BadgerDB原理及分布式数据库的中应用与优化
Part 1 - BadgerDB设计架构
Badger[1]是基于论文:WiscKey: Separating Keys from Values inSSD-conscious Storage[2]的思想利用Go语言进行设计实现的。
LSM-Tree的优势在于将随机写转换为顺序写,将大块的内存连续地写入到磁盘,减少磁盘寻址的时间,同时数据是按照key排序,查找起来速度快,同时也带来了写、读放大。LSM-Tree的这些优化很适用HDD,但是SSD的性能却受到限制(写放大)。因此,Wisckey提出了一种面向SSD的,将key-value分离存储的方法。
下面先分析一下LSM-Tree写、读放大。写放大主要是因为各个层级之间的Compaction,当两个层级之间做Compaction时,都需要将多个SSTable读到内存排序(读放大),然后写到磁盘。读放大主要是在LSM-Tree中查找一个key时,一般查询流程是MemTable、Immutable MemTable以及SSTable。如果该key不存在,虽然MemTable和Immutable MemTable是内存操作很快,但是在Level 0层的SSTable中Key是全局无序的,可能还有重叠,需要全扫,更高层级的SSTable中也需要二分查找,虽然有bloom filter但是依旧影响查找的效率。图1中展示了LevelDB中写、读方法的测试,数据集大小分为1G和100GB,其中Key大小为16B,Value大小为1KB。
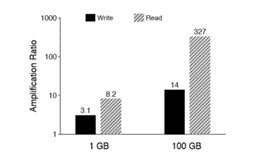
图1 LevelDB的写、读方法
Wisckey提出的优化是:Key-Value分离存储。LSM-Tree里面存储的是一个Key以及Value的地址,Value本身以WAL方式append到Value Log文件中。这样在做Compaction的时候就只需要重写Key以及Value的地址就可以了,SSD中数据的分布如图2所示。因此,在Key size远远小于Value size的场景中降低写放大的效果显著。但是当Value很小的时候,重写Value的开销就很小,Key-Value分离带来的好处不足以抵消其本身的开销(读写Key-Value需要操作不同的文件,在range query的场景下,会产生多次的随机IO )。

图2 Wisckey中数据在SSD中的分部
基本操作流程:
-
写流程:先把Valueappend到Value Log(为了便于GC操作也会写入Key),然后把Key以及Value的地址(<vLog-offset,value-size>)写入LSM-Tree的MemTable中,然后按照一定策略利用MinorCompaction将MemTable写入SSTable。
-
读流程:先从LSM-Tree里面读取Key对应Value的地址,然后从ValueLog读取Value。
