手淘 Android 帧率采集与监控详解


作者:黎磊(千诺)
APM 提供帧率的相关数据,即 FPS(Frames Per Second) 数据。FPS 在一定程度上反映了页面流畅程度,但 APM 提供的 FPS 并不是很准确。恰逢手淘低端机性能优化项目开启,亟需相关指标来衡量对滑动体验的优化,帧率数据探索实践就此拉开。
在探索实践中,我们遇到了许多问题:
- 高刷手机占比相对不低,影响整体 FPS 数据
- 非人为滑动数据参杂在 FPS 中,不能直接体现用户操作体验
- 计算平均数据时,卡顿数据被淹没在海量正常数据中,一次卡顿是否只影响一个 FPS 值还是一次用户操作体验?
经过一段时间的探索,我们沉淀下来了一些指标,其中包括:滑动帧率、冻帧占比、scrollHitchRate、卡顿帧率。除了相关帧率指标之外,为了更好的指导性能优化,APM 还提供了帧率主因分析,同时为了更好的定位卡顿问题,也提供了卡顿堆栈。
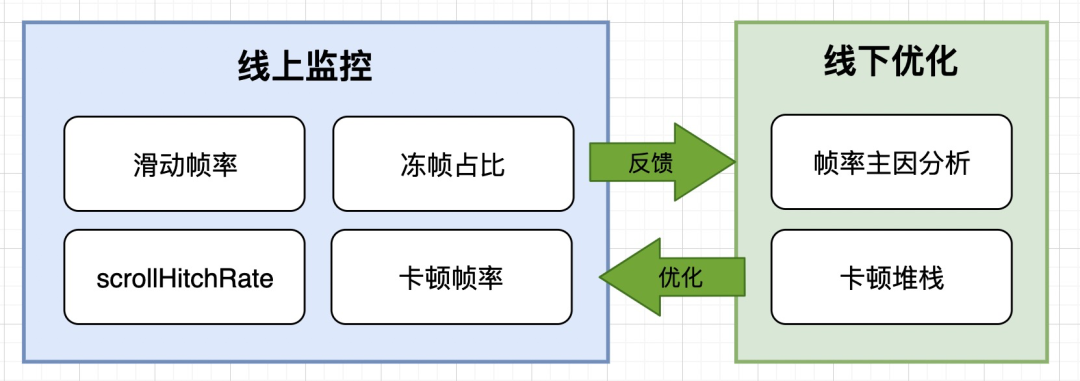
下面是 APM 基于平台的特性,对帧率相关探索实践的详细介绍,希望本文可以给大家带来一些帮助。
系统渲染机制
在介绍指标的实现之前,首先需要了解系统是如何做渲染的,只有知晓系统渲染机制,才能帮助我们更好的进行帧率数据计算处理。
渲染机制是 Android 中重要的一部分,其中又牵扯甚广,包括我们常说的 measure/layout/draw 原理、卡顿、过度绘制等,都与其相关。在这里我们主要是对渲染流程进行整体了解,知晓后续需要计算哪几部分、通过系统 API 得到了哪几部分,以便计算出目标数据。
渲染流程
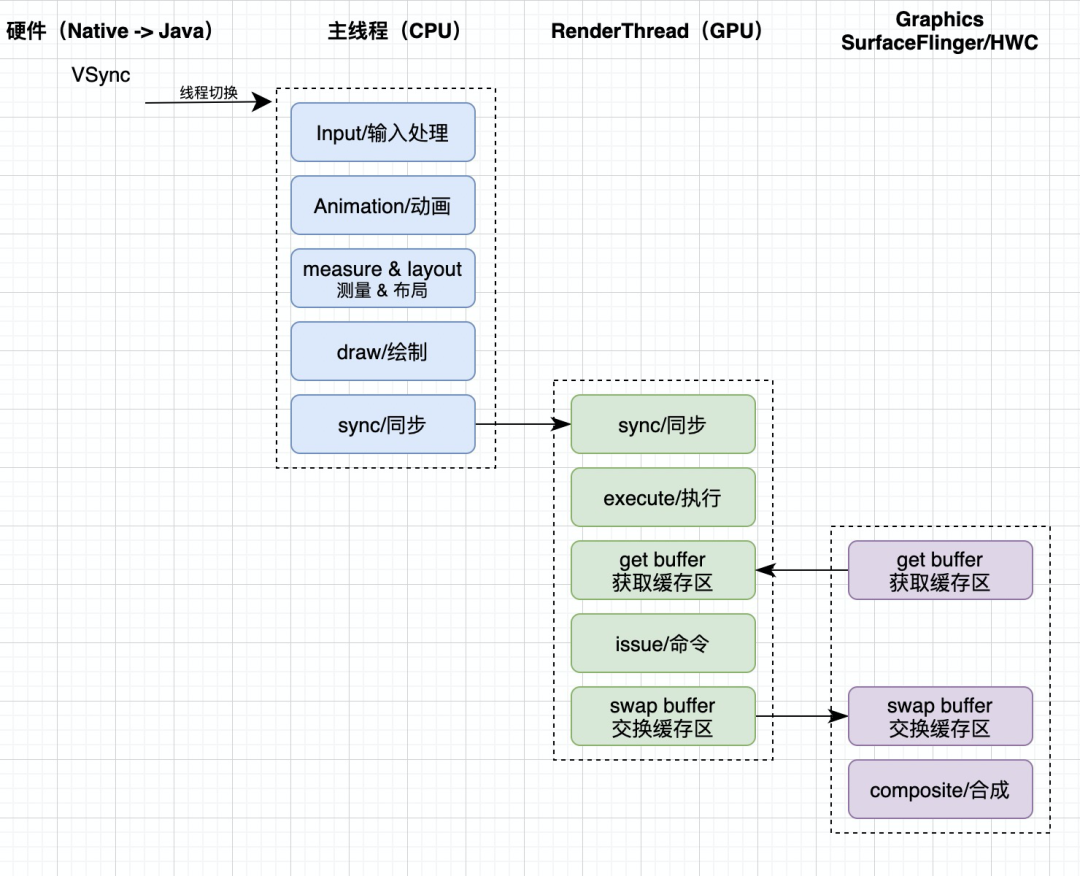
我们都知道,当触发渲染后,会走到 ViewRootImpl 的 scheduleTraversals。这时,scheduleTraversals 方法主要是向 Choreographer 注册下一个 VSync 的回调。当下一个 VSync 来临时,Choreographer 首先切到主线程(传 VSync 上来的 native 代码不运行在主线程),当然它并不是直接给 Looper sendMessage,而是 msg.setAsynchronous(true) ,提高了 UI 的响应速率。
当切到主线程后,Choreographer 开始执行所有注册了这个 VSync 的回调,回调类型分为以下四种:
- CALLBACK_INPUT,输入事件
- CALLBACK_ANIMATION,动画处理
