一文读懂 Prometheus 长期存储主流方案
嘉宾 | 霍秉杰 整理 | 西京刀客 出品 | CSDN 云原生
Prometheus 作为云原生时代崛起的标志性项目,已经成为可观测领域的事实标准。Prometheus 是单实例不可扩展的,那么如果用户需要采集更多的数据并且保存更长时间该选择怎样的长期存储方案呢?
2022 年 8 月 9 日,在 CSDN 云原生系列在线峰会第 15 期“Prometheus 峰会”上,青云科技可观测与函数计算负责⼈霍秉杰分享了《Prometheus Long-Term Storage:海纳百川,有容乃大》。
Prometheus 简介及其局限性
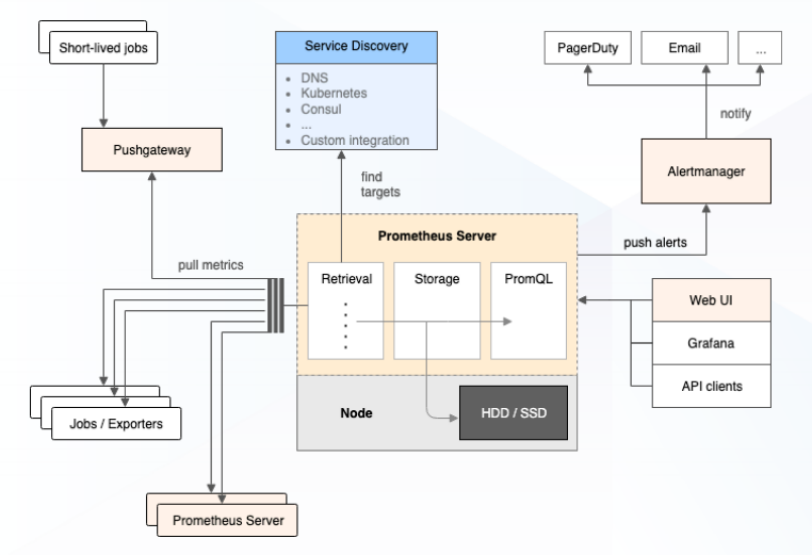
云原生时代崛起的 Prometheus 已经在可观测领域得到了广泛应用,其影响力远远超出了云原生的范畴,具有两个显著特点。
单实例,不可扩展
Prometheus 的作者及社区核心开发者都秉承一个理念:Prometheus 只聚焦核心的功能,扩展性的功能留给社区解决,所以 Prometheus 自诞生至今都是单实例不可扩展的。
这对于很多从大数据时代走过来的工程师而言有点不可思议,大数据领域的很多开源项目比如 Elasticsearch、HBase、Cassandra 等无一不是多节点多角色的设计。
Prometheus 的核心开发者曾这样解释,Prometheus 结合 Go 语言的特性和优势,使得 Prometheus 能够以更小的代价抓取并存储更多数据,而 Elasticsearch 或 Cassandra 等 Java 实现的大数据项目处理同样的数据量会消耗更多的资源。也就是说,单实例、不可扩展的 Prometheus 已强大到可以满足大部分用户的需求。
Pull 模式抓取数据
Prometheus 倡导用 Pull 模式获取数据,即 Prometheus 主动地去数据源拉取数据。对于不便于 Pull 的数据源,Prometheus 提供了 PushGateway 进行处理,但 PushGateway 在部分应用场景上存在限制。
尽管单实例的 Prometheus 已经足够强大,但还是存在部分需求是其无法满足的,如跨集群聚合、更长时间的存储等。为了扩展 Prometheus,社区给出了多种方案。
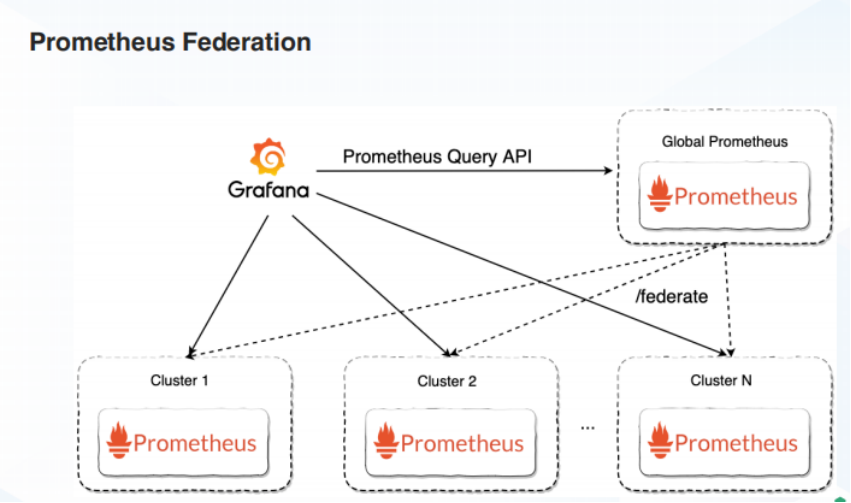