-
删除流程:只需把Key从LSM-Tree里面删除,无需操作ValueLog。Value由GC机制进行处理。
由于LSM-Tree做Compaction时不需要重写Value,大大减小了写放大。同时LSM-Tree更小,一个Block能存储更多的key,也会相应的降低读放大,能缓存的Key以及Value地址也更多,缓存命中率更高。
面临的一些挑战:
-
RangeQuery: Range query允许用户查询一段有序range内的KV对,可以对其进行遍历。当发起一次rangequery的时候,最终会被转换为对Value Log的多次随机读,而对LSM-Tree则是顺序读。因此在Value小的情况会增加了延迟。
该场景下,Wisckey会通过充分利用SSD并行I/O特性,在range query时对Value Log中的Value进行预取缓存。预期缓存对于大范围的range query效果比较明显,但是对于小范围的range query可能作用不大。根据论文的实验数据如图3所示(100GB的数据集中查询4GB数据),当value大于4KB时,读的性能才体现出来。
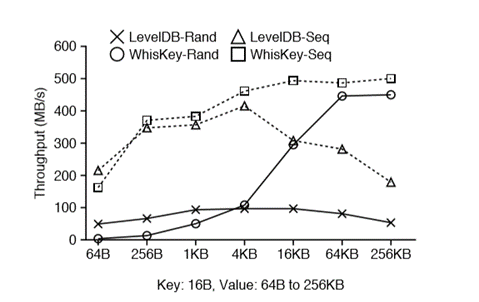
图3 范围查询性能
-
GC:由于删除操作只会删除LSM-Tree里面的Key以及Value地址,不会删除ValueLog的Value。
如图4所示,Wisckey在Value Log中会存储元组(keysize, value size, key, value)同时会存储<head,head-vLog-offset>以及<tail,tail-vLog-offset>,用来标识最后做GC的位置。会从tail开始扫描Value Log,获取Key-Value。为了不影响在线服务,会每次取出Value Log最旧的一部分数据(MB),通过读取LSM-Tree来验证其有效性,如果过期或者被删除则丢弃;有效则append写入到最新的vlog,然后更新tail的值,并删除tail之前的数据,通过 fallocate()释放无效的文件磁盘空间。如图5所示,Wisckey在GC是的性能在所有情况下至少比LevelDB快70倍。

图4 Wisckey中GC处理的数据结构
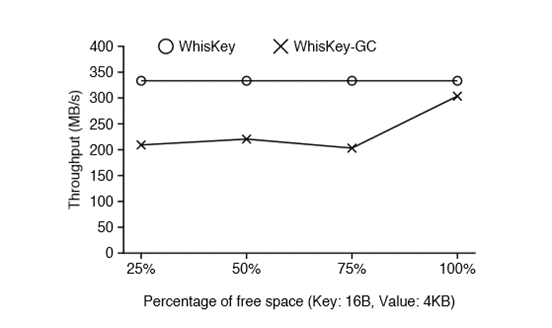
图5 Wisckey的GC性能
-
一致性:Wisckey是先写入Value Log,再写入LSM-Tree,所以会有以下几种失败情况:vLog写入失败;vLog写入成功,LSM-Tree写入失败;vLog写入成功,LSM-Tree写入成功后立刻崩溃。