- CALLBACK_TRAVERSAL,UI 分发
- CALLBACK_COMMIT
Choreographer 会将所有的回调按类型分类,用链表来组织,表头存在一个大小固定的数组中(因为只支持这四种回调)。在 VSync 发送到主线程的消息中,就会一条链表一条链表的取出顺序执行并清空。
而在 scheduleTraversals 注册的就是 CALLBACK_TRAVERSAL 类型的 callback,这个 callback 中执行的就是我们最为熟悉的 ViewRootImpl#doTraversal() 方法,doTraversal 方法中调用了 performTraversals 方法,performTraversals 方法中最重要的就是调用了耳熟能详的 performMeasure、performLayout、performDraw 方法。
详细代码可以翻看: android.view.Choreographer 和 android.view.ViewRootImpl
从这里我们可以看到,想要上屏一帧数据,至少包括:VSync 切到主线程的耗时、处理输入事件的耗时、处理动画的耗时、处理 UI 分发(measure、layout、draw)的耗时。
然而,当 draw 流程结束,只是 CPU 计算部分结束,接下来会把数据交给 RenderThread 来完成 GPU 部分工作。
屏幕刷新
Android 4.1 引入了 VSync 和三缓冲机制,VSync 给予开始 CPU 计算的时机,以及 GPU 和 Display 交换的缓冲区的时机,这样有利于充分利用时间来处理数据和减少 jank。

上图中 A、B、C 分别代表着三个缓冲区。我们可以看到 CPU、GPU、显示器都能尽快拿到 buffer,减少不必要的等待。如果显示器和 GPU 现在都使用着一个 buffer,如果下一次渲染开始了,因为还有一个 buffer 可以用于 CPU 数据的写入,所以可以马上开始下一帧数据的渲染,例如图中第一个 VSync。
是不是引入三缓冲机制就没有任何问题呢,当我们仔细看上图可发现,数据 A 在第三个 VSync 来临时就已经准备好,随时可以刷新到屏幕上,到真正刷到屏幕却是第四个 VSync 来临。由此可知,三缓冲虽然有效利用了等待 VSync 的时间,减少了 jank,但是带来了延迟。
这里只是简单带大家回顾了这块的知识,建议大家翻下发展的历史,知其然亦要知其所以然。
对帧数据信息的挖掘
当我们知道了整个系统渲染的流程后,我们需要监控什么,怎么监控,这是一个问题。