在 Prometheus 长期存储出现之前,用户若需要跨集群聚合计算数据时,社区提供 Federation 方式实现。
在多个 Prometheus 实例的上一层有一个 Global Prometheus,它负责在各个实例中抓取数据并进行计算,以此解决跨集群聚合计算的问题。但如果各个集群的数据量较大,单实例的 GlobalPrometheus 也会遇到瓶颈。
Promretheus 长期存储方案的崛起

2017 年,Prometheus 加⼊ Remote Read/Write API,自此之后社区涌现出大量长期存储的方案,如 Thanos、Grafana Cortex/Mimir、VictoriaMetrics、Wavefront、Splunk、Sysdig、SignalFx、InfluxDB、Graphite 等。
接下来我们将挑选几个主流的 Prometheus 长期存储方案进行对比分析。
M3
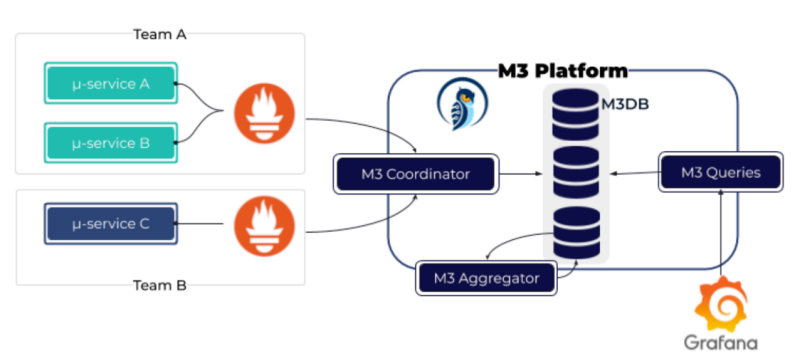
M3 是 Uber 开源的一个 Prometheus 长期存储的方案,它的组件主要包括 M3 Coordinate、M3 Queries、M3 Aggregator 及 M3DB。
M3 的工作原理是 Prometheus 将数据通过 M3 Coordinate Remote 写入至 M3DB 中,M3 Queries 可直接对接 M3DB 进行查询。M3Aggregator 对接收数据进行实时聚合,降采样后存入 M3DB。
M3 是 Uber 为了满足自身海量数据需求所开发的 Prometheus 长期存储的方案,其缺点是部署麻烦,且社区也不活跃、文档欠佳。
VictoriaMetrics
VictoriaMetrics 是一个开源的 Prometheus 长期存储项目,除开源项目外,还有商业化的产品和服务。VictoriaMetrics 的采用者包括知乎、Grammarly、fly.io、CERN 等。
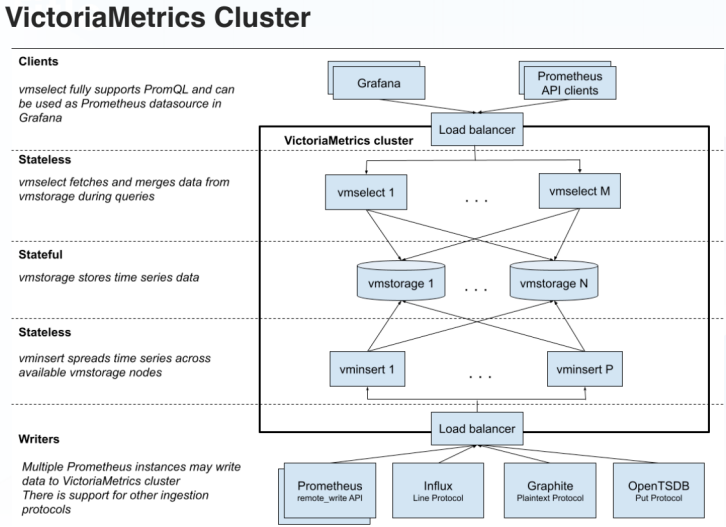
VictoriaMetrics 主要由三个组件构成:接入数据的 vminsert、存储数据的 vmstorage 以及查询数据的 vmselect。
vminsert 和 vmselect 都是无状态的,可以通过增加副本的方式进行扩展。