在Wisckey中vLog写入失败,则LSM-Tree肯定写入失败。可能会残留部分vLog数据,由GC机制来回收。vLog写入成功,LSM-Tree写入失败:此时vLog的值便成了垃圾数据,会有GC机制来回收。vLog写入成功,LSM-Tree写入成功后立刻崩溃:Wisckey中取消了LSM-Tree的WAL,所以写入LSM-Tree也仅仅是写入了内存的MemTable,此时程序或者机器发生崩溃LSM-Tree的数据依旧会丢失。Wisckey的做法是保存元组(key size, value size, key, value)以及<head, head-vLog-offset>在vLog中。每次Open数据库的时候,读取vLog中head的值,然后依次读取head-vLog-offset之后的记录,并将Key以及Value地址写入到LSM-Tree,最后更新head的值。如果更新head的值发生崩溃也无所谓,只不过再次Open数据库的时候多重放一点记录罢了。
Wisckey中Key-Value分离的策略在大Value场景下效果显著,但是对于小Value性能不如LSM-Tree。为此在BadgerDB中设置一个Value阈值,当Values大小超过阈值时该Value存入vLog,小于阈值时存入LSM-Tree。
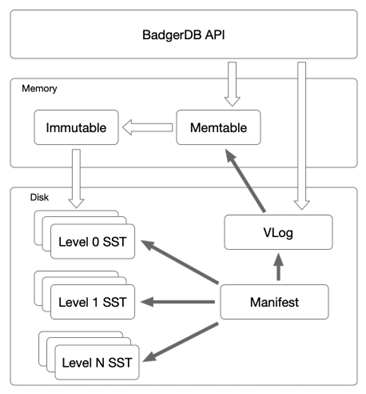
图6 BadgerDB整体架构
BadgerDB是基于Wisckey论文实现的,整体架构类似LevelDB,具体如图6所示,区别就在于去掉了LSM-Tree里面的WAL,用vLog代替。在实现上,去掉了current文件。
功能特性:
-
支持常用的Get、Put、Delete、Batch等操作。
-
实现了SSI隔离的Transaction,支持读、写事物。
-
所有的操作都是以Transaction执行的。
-
支持MVCC,支持多版本的Key-Value。
-
支持对key设置TTL以及UserMeta。
-
所有的Key都是有序存储的,支持Iteration和Prefix-Scan。
-
支持Key的Compaction以及Value的GC。
Part 2 - 云溪数据库中的RAFT算法
云溪数据库是分布式数据库,与CockroachDB等一样都是NewSQL家族的一员。云溪数据库具备强一致、高可用的分布式架构,能够水平扩展提供企业级的安全特性完全兼容PostgreSQL协议,能够为用户提供完整的分布式数据库解决方案。云溪数据库的整体架构如图7所示,云溪数据库的强一致性是由Raft算法[3]保证分布式多副本之间数据强一致性以及外部读写的一致性,简言之云溪数据库中数据会有多个副本,这些副本存放在不同的机器上,当其中一台机器故障宕机后数据库依旧能够对外提供服务。云溪数据库会根据插入数据的键,将数据划分为多个Range,每个Range上的数据都有一个Raft Group来维持多个副本之间数据的一致性。因此,准确地说云溪数据库使用的是Multi-Raft算法。
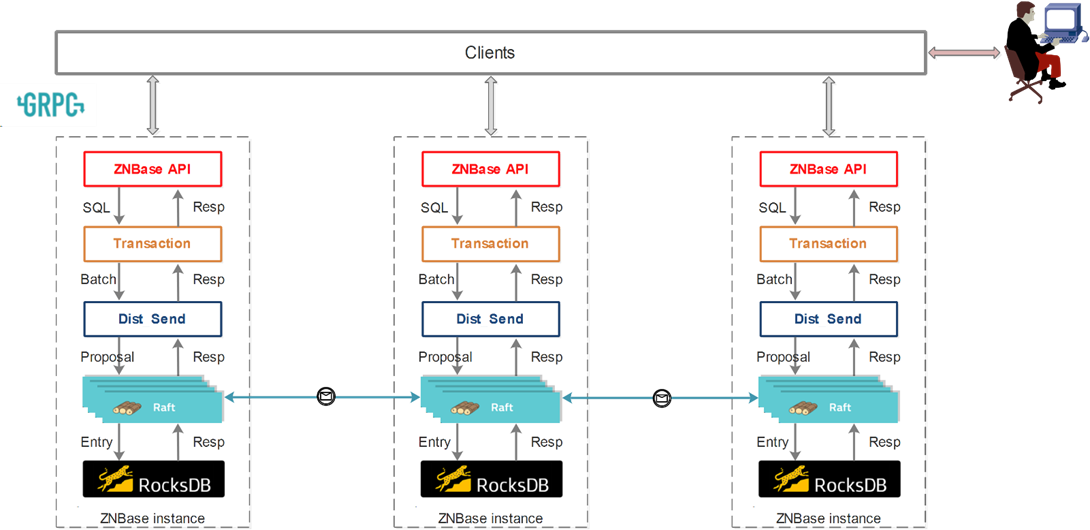
图7 云溪数据库的整体架构