业界方案

APM 原始方案:
当收到 Touch 事件后,APM 会采集页面 1s 内 draw 的次数。这个方案的优点是性能损耗低,但是存在致命缺陷。如果页面渲染总时长不足 1s 就停止刷新,会导致数据人为偏低。其次,触碰屏幕不一定会带来刷新,刷新也不一定是 Touch 事件带来的。而以上情况计算出来的都是脏数据。
但是,Android 在 ViewRootImpl 实现了一个Debug 的 FPS 方案,原理与上诉方案类似,都是在 draw 时累积时长到 1s,所以,如果是想要一个低成本性能无损的线下测试 FPS,这不失为一个方案。
感兴趣可以看 ViewRootImpl 的 trackFPS 方法。
Matrix:
在帧率这部分,Matrix 创新性的 hook 了 Choreographer 的 CallbackQueue,同时还通过反射调用 addCallbackLocked 在每一个回调队列的头部添加了自定义的 FrameCallback。如果回调了这个 Callback,那么这一帧的渲染也就开始了,当前在 Looper 中正在执行的消息就是渲染的消息。这样除了监控帧率外,还能监控到当前帧的各个阶段耗时数据。
除此之外,帧率回调和 Looper 的 Printer 结合使用,能够在出现卡顿帧的时候去 dump 主线程信息,便于业务方解决卡顿,但是频繁拼接字符串会带来一定的性能开销(println 方法调用时有字符串拼接)。
常规:
使用 Choreographer.FrameCallback 的 doFrame(frameTimeNanos: Long) 方法,在每一次的回调里计算两帧之差,通过计算可以得到 FPS。
滑动帧率
FPS 是业界简单而又通用的一个指标,是 Frames Per Second 的简写,即每秒渲染帧数,通俗来讲就是每秒渲染的画面数。
计算出 FPS 并不是我们的目标,我们一直希望计算出的是滑动帧率,针对 FPS,我们更为关注的是用户在交互过程中的帧率,监控这一类帧率才能更好反映用户体验。
首先,面对之前的采集方案,根本不能采集出符合定义的 FPS,所以原始的方案就必须要进行舍弃,需要进行重新设计。当看到 Matrix 的方案时,觉得想法很棒,但是太过 hack,我们更倾向于维护成本更低、稳定性高的系统开放 API。
所以,在选择上,我们还是决定使用最普通的 Choreographer.FrameCallback 进行实现。当然,它不是最完美的,但是可以尽量在设计上去避免这种缺陷。
那我们怎么计算出一个 FPS 值呢?