vmstorage 虽然是有状态的,但也可以扩展,当数据量超过一个副本的存储量时,可以通过增加另外一个副本对其进行扩展。
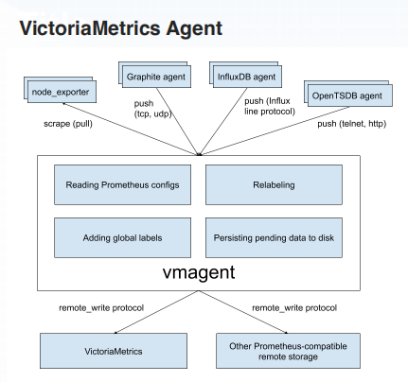
VictoriaMetrics 的 Agent 功能较为强大,主要体现在以下几方面:
- 可以代替 Prometheus 抓取数据,还可以接收 Prometheus 之外的数据源 Push 过来的数据,如 Graphite、InfluxDB、OpenTSDB 等;
- 可以把抓取的数据 Remote Write 到多个 Long-Term Storage;
- 可以将数量众多的抓取目标在 vmagent 实例之间进行分配。
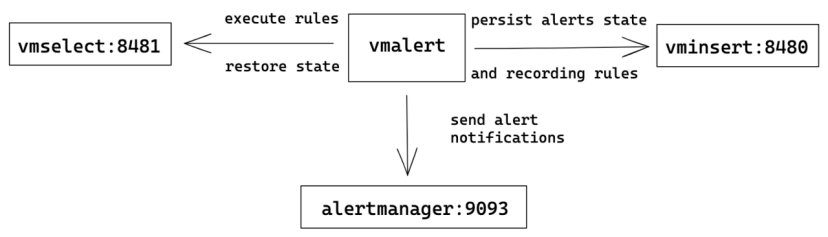
VictoriaMetrics 还有一个单独的用于告警的组件——VictoriaMetrics Alert,它具备两个功能:
- 通过查询 vmselect 决定是否需要告警,如果需要就将告警发到 alertmanager 中;
- 通过查询 vmselect 计算 Recording Rule,并把计算结果通过 vminsert 写入存储。
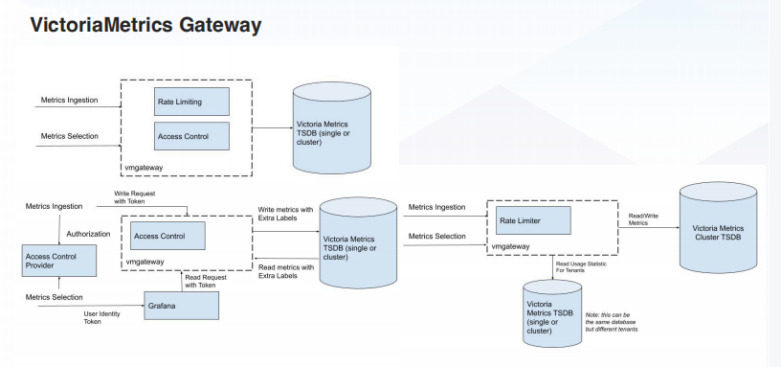
另一个组件是 VictoriaMetrics Gateway,它主要有两个功能:
- 限速,在租户读写时,会将部分数据写入至另外一个 VictoriaMetrics 的实例中来记录用量,超量的时候会做出一定的限制;
- 访问控制,访问控制指在读或者写之前,必须先得获取一个 Token。
VictoriaMetrics 还有其他的组件比如 vmauth、vmbackup/vmrestore、vmbackupmanager、vmanomaly 等。
值得一提的是,VictoriaMetrics 并不是所有功能都是开源的,未开源的企业版功能包括:
- Downsampling 降采样;
- vmgateway 的 SSO、LDAP、JWT Token Authentication&Access Control;
- 租户级别的读写限速;
- vmagent 读写 Kafka;
- 多租户告警与统计;
- BackupManager;
- 基于机器学习的异常监测 vmanomaly。
Thanos