利用单机的 RocksDB,云溪数据库可以将数据快速地存储在磁盘上;利用 Raft算法,可以快速地将数据复制到多台机器上,以防单机故障。数据的写入是通过Raft算法接口写入,而不是直接写RocksDB。通过Raft算法,云溪数据库变成了一个分布式的键值存储系统,不超过集群半数的机器故障宕机完全能够通过Raft 算法自动把副本补全,可以做到业务对故障无感知。在前期,云溪数据库中Raft算法采用的是开源的etcd-raft模块[4],该模块主要提供如下几点功能:
-
Leader选举;
-
成员变更,可以细分为:增加节点、删除节点、Leader转移等;
-
日志复制。
云溪数据库利用etcd-raft模块进行数据复制,每条数据操作都最终转化成一条 RaftLog,通过 RaftLog复制功能,将数据操作安全可靠地同步到Raft Group中的每一个节点上。不过在实际操作中,根据 Raft 的协议,只需要同步复制到多数节点,即可安全地认为数据写入成功。
Part 3 - Raft Log分离与定制存储
在etcd-raft模块中,Raft Group中的Leader节点接收客户端发来的Request,将Request封装成Raft Entry(Raft Log的基本组成单元)追加到本地,并通过gRPC将Raft Entry发送给Raft Group中其他Follower节点,当Follower节点收到Raft Entry后进行追加、刷盘以及回复处理结果的同时,Leader将本地Raft Entry进行刷盘,两者同步进行。等Leader节点收到过半数节点的肯定回复后,提交Raft Entry并将其应用到状态机(将Raft Entry中包含的业务数据进行持久化),然后将处理结果返回客户端。
从上面的分析中可以看出RaftLog在副本之间达成共识、节点重启以及节点故障恢复等环节都起到至关重要的作用,RaftLog与业务数据共同存储在同一个RocksDB中,在查询高峰期必然会发生磁盘I/O资源争抢,增加查询等待时延,降低数据库的整体性能。在TPCC场景下进行了Raft Log与业务数据写入量的测试,测试场景如下:在物理机(CPU:6240 72核 内存:384G 系统硬盘:480G 数据盘:375G+SSD硬盘:2T*7)上启动单节点云溪数据库服务,系统稳定后init 6000仓TPCC数据,观察整个过程中业务数据与Raft Log写入量的大小,测试结果如表1所示。
表1 TPCC 初始化过程数据量统计

同时开展了TPCC场景下针对Raft Log各项操作数量的测试,测试场景如下:启动3个节点的云溪数据库集群,系统稳定后init 40仓TPCC数据,观察网关节点在整个初始化过程中Raft Log各项操作数量的变化,测试结果如表2所示。将RaftEntryCache的大小从16MiB增加到1GiB后,相同场景下Term与Entry的查询数量下降到0。
表2 TPCC 初始化过程Raft Log各项操作统计