Choreographer.FrameCallback 被回调时,doFrame 方法都带上了一个时间戳,计算与上一次回调的差值,就可以将之视之为一帧的时间。当累加超过 1s 后,就可以计算出一个 FPS 值。
在这个过程中,有个点要大家知晓,doFrame 在什么时机回调:
首先,我们每一次回调后,都需要对 Choreographer 进行 postFrameCallback 调用,而调用 postFrameCallback 就是在下一帧 CALLBACK_ANIMATION 类型的链表上进行添加一个节点。所以,doFrame 回调时机并不是这一帧开始计算,也不是这一帧上屏,而是 CPU 处理动画过程中的一个 callback。
当计算出一个 FPS 值后,就需要在上面叠加以下状态了:
View 滑动帧率
在最开始实现时,View 只要滑动就监控帧率,一直帧率产出到不滑动为止。根据需求,我们的帧率采集就变成了如下这样:

那怎么监控 View 是否有滑动呢?那就需要介绍一下这个 ViewTreeObserver.OnScrollChangedListener。毕竟只有了解实现原理,才能决定是否可用。
// ViewRootImpl#draw
private void draw(boolean fullRedrawNeeded) {
// ...
if (mAttachInfo.mViewScrollChanged) {
mAttachInfo.mViewScrollChanged = false;
mAttachInfo.mTreeObserver.dispatchOnScrollChanged();
}
// ...
mAttachInfo.mTreeObserver.dispatchOnDraw();
// ...
}我们可以看到,在 ViewRootImpl#draw 中,判断了 mAttachInfo 信息中 View 是否产生了滑动,如果产生滑动就分发出来。那么什么时候设置的 View 位置变化(产生滑动)的呢?在 View 的 onScrollChanged 被调用的时候:
// View#onScrollChanged
protected void onScrollChanged(int l, int t, int oldl, int oldt) {
// ...
final AttachInfo ai = mAttachInfo;
if (ai != null) {
ai.mViewScrollChanged = true;
}
// ...
}onScrollChanged 就直接连接着 View#scrollTo 和 View#scrollBy,在大多数场景下,已经足够通用。
根据我们之前讲解的渲染流程:我们可以看到 ViewTreeObserver.OnScrollChangedListener 的回调是在 ViewRootImpl#draw 中,那么 Choreographer.FrameCallback 的回调先于 ViewTreeObserver.OnScrollChangedListener 的。
对于单帧,就可以如下表示:

这样,每一帧都带上了是否滑动的状态,当某一帧是滑动的帧,就可以开始计数,一直累积时间到 1s,一个滑动帧率数据计算出来就出来了。
手指滑动帧率
View 滑动帧率,在线下验证时,与测试平台出的数据一致,并且能够符合基本需求,验收通过。上线后,也开始了运行,并能够承担起帧率相关工作。
但是,View 滚动并不代表着是用户操作导致,数据始终不全是用户体验的结果。所以,我们开始实现手指的滑动帧率。
手指滑动帧率,首先我们需要能够接收到手指的 Touch 行为。由于 APM 中已有对 Callback 的 dispatchTouchEvent 接口的 hook,所以决定直接使用此接口识别手指滑动。
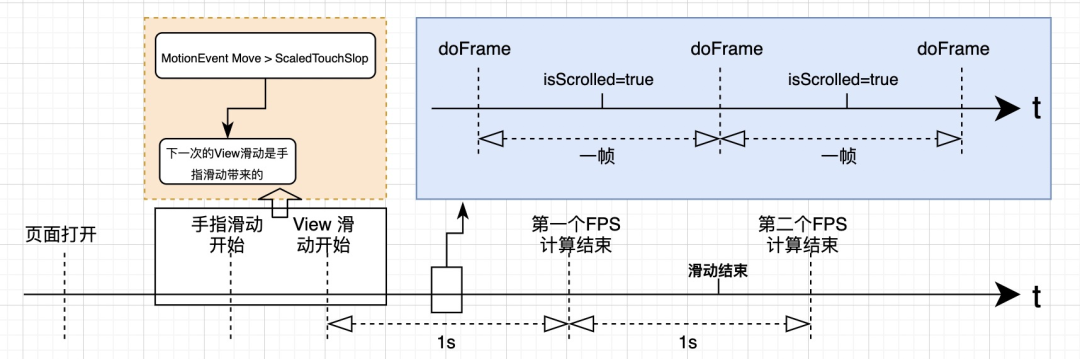
这个时候,我们需要知道几个时机问题:
- 有 dispatchTouchEvent 不会立马产生 doFrame
- 通过 dispatchTouchEvent 计算移动时间/距离超过 TapTimeout/ScaledTouchSlop,不一定立马产生 doFrame
所以,通过 dispatchTouchEvent 计算移动时间/距离超过 TapTimeout/ScaledTouchSlop 时,只会给一个 flag,通知后面的 ViewTreeObserver.OnScrollChangedListener 的 doFrame 可以开始计算成手指滑动帧率。
性能优化/滑动次数识别
我们在收到每一帧的 doFrame 回调后,都需要重新 postFrameCallback。每一次 postFrameCallback 都会注册 VSync(如果没有被注册),当 Vsync 来临后,会给主线程抛一个消息,这势必会给主线程带来一定的压力。
众所周知,系统在页面静止的时候是不会进行渲染的,也就不会有 VSync 被注册。那么在没有渲染的时候,是否也需要 post 呢?不需要,没有意义,是可以过滤掉的。基于这个理念,我们对滑动帧率的计算进行了优化。
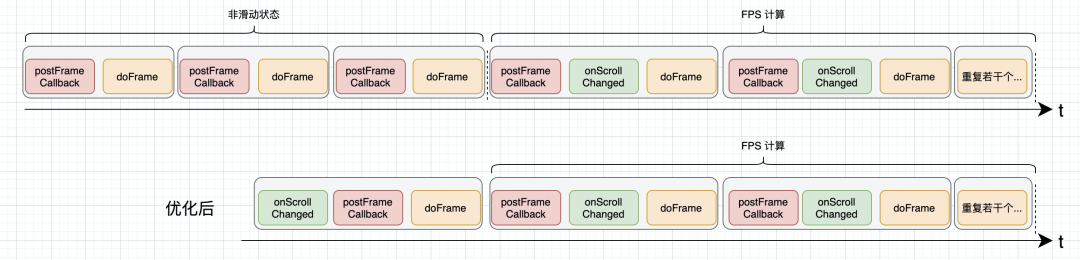
需要减少非必要的帧回调与注册,就需要明确几个问题:
- 起点(什么时候开始 postFrameCallback):在第一次收到 scroll 事件的时候(onSrollChanged)
- 终点(什么时候不再 postFrameCallback):在计算完一个手指滑动 FPS 后,如果下一帧不再滑动,那么就停止注册下一帧的回调。
如果细心的话,就会发现,这里的起点可以认为是手指带来的滑动的渲染起点,这里的终点可以认为是手指带来的滑动的渲染终点(包括了 Fling),这个数据很重要,我们相当于识别了一次手指滑动,并且能够提供每次手指滑动的耗时等数据。
这样进行优化是否就完美无缺呢?其实不是的,仔细看上图的计算开始时间点,就会发现:损失了开始滑动的第一帧数据。因为我们计算的是两次 doFrame 回调的差值,即使知道当前这一帧是需要计算的帧,但是没有上一帧的时间戳,也就无法计算出开始滑动的这一帧真正的耗时。
冻帧占比
冻帧是 Google 官方定义的一种帧:
Frozen frames are UI frames that take longer than 700ms to render.