Thanos 由 Improbable 开源,是社区最先出现的 Prometheus 长期存储方案,采用者包括 Adobe、字节、eBay、腾讯等。
Thanos 在架构上较为创新,具有诸多较为独特的功能:
- 能够提供 Prometheus 实例的全局查询视图,可以跨越多个 Prometheus 实例对数据进行查询和聚合;
- 可以把数据通过 Sidecar 上传至对象存储以便长时间保存;
- 提供压缩与降采样功能,通过压缩可以减小对象存储上保存的 Block 的大小,通过降采样可以加快长时间范围数据的查询与聚合速度。
Thanos 有两种模式,Sidecar 模式和 Receive 模式。
Thanos Sidecar 模式
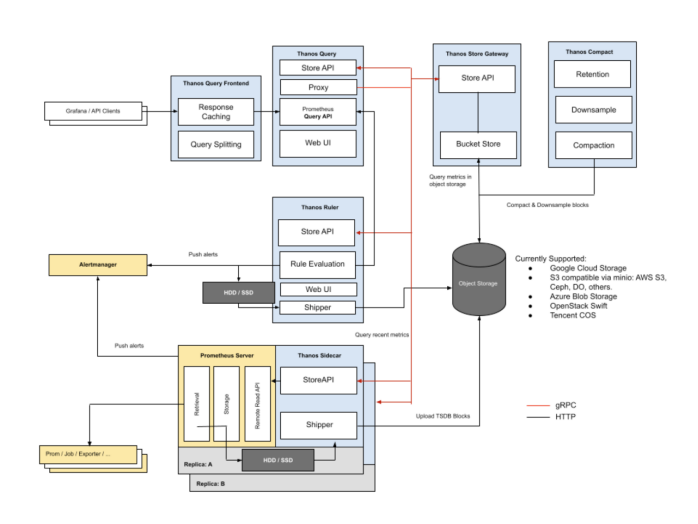
ThanosSidecar 模式是 Thanos 最早支持的模式,其原理是:
- 每个 Prometheus Pod 中都有一个 Sidecar,这个 Sidecar 通过 Store API 与外界交互;
- Thanos Query 通过 Store API 与 Thanos Sidecar 交互,经由 Thanos Sidecar 查询到各 Prometheus 实例上的数据后进行聚合,去重后提供给用户一个跨多个 Prometheus 实例的全局视图;
- Thanos Sidecar 中的 Shipper 会把本地 Prometheus 实例落盘的 Block 上传到对象存储,之后由 Thanos Compact 对上传到对象存储的 Block 进行压缩、降采样和过期删除;
- 存储在对象存储里的 Block 可由 Store Gateway 通过 Store API 向 Thanos Query 提供查询服务,Store Gateway 会缓存对象存储里 Block 的 index 以加快查询速度;
- 此外,Thanos Query 前面还有 Thanos Query Frontend 用于缓存查询结果以加快查询速度;
- Thanos Ruler 用于通过查询 Thanos Query 计算 Recording 或 Alerting Rules。
Thanos Receive 模式
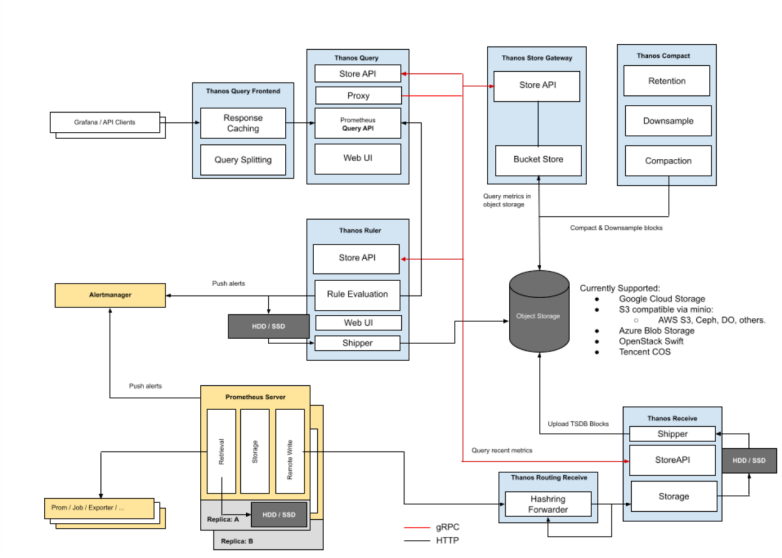
Thanos Receive 模式是 Thanos 响应社区用户 Remote Write 的需求新增的模式,其原理是:
- Prometheus 或 Prometheus Agent 通过 Remote Write 将监控数据发送到 Thanos Receive Router;
- Thanos Receive Router 根据租户信息将数据发送给响应的 Thanos Receive Ingestor,其中 Router 是无状态的,Ingestor 是有状态的;
- Thanos Receive Ingestor 相当于在一个没有数据抓取能力和告警能力的 Prometheus 之上增加了 Store API 的支持用于和 Thanos Query/Thanos Ruler 交互,增加了 Shipper 组件将落盘 Block 上传对象存储;
- Thanos Query 可以统一查询 Thanos Ingestor、Thanos Store Gateway;
- 其他组件作用和 Thanos Sidecar 模式类似。
Cortex
Cortex 由 Grafana 开源,Loki、Tempo、Grafana Cloud 等产品或项目都采用了 Cortex 的技术。采用者包括 AWS、Digital Ocean、Grafana Labs、MayaData、Weaveworks 等。
Cortex 最初是基于 Chunk Storage 的版本,因部署运维起来较为复杂且依赖 Cassandra 或 DynamoDB 存储元数据,已经确定被弃用,改为基于 Block Storage 的版本。
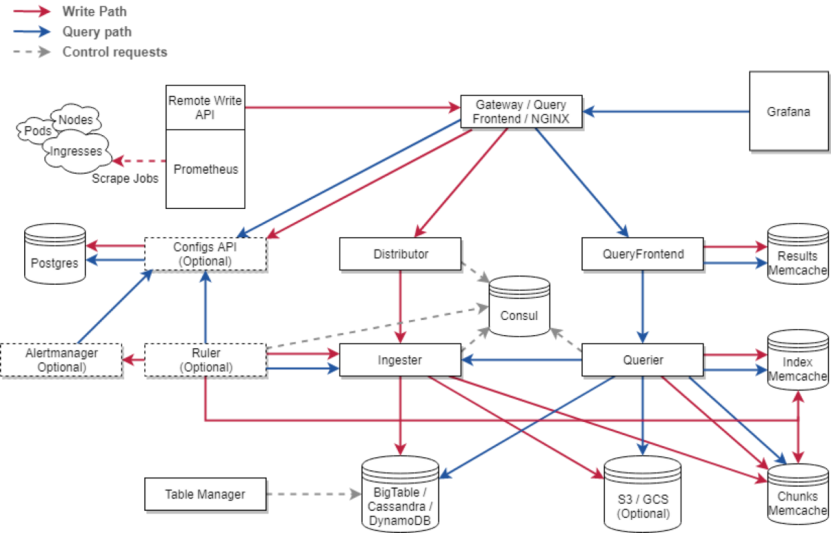
受 Thanos 的启发,Cortex 新架构采用 Block Storage。我们可以看到,Cortex 新架构的 distributor、ingester、querier、ruler、store-gateway、compactor 都与 Thanos 类似,其中 ruler、store-gateway、compactor 都借鉴自 Thanos。
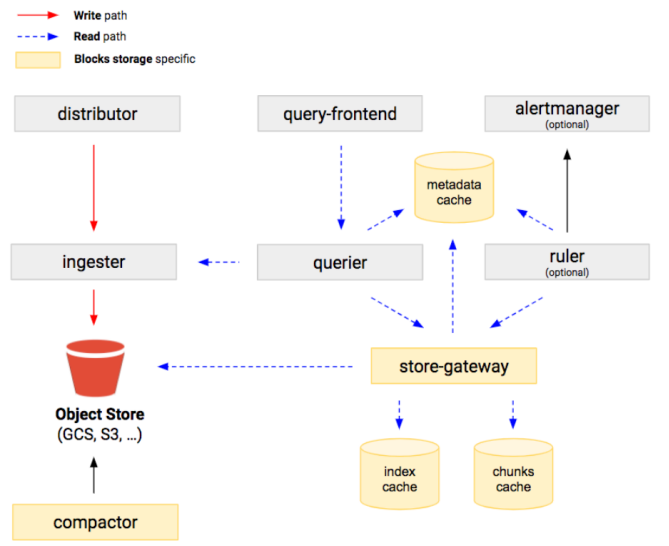
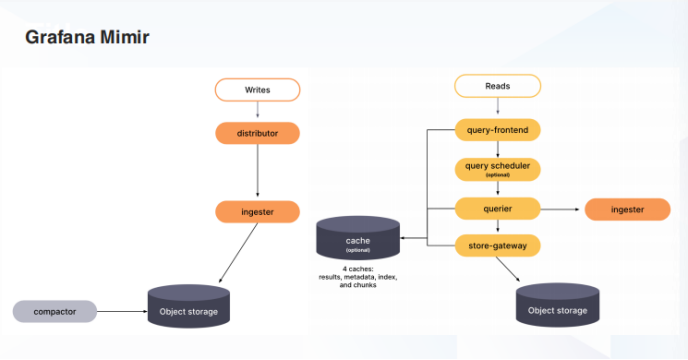
Grafana Mimir
Grafana Mimir 是 Grafana Lab 于 2022 年 3 月底以 AGPL v3 协议新发布的开源项目。