![]()
根据上述测试以及测试结果,可将云溪数据库中Raft Log的操作特点总结如下:
1. 在正常运行过程中,插入和删除操作是最多的且数量也很接近,说明Raft Log持久化的时间很短。查询RaftLogSize也是较为常规操作,其他操作都是在特殊场景下触发的,几乎可以忽略不计。
2. 查询Term与查询Entry的操作次数取决于RaftEntryCache的大小,是由云溪数据库内部实现机制决定的,Entry和Term的查询一般先去Unstable中查找,查找不到再去RaftEntryCache中查找,还是查找不到就到底层存储中查找。通常情况下RaftEntryCache大小设置合理的话可以命中所有查找。
3. 云溪数据库实际运行过程中产生的Raft Log比真正持久化的业务数据多很多(5~10倍),而且只要数据库持续运行(即使没有任何用户查询)就会源源不断的产生Raft Log。Raft Log是用户数据的载体,为了保证数据完整性和一致性Raft Log必须持久化。
4. 云溪数据库中存储raft Log的引擎面临的真正挑战是频繁写入、删除以及短暂的存储给系统带来的性能损耗。
通过对云溪数据库中Raft Log操作场景的详细分析,总结Raft Log存储引擎应该满足如下特征:
-
尽可能将待查询数据保存在内存中,减少不必要磁盘I/O;
-
写入的数据能够及时落盘,保证故障恢复后数据的完整性和一致性;
-
能够及时地清理被删除数据或是延迟清理被删除数据,减少不必要的资源占用。
针对这个问题,目前一些主流DB的解决方案是:每个 KV 实例中有两个 RocksDB 实例,一个用于存储 Raft 日志(通常被称为 raftdb),另一个用于存储用户数据以及 MVCC 信息(通常被称为 kvdb)。同时,还开发了基于RocksDB的高性能单机Key-Value 存储引擎。在云溪数据库中直接使用RocksDB来存储Raft Log是不合适的,不能很好地满足Raft Log的具体使用场景。RocksDB内部采用LSMTree存储数据,在Raft Log频繁写入快速删除并且还会持续进行随机查询的场景下,造成严重读放大和写放大,不能够充分发挥出RocksDB的优势,也对系统整体性能造成不利影响。
研发团队在详细调研分析LevelDB、RocksDB、BadgerDB、FlashKey以及Aerospike等的具体架构与特征后,决定基于BadgerDB v2.0的基础上进行定制优化,作为云溪数据库中Raft Log的专用存储引擎。Raft Log定制存储实现了以下基本功能:
-
Raft Log的批量写入与持久化;
-
Raft Log的顺序删除与延迟GC;
-
Raft Log的迭代查询,包括:RaftLogSize查询、Term查询、LastIndex查询以及Entry查询;
-
相关Metrics的可视化;
-
多引擎场景下的用户数据完整与一致保证策略。