冻帧作为一种特殊的帧,不是被强烈建议不要出现的帧,在华为等文档中也被提及过。一旦出现此类帧,页面也就像冻住似的。所以,在 APM 中,也将这一类特殊的帧纳入监控范围,计算出冻帧占比:
冻帧占比 = 滑动过程中的冻帧数量 / 滑动产生的帧数
scrollHitchRate**
scrollHitchRate 概念来自于 iOS,主要是用于描述滑动过程中,hitch 时长的占比。什么叫 hitch?可以简单理解为单个帧耗时超过了渲染标准耗时的部分就是 hitch。

计算公式如图所示:
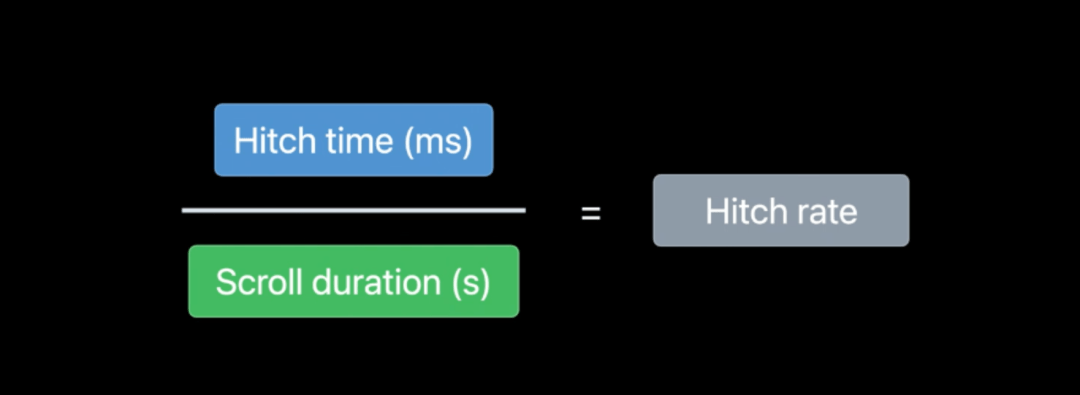
这里的分子是指整个滑动过程中,hitch 的累加值,这里的分母就是整个滑动耗时(包含 Fling)。
大家可能会问: 那为什么不用FPS? 不是可以用 fps 来检测滑动卡顿情况么,为什么还要有一个 Hitch rate ?
这是因为 FPS 并不适用于所有的情况。比如当一个动画中有停顿时间, FPS 就无法反应该动画的流畅程度,而且并不是所有的应用都以达到 60 fps/120 fps 为目标,比如有些游戏只想以 30 fps 运行。而对于 Hitch rate 而言,我们的目标永远是让它达到 0。
引入 scrollHitchRate 单纯为了解决高刷手机的数据不一致问题吗?不是的。我们在采集到一个 scrollHitchRate 数据,还隐式的带上了滑动次数。例如,在手淘场景下,首页同学咨询过一个问题,会不会页面越往下刷,卡得越严重?当采集到这个数据后,就可以进行回答了。
帧率主因分析
无论是滑动帧率,还是冻帧,更多的还是偏向于监控数据,如果想要在数据上分析出当前帧率低的主要原因还是没有办法入手的。
在之前渲染流程中,就讲到渲染流程主要分成哪几步,如果能够将渲染流程的每一步都进行监控,那么我们就可以认为:当某一个异常帧出现后,主要问题出现在哪一个阶段了,但是我们还是希望不要像 Matrix 那样侵入系统代码。基于这个思路,我们发现系统提供了满足我们需求的 API:Window.OnFrameMetricsAvailableListener。Google Firebase 也同样在使用这个 API 进行帧数据监控,也不太会有后续的兼容性问题。
FrameMetrics,开发文档见 https://developer.android.com/reference/android/view/FrameMetrics
在异步回调给的 FrameMetrics 数据中,会告诉我们每一帧每一个阶段的耗时,非常契合我们的监控诉求。但是依然有两个问题值得重视:
- FrameMetrics API 是在 Android 24 上提供的,查看手淘用户数据可以发现,能够满足基本需求;
- 一帧数据处理不及时会有丢数据的风险,但可以通过接口知晓丢弃了几帧数据。
下面我们就详细查看下 FrameMetrics 数据中定义了哪些渲染阶段:

摘抄自 Android 26。除上诉提及的字段此,还有几个比较不错的时间戳字段,也可以探索出一些新奇的玩法,大家可以一起探索下。
大家有没有发现,跟渲染流程一模一样。在跟踪了下相关源码后,注册一个 listener,并没有太多的性能损耗,FrameMetrics 内部记录的时间戳即使不注册也会进行采集,所以不会带来额外的性能开销。
