分布式数据库下子查询和 Join 等复杂 SQL 如何实现?
作者 | 刘垚
编辑 | 尔悦
小 T 导读:在使用或者实现分布式数据库(Distributed Database)时,会面临把一个表的数据按照一定的策略分散到各个数据库节点上的情况,随之而来的是多节点数据查询复杂性的问题,例如 Join 和子查询。本文将会为你解读分布式数据库下子查询和 Join 等复杂 SQL 如何实现,来帮助你更好地解决上述问题。
首先简单讲一下 SQL 的执行过程:
SQL ==> Parser ==> Translate & Semantic Check ==> Optimizer ==> Coordinator ==> Executer
Parser 产生的是语法树,即 Abstract Syntax Tree;
Translate & Semantic Check,这一步会从 Catalog 读取元数据,用元数据完善语法树,便于 Optimizer 使用。例如:常见的 select * from tableA,一般会在这一步把“*”换成 tableA 的列;
Optimizer 产生的是优化之后的逻辑执行计划,即 Optimized Logical Plan,执行计划是个有向无环图,即 DAG;
Coordinator 负责分发逻辑执行计划给各个节点去计算;
Executer 会把逻辑执行计划转成物理执行计划,即 Physical Plan。
开源的数据库有很多,我们可以结合一些主流数据库的源代码来理解子查询和 Join 的实现方式,比如关系型数据库:Impala、Presto、ClickHouse,时序数据库(Time-Series Database):TDengine 等。下面从子查询和 Join 两部分进行分析。
逻辑执行计划有多种 Node,分别对应着 SQL 中的各种计算,包括 Scan Node、Join Node、Aggregate Node、Sort Node、Project Node 等等,相应的物理执行计划的算子为 Scan Operator 、Join Operator、Aggregate Operator、Sort Operator、Project Operator 等等。而数据库一般没有计算子查询的算子,这是因为将抽象语法树转成逻辑执行计划之后,就已经没有子查询的概念了,其运行逻辑是数据算子之间自下而上逐层传递,并逐层计算,并不特别计算子查询。下面讲一下分布式数据库针对子查询的一些相关处理。
首先,分布式数据库的优化器会将子查询扁平化处理,这种方式一般分为两种,一种是直接在语法树(AST)上做子查询扁平化(Subquery Flatten),另外一种是在生成逻辑执行计划时进行扁平化。这两种方式本质上大同小异,都要保证语义的等价性。但也并不是所有的子查询都能扁平化,有如下几种特殊情况:
子查询和父查询都有聚集函数
子查询有聚集函数,并且父查询有分组计算(Group By)
子查询有聚集函数,并且用子查询聚集函数的结果关联(Join)父查询的表
父查询有聚集函数,并且子查询有分组计算(Group By)
子查询有 Limit(限制返回结果的行数),并且父查询有过滤条件(Where)或者分组计算、排序(Order By)
其他
基于 AST 进行子查询扁平化时,需要先遍历语法数据,并按规则进行判断,进而去除不必要的子查询。对于生成逻辑执行计划时的子查询扁平化,在生成 Plan Node 时需要先去除冗余的 Node,举个例子,SQL:select colA from (select * from tA) group by colA;
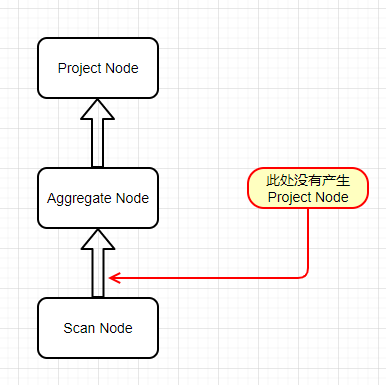
一般来说,逻辑执行计划会有多个子计划,通常在需要网络传输时才会产生子计划,需要注意的是子计划和子查询之间并没有必然的联系,即有子查询不一定对应一个子计划。
首先,分布式数据库会对 Join 进行优化,包括 Join 消除(例如基于主键外键去除不必要的 Join)、外连接消除(Outer Join 转成 Inner Join)、Join Order 优化(基于数据的统计信息,用动态规划算法、贪心算法或遗传算法等优化 Table 的 Join 顺序)等等。