云溪数据库中RaftLog定制存储整体部署架构如图8所示:
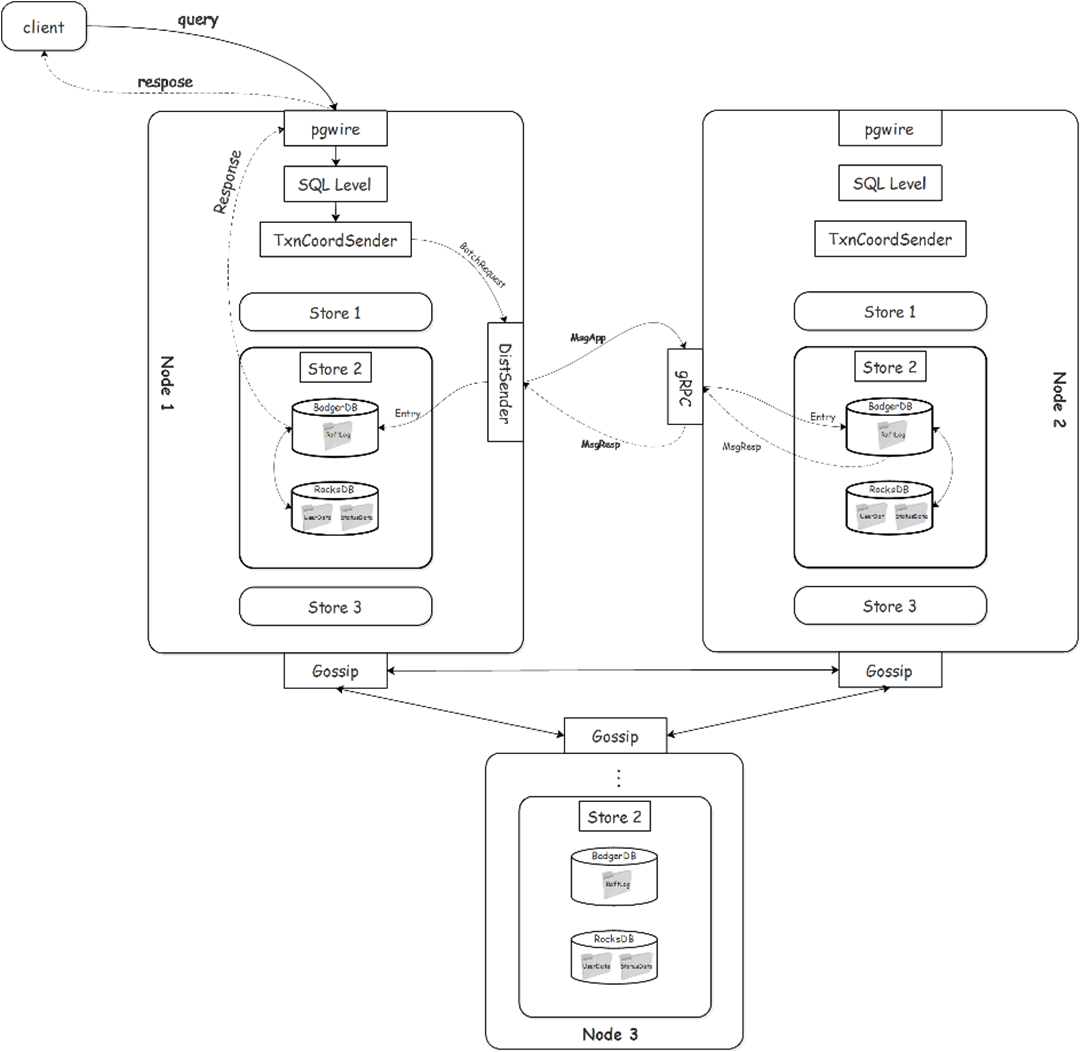
图8 Raft Log定制存储整体部署架构
部署时BadgerDB需要与RocksDB并列进行部署,即一个Node上部署相等数量的RocksDB实例和BadgerDB实例(由目前云溪数据库中副本平衡策略所决定)。查询请求的大致处理流程是先将Raft Log写入BadgerDB,等待集群过半数节点达成共识后,再将Raft Log应用到状态机,即将Raft Log转化成用户数据写入到RocksDB,用户写入成功后再将BadgerDB中已应用的Raft Log删除,同时将状态数据更新到RocksDB中。
云溪数据库中Raft Log定制存储的写、读流程如图9所示。
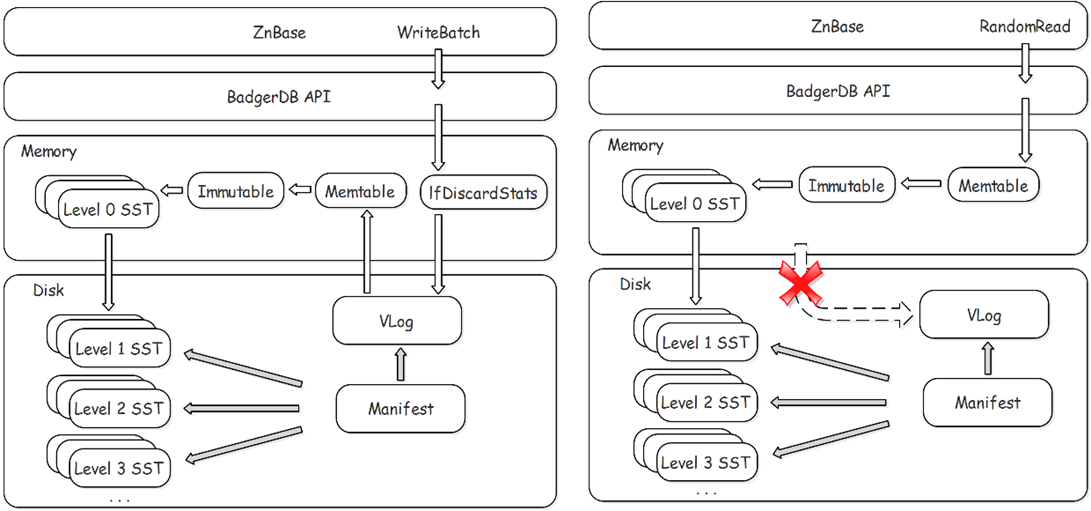
图9 RaftLog 定制存储写、读流程
由于Raft Log定制存储采用Key-Value分离的策略,完整的Key-Value数据首先写入VLog并落盘(如果是删除操作则在落盘成功后由IfDiscardStats更新内存中维护各VLog File的删除数据的统计信息,这些统计信息也会定期落盘。避免了BadgerDB中SSTable压缩不及时导致统计信息滞后的问题),然后将Key以及元数据信息写入Memtable(skiplist)。将Level 0 SSTable放入内存,同时将需要频繁查询的信息(RaftLogSize、Term等)记录到元数据放入内存,加快随机读取的效率,减少不必要的I/O。
已删除Key的清理依赖SSTable的压缩,对应Value的清理则需要云溪数据库周期性调用接口,首先根据访问IfDiscardStats在内存中维护的VLog file的discardStats,对备选文件进行排序,顺序遍历进行采样,若可以进行GC则遍历VLog File中的Entry,同时到Mentable(或SSTable)查看最新元数据信息确定是否需要进行重写,需要重写则写入新的VLog File,不需要则直接跳过,Raft Log定制存储中GC处理流程如图10所示。
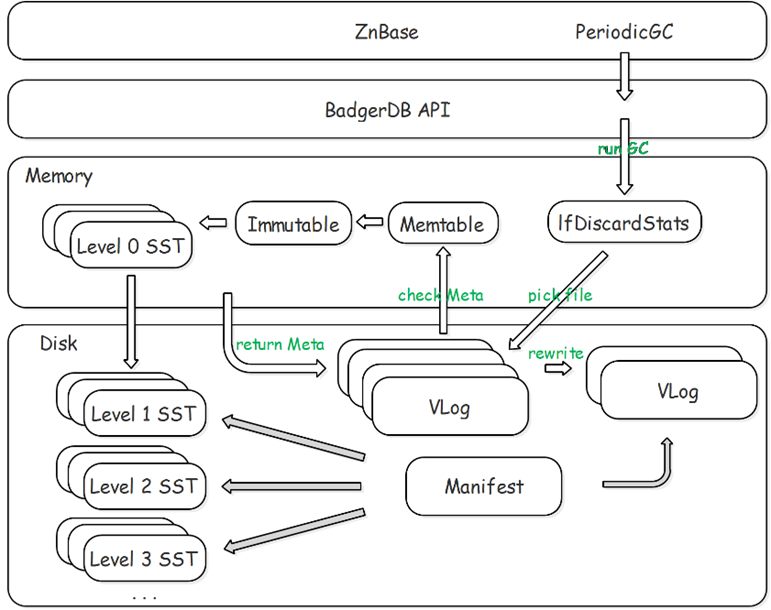
图 10 RaftLog定制存储VLog GC流程
在将Raft Log进行独立储存后,必须要考虑多个存储引擎数据保持一致性的策略。Raft Log存在的目的是为了保证业务数据的完整,因此在Raft Log与业务数据分开存储后不追求两者完全一致,而是Raft Log保持一定的“冗余”。具体策略是每个range上先将AppliedIndex以及对应的Term同步写磁盘,当RaftLog积累到一定数量后再去磁盘上读取前面落盘AppliedIndex以及对应的Term进而生成TruncateState进行RaftLog的删除。