首先我们定义了一个需要进行分析的帧耗时阈值,超过这个阈值就可以认为需要统计原因。我们定义:当一帧某一个阶段耗时超过阈值一半即为主因,反之则主因不存在。
如此一来,针对某一个 Activity 就可以分析出是主线程卡顿导致帧率低,还是布局问题导致 layout & measure 慢,亦或是 draw 有问题,在性能优化时,直接锁定主因进行优化。
卡顿帧率
首先我们再来回顾一下人眼的卡顿感知。原理上,高的帧率可以得到更流畅、更逼真的动画,要生成平滑连贯的动画效果,帧速不能小于8FPS;每秒钟帧数越多,所显示的动画就会越流畅。一般来说人眼能继续保留其影像1/24秒左右的图像,所以一般电影的帧速为24FPS。相对于游戏而言,无论帧率有多高,60帧或120帧,最后一般人能分辨到的不会超过30帧。电影虽然只有24帧每秒,但由于每两帧之间的间隔均为1/24秒,所以人眼不不会感觉到明显的卡顿,游戏或者我们界面的刷新即使达到30帧每秒,但如果这一秒钟内,30帧不是平均分配,就算是每秒60帧,其中59帧都非常流畅,而有一帧延时超过1/24秒,依然会让我们感觉到明显的卡顿。
这就是我们界面上大部分情况下都已经滑动的非常流畅,但是偶尔还是会察觉到卡顿的原因。按照1/24秒的话,帧时间在41.6ms,如果中间有超过41.6ms的话,我们是可以感觉到卡顿的,如果按照1/30的话,帧时间在33.3ms,如果某一帧的延迟时间超过了33.3ms,那么人眼就容易察觉到这个过程,为了把这些卡顿的情况反映出来,我们需要在遇到这些帧的时候做一些记录。但是如果我们只是去记录过程中那些耗时超过33.3ms的帧,这种情况下,一方面会丢失掉时间的因素,很难去衡量卡顿的严重性(毕竟一段时间内不间断的出现卡顿,比偶尔掉一帧要让人明显很多),另一方面,因为有多重缓冲区的影响,未必100%会掉帧,所以我们只是取这个超过某一时刻的帧未必是准确的。
基于以上的考虑,这里使用了一个瞬时FPS的概念用于衡量卡顿,瞬时FPS就是在滑动过程中产生的一些耗时比较小的区间中计算的值。例如用户滑动了500ms,这个过程可能会出现几个用户统计的瞬时FPS。这个过程是怎么计算的?
- 滑动过程获得每一帧的时间间隔;
- 按照100(99.6ms,6帧的时间)毫秒左右的时间细化卡顿区间;
- 从时间间隔大于33.3毫秒的帧开始记录,作为区间起点;
- 结束点是从起点开始的帧耗时相加,达到99.6ms并且后面的一帧耗时小于17毫秒(或者到达最后一帧),否则会继续寻找结束点;
- 这段时间内在统计帧率,是这里要寻找的卡顿帧率。
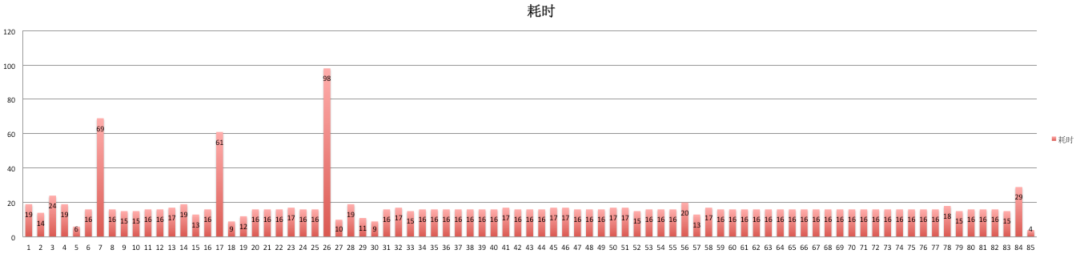
可以看到有3帧明显超出比较多。按照以前的统计方法,帧耗时:1535ms, 帧数量是:83,那么这个界面的FPS是54。我们可以看到帧率的FPS比较高,完全看不到卡顿了,即使前面有一些比较高的耗时帧,但是被后续耗时正常的帧给平均掉了。所以以前的统计方式已经不能反映出这些卡顿问题。
按照新的计算方式,应该是从第7帧开始统计第一个瞬时FPS区间,从这一帧开始,统计至少99.6ms的时间,那么69+16+15,已经达到了100ms,3帧,所以FPS是30,因为低于50,所以这一次FPS会比记录,其中最大的帧耗时是69ms。
第二次从17帧开始,5帧114ms,FPS为43ms,最大帧间隔是61ms。
第三次从26帧开始,98+10=108ms,但是后面帧的耗时时间为19ms,超过16.6ms,所以仍然会加入一起统计。3帧,127ms,FPS为23。最大帧间隔是98。