再讲一下 Join 的三种基本算法:Hash Join(必须要有等值连接条件,例如 t1.colA = t2.colB)、Merge Join(左表和右表的数据都是有序的,按连接条件中的列有序)、Nestloop Join(含有非等值连接条件并且数据无序)。在实际当中,会把三种算法进行混合使用,这是因为 Join 条件可以同时包含等值连接和非等值连接,例如 t1.colA = t2.colB AND t1.colC > t2.colC
Hash Join
在进行 Join Order 优化时,优化器会调整左表和右表的顺序,一般把小表放右边,大表放左边,并且选择 Join 模式:Shuffle Join(按照关联条件,同时 shuffle 左表和右表,然后再计算 Join) 或 Boradcast Join(把右表广播到左表所在的节点,注意左表不动,然后再计算 Join)。一般是基于代价去选择 Join Order 优化,但考虑到统计信息可能会存在误差,因此很多数据库可以通过 Hint、Query Option 等方式,由用户来指定 Join 顺序、Join 模式等。
Hash Join 是目前最常用的 Join 算法,大部分数据库都实现了 Hash Join。这种算法会先读取右表,并把右表的数据放入 Hash Map 里,如果存不下就会放入外存。通常情况下,各个数据库都会实现自己的 Hash Map,很少直接使用 STL 或 Boost 等第三方库中的 Hash Map,原因主要有两点:
定制化 Hash Map 会提升 Join 计算速度。
定制化 Hash Map 能更准确地控制内存使用,当内存不足时,会使用外存,定制化 Hash Map 可以根据 Join 算法,优化 Swap 机制,减少 Swap 的数据量。Hash Map 的结构如下:
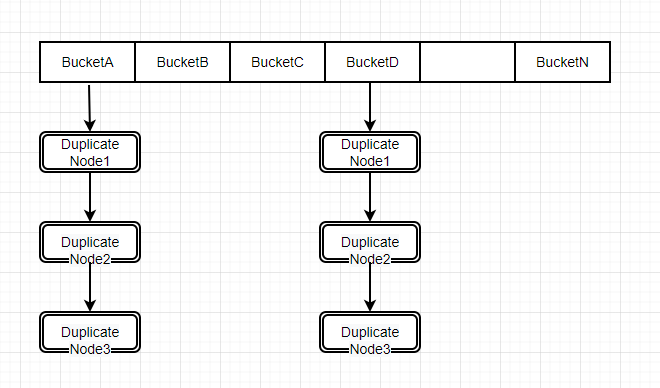
右表可能含有重复的数据,所以会有 Duplicate Node。这里的重复数据是指 Join Key(Join 条件对应的列)的数据重复,并且其他列不重复,所以要分别缓存。注意上述图中,是通过 Hash 算法解决 Hash 冲突的问题,即不会把不同的 Join Key 放在同一个桶中。当然,现实操作中也有把不同的 Join Key 放在同一个桶中的情况,那需要遍历 List 才能确定查找的 Join Key 是否存在。
Merge Join
Merge Join 一般是在左表和右表的数据是有序的情况下使用。例如时序数据库 TDengine,数据按时间戳列有序,那么用时间戳列做 Join 时,TDengine database 会用 Merge Join 来计算,这样的一个好处是处理速度非常快,并且占用内存非常小。
Nestloop Join
这种 Join 算法速度非常慢,但对于全功能数据库而言是不可缺少的。使用这种算法时,可以结合索引来提速。
总结而言,Hash Join 使用最广,适用于很多数据分析的场景,并且大部分数据库都支持;Merge Join 一般是在左右表数据有序时才会使用,不需要缓存数据,所以使用内存非常少,计算速度是三种 Join 算法中最快的;Nestloop Join 性能很差,分布式数据库一般很少使用,有些分布式数据库就不支持,可以通过索引来加速 Nestloop Join。
上面我们对子查询和 Join 两种复杂 SQL 的实现方式做了具体解读,大家可以结合一些开源数据库的源代码来理解,像 TDengine 的源代码都可以在 GitHub 上看到,如果你对时序数据库的复杂 SQL 实现有兴趣,这就是一个不错的观摩对象。也欢迎大家在下方评论区进行交流。
👇 点击阅读原文,了解体验 TDengine!
本文分享自微信公众号 - TDengine(taosdata_news)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
|








- 上一条: 在 Kubernetes 中基于 StatefulSet 部署 MySQL(下) 2022-06-09
- 下一条: 基于分布式数据库本身的定时备份方法 2022-06-10
- SQL 查询并不是从 SELECT 开始的 2021-07-16
- 浅析数据库多表连接:ZNBase 的分布式 join 计算 2021-08-02
- 必须知道的SQL语句不走索引时的排查利器 2021-07-11
- 从一次 SQL 查询的全过程看 DolphinDB 的线程模型 2021-12-16
- 探究Presto SQL引擎(2)-浅析Join 2022-04-19