从 Mimir 发布的 Blog Announcing Grafana Mimir 可以看出,Grafana Mimir 在 Fork 了 Cortex 项目之后增加了许多企业级功能,被用于 Grafana Cloud 及服务 Grafana 的企业客户的产品 Grafana Enterprise Metrics(GEM)。这么做的主要原因是 Grafana Lab 认为 Cortex 被一些 ISV 或云厂商用于给自己的客户提供服务,却没有像 Grafana Lab 一样贡献代码,于是将越来越多的功能放到了 Cortex 的 Fork Mimir 中。
作为 Cortex 的增强版,之前很长一段时间 Mimir 是未开源的状态,但这与 Grafana Lab 的开源文化相悖,于是为了兼顾开源和自己的商业利益,Grafana Lab 将 Mimir 在 AGPL v3 下开源。

由于 Grafana Mimir Fork 了 Cortex,所以其架构和 Cortex 及 Thanos 非常相似。
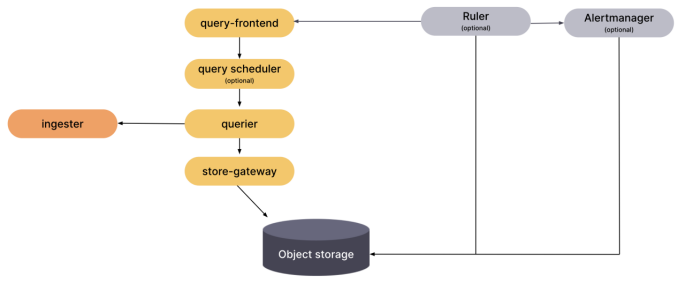
虽然 Grafana Mimir 同样借鉴了 Thanos 的 store-gateway、compactor 和 ruler,但与 Cortex 不同之处在于 querier 和 query frontend 之间加了一个额外的组件 query scheduler,更好地满足了查询组件的可扩展性。
Mimir 各组件(包括 compactor、store-gateway、query、ruler 等)的水平可扩展性较好,值得一提的是 Mimir 对 Alertmanage 做了多租户和水平扩展的支持。
Prometheus 长期存储方案对比
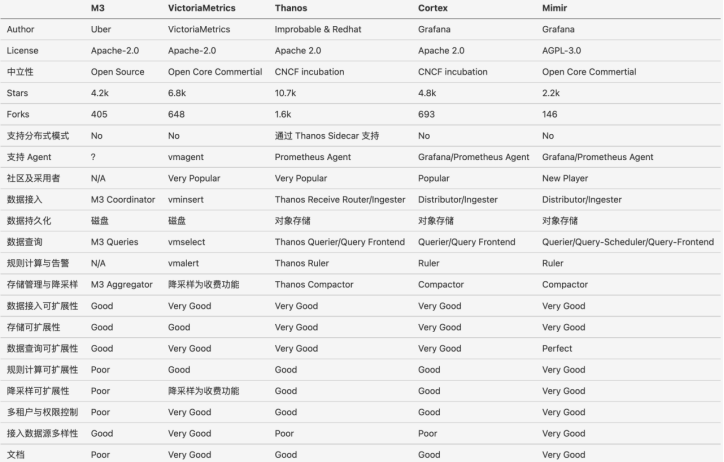
我们可以基于多维度对上述介绍的 Prometheus 长期存储方案进行横向对比:
- Thanos 和 Cortex 已捐给 CNCF 基金会并处于孵化阶段,有着更好的中立性,而 Mimir 的 AGPL v3 许可证不够友好;
- 从一些开源项目的指标看,Thanos 更受欢迎,其采用者也比较多;
- Mimir 是 Grafana Lab 商业产品的开源版本,具有更好的水平可扩展性;
- Mimir 与 VictoriaMetrics 有着更好的文档;