按照这次的统计,总共有3次卡顿FPS,分别是30,43,23,最大的帧耗时帧是98。
卡顿堆栈
如果使用主线程的 Looper Printer 来进行卡顿堆栈 dump,会因为大量的字符串拼接而带来性能损耗。在 Android 10 上,Looper 中新增 Observer,能够性能无损的回调,但由于是 hide 的 API,则无法使用。最终的办法只能是不断向主线程 post 消息,可每隔一段时间就给主线程抛消息又会给主线程带来压力。
是否有更好的方式呢?有的,通过 Choreographer postFrameCallback,本身就会 post 主线程消息,利用两次回调之间的差值高于某一个阈值,就可以认为是卡顿。而且这个识别的卡顿,还是滑动过程中的卡顿。
知道什么是卡顿,那什么时候 dump 呢?我们使用了 watchdog 的机制 dump 出卡顿堆栈,即在子线程 post 一个 dump 主线程的消息,如果单帧耗时超过阈值就进行 dump,如果在规定时间内完成当前帧,就取消 dump 的消息。当我们采集上来堆栈后,我们会将卡顿的堆栈进行聚类,便于更好的决定主要矛盾、告警处理。
对帧数据使用的探索
AB 与 APM 结合使用
上文主要还是讲解了我们怎么计算出一个指标、怎么去排查问题,可是对于一个大盘指标而言,重之又重的当然是需要用来衡量优化成果的,那怎么去衡量优化呢?最好的手段是 AB。APM 指标数据与 AB 测试平台打通,性能数据随 APM 实验产出。
这里的AB平台包含一休平台、魔兔2平台,一休平台指标接入方式使用的是自定义指标,帧率只是作为指标之一接入,启动、页面等数据亦是其中之一。
一休是阿里集团一站式A/B实验的服务平台,向各个业务提供了可视化的操作界面、科学的数据分析、自动化的实验报告等一站式的实验流程;通过科学的实验方法和真实的用户行为来验证最佳解决方案,从而驱动业务增长。
我们在进行页面性能优化时,能够直接使用相关指标对基准桶与优化桶进行对比,直接而又明显的显示对页面性能的优化。

写在最后
对于手淘性能监控而言,帧率监控、卡顿监控只是性能监控其中的一小环,打磨好每一个细节也至关重要。相关数据除了与 AB 平台搭配使用之外,已经与全链路排查数据、舆情数据、版本发布性能关口相打通,借用后台聚类、告警、自动化邮件报告等数据手段透出,专有数据平台进行承接。对于数据的态度,我们不仅是要有,而且要全面而强大。
在一轮又一轮的技术迭代下,手淘的高可用体现也不断完善与重构,希望在未来,手淘客户端高可用相关数据能够更好的助力研发各个环节,预防用户体验腐化,帮助不断提升用户体验。
关注【阿里巴巴移动技术】微信公众号,每周 3 篇移动技术实践&干货给你思考!
|








- 上一条: 在 Android 12 中构建更现代的应用 Widget 2022-01-10
- 下一条: 前端质量提升利器-马可代码覆盖率平台 2022-01-11
- Swift 在手淘商品评价的技术重构与实践 2022-01-06
- Android Studio 新特性详解 2022-01-18
- Android 与 Chrome OS 中针对大屏幕设备的更新 2022-01-14
- 打造手淘极简包的轻量化框架 2022-01-17
- 优酷鸿蒙开发实践|优酷 Android 与HarmonyOS Hap 混合打包 2021-10-20