研发团队完成上述优化后,开展了“迭代查询性能对比测试”与“TPCC场景性能测试”。在“迭代查询性能对比测试”中,测试场景如下:启动单机单节点云溪数据库服务,系统稳定运行后init 40仓TPCC数据,记录迭代器查询RaftLogSize与Term的总耗时。Raft Log分别存储在RocksDB、BadgerDB以及Raft Log定制存储中,其中ValueThreshold设置为1KB,其他设置均采用默认值。
表3 迭代查询测试结果汇总

从上述测试结果来看,在对Badger迭代器进行优化后,针对元数据的迭代查询速率得到大幅提升,相比RocksDB迭代查询延迟降低了约90%。
在“TPCC场景性能测试”中,测试场景如下:在物理机(CPU:6240 72核 内存:384G 系统硬盘:480G 数据盘:375G+SSD硬盘:2T*7)启动单节点云溪数据库服务,系统稳定后init 6000仓TPCC数据,观察整个过程中相应监控指标。
表4 TPCC压测监控数据汇总表

从上述测试结果来看,Raft Log采用定制存储后,raft Log提交延迟下降约60%,raft Log应用延迟下降约25%,RocksDB读放大下降约60%(高负载),同时没有明显增加资源消耗。
综上,利用键值分离的思想优化LSM树,借助索引模块提升迭代查询性能,使用统计前置的策略提升系统GC的效率,能够很好满足云溪数据库中Raft Log在各种操作场景下的性能要求。
Part 4 - 后续优化
与故障重启有关的状态数据迁移至BadgerDB,进一步减少RocksDB数据的写入量。
利用RaftLog与部分状态数据替换RocksDB的WAL,BadgerDB承担集群故障恢复功能,为后续RocksDB进一步优化扫清障碍。
优化RaftLog缓存,提升缓存命中率减少非必要的读盘,在将状态数据引入到BadgerDB后,进一步优化写入、查询性能优化,例如:并行写MEMTable等。
[1] https://dgraph.io/blog/post/badger/
[2] https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
[3] https://raft.github.io/raft.pdf
[4] https://github.com/etcd-io/etcd
|








- 上一条: openGauss数据库性能调优概述及实例分析 2022-05-09
- 下一条: 一个小操作,SQL查询速度翻了1000倍。 2022-05-10
- 分布式数据库排序及优化 2022-03-07
- 分布式事务的十大神坑 2021-07-18
- 灵活运用分布式锁解决数据重复插入问题 2021-07-27
- 软硬件结合,分布式数据库 ZNBase 存储架构优化实践 2021-08-10
- 每一个程序员,都渴望成为一名分布式系统架构师 2021-07-11