- 在涉及多租户、权限控制、接入数据源的多样性等企业级功能方面,Mimir 和 VictoriaMetrics 更优;
- M3 在各个维度上都不占优。
总结
综上,我们可以得出以下结论。
- 数据持久化到硬盘的方案里,VictoriaMetrics 是更好的选择,但需要注意的是 VictoriaMetrics 并没有开源 Downsampling 降采样功能,如需跨较长时间范围进行聚合及查询,耗时会比较久。
- 数据持久化到对象存储的方案中,Thanos 更受欢迎,Grafana Mimir 更有潜力。
- Thanos 可以不使用对象存储,用本地盘存数据(Cortex/Mimir 待验证)。
- Grafana Fork 了 Cortex,创建了 Mimir 并修改 License 为 AGPL-3.0。后续 Grafana 及社区的投⼊程度成疑,不建议继续采用 Cortex。
- Thanos/Cortex/Mimir 互相借鉴,架构类似。Cortex/Mimir 借鉴了 Thanos 的对象存储访问及持久化。Thanos 借鉴了 Cortex 的 QueryFrontend。Mimir 作为 Grafana Cloud 的开源版本,其基于 Thanos 和 Cortex 的架构做了更多的优化。
- 总体来说,在不介意许可证的情况下,可以采⽤ Mimir,若在意更宽松许可证,CNCF 孵化项目的 Thanos 是更好的选择。
- 没有对象存储,推荐使用 VictoriaMetrics(有些重要功能没开源),有对象存储尽量用 Thanos 或 Mimir。
- 没有特殊原因尽量不要采用 M3。
本文由博客一文多发平台 OpenWrite 发布!
|








- 上一条: 一文读懂 Prometheus 长期存储主流方案 2022-09-15
- 下一条: 没有了
- 云原生爱好者周刊:Grafana 开源 Prometheus 长期存储项目 Mimir 2022-04-06
- 百度可观测系列 | 采集亿级别指标,Prometheus 集群方案这样设计 2022-02-23
- 一文读懂浏览器存储与缓存机制 2021-10-19
- 视频直播技术干货:一文读懂主流视频直播系统的推拉流架构、传输协议等 2022-05-31
- Prometheus on CeresDB 演进之路 2021-11-17