量基本上都下降50%以上,而内存使用上升了大概40%~50%,主要是因为存了更多数据到内存中,同时 JVM 需要依赖 GC 来回收这些数据,因此平均内存使用有比较明显的上升。但整体成本是下降的,因为 CPU 资源比内存资源的成本比大约是1:9,换算成总体成本,大概下降了20%~40%。
五、未来规划

我们的未来规划主要集中在以下四个方面:
第一,结合业务场景去探索一些更好的 Cache 缓存策略。
第二,提升 StateBackend 的恢复性能。 目前在超大状态的恢复性能上,主要还是沿用了社区原有的恢复机制,不管是 Savepoint 还是扩缩容场景,在 Task 状态比较大的时候,做一次恢复可能会耗时10分钟甚至20分钟。因此我们希望能够在恢复机制上做一些优化,提升恢复性能。
第三,优化流式计算场景中 Compaction 的策略。单 Task 状态很大尤其是达到 GB 级以上时,随着 Checkpoint 的制作,它会呈现出一个周期性 CPU 业务毛刺。查看 RocksDB 日志之后,发现是由于触发了多次 Compaction 导致的,因此我们希望做一些流式计算场景 Compaction 策略探索。
最后,探索新的 StatsBackend。 目前我们主要使用的还是社区提供的 StatsBackend,更适合于状态规模、并发规模相对来讲不是特别大的场景。在实际使用过程中也遇到了很多问题,比如说 HDFS 的请求数过高、磁盘 IO 打满、依赖 SSD 磁盘等。因此我们希望能够探索一些新的 StatsBackend,比如 RemoteStatsBackend,把数据存储到分布式存储中,降低本地磁盘的依赖,同时恢复的时候也不需要把数据全量拉取到本地,从而提高快照制作以及状态恢复的速度。
目前,字节跳动流式计算团队同步支持的火山引擎流式计算 Flink 版正在公测中,支持云中立模式,支持公共云、 混合云 及多云部署,全面贴合企业上云策略,欢迎申请试用:https://www.volcengine.com/product/flink
获取更多产品资讯,欢迎关注公众号【字节跳动云原生计算】
|








- 上一条: 如何根治 Script Error. 2022-09-22
- 下一条: 大V科技谈 | VMware云和边缘基础架构创新实现突破性的性能提升 2022-09-23
- Flink 在字节跳动数据流的实践 2022-01-11
- 用100行代码提升10倍的性能 2021-07-05
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化 2022-03-21
- 字节跳动 Flink 基于 Slot 的资源管理实践 2022-09-05
- 带你玩转Flink流批一体分布式实时处理引擎 2022-01-17


