云原生分布式数据库事务隔离级别(下)

在前文中,我们已经介绍了事务的相关概念以及事务隔离的不同级别,本文将着重介绍快照隔离的发展。
Part 3 快照隔离的发展
论文 A Critique of ANSI SQL Isolation Levels 中提出了快照隔离(Snapshot Isolation)的定义:
事务的读操作从已提交(Committed)快照中读取数据,快照时间可以是事务的第一次读操作之前的任意时间,记为StartTimestamp;
事务准备提交时,获取一个CommitTimestamp,它需要比现存的StartTimestamp和CommitTimestamp都大;
事务提交时进行冲突检查,如果没有其他事务在[StartTS, CommitTS]区间内提交了与自己的WriteSet有交集的数据,则本事务可以提交;
快照隔离允许事务用很旧的StartTS来执行,从而不被任何的写操作阻塞,或者读一个历史数据。
这里需要注意:
上述时间和空间没有交集的检查,主要是为了阻止LostUpdate的异常;
实现的时候通常利用锁和LastCommit Map,提交之前锁住相应的行,然后遍历自己的WriteSet,检查是否存在一行记录的LastCommit落在了自己的[StartTS, CommitTS]内;
如果不存在冲突,就把自己的CommitTS更新到LastCommit中,并提交事务释放锁。
仔细考虑上述快照隔离的定义,考虑如下几个问题:
CommitTS的获取:如何得到一个比现有的StartTS和CommitTS都大的时间戳,尤其是在分布式系统中;
StartTS的获取:虽然上面提到的StartTS可以是一个很旧的时间,那么StartTS是否需要单调递增;
提交时进行的冲突检查是为了解决Lost Update异常,那么对于这个异常来说,写写冲突检查是否是充分且必要的;
分布式、去中心的快照隔离级别该怎样实现。
针对上述问题,下面进行展开。这里将上述提到的快照隔离(SI)记为Basic SI。
分布式快照隔离
本节主要讲解HBase、Percolator以及Omid在快照隔离方面工程实践进展。
HBase
HBase中快照隔离是完全基于多个HBase表来实现的分布式SI:
Version Table:记录一行数据的最后的CommitTS;
Committed Table:记录CommitLog,事务提交时将commit log写到这张表中可认为Committed;
PreCommit Table:用作检查并发冲突,可理解为锁表;
Write Label Table:用于生成全局唯一的Write Label;
Committed Index Table:加速StartTS的生成;
DS:实际存储数据。
协议大致实现如下:
StartTS:从Committed Table中遍历找到单调连续递增的最大提交时间戳,即前面不存在空洞(这里的空洞指的是事务拿了CommitTS但没有按照CommitTS顺序提交);
Committed Index:为了避免获取StartTS过程遍历太多数据,每个事务在获得StartTS之后会写到Committed Index Table中,之后的事务从这个时间戳开始遍历即可,相当于缓存了一下;
read:需要判断一个事务的数据是否提交了,去VersionTable和Committed Table检查;
precommit: 先检查Committed Table是否存在冲突事务,然后在PreCommit Table记录一行,再检查PreCommitTable中是否存在冲突的事务;
commit:拿到一个commitTS,在CommittedTable写一条记录,更新PreCommit Table。
HBase采用结构上解耦的方式实现分布式SI,所有的状态都存储到HBase中,每个场景的需求都用不同的表来实现,但这种解耦也带来了性能损失。这里将HBase实现的快照隔离记为HBaseSI。
Percolator
在2010年提出的Percolator在HBase的基础上更加工程化,将涉及到的多个Table合并成了一个,在原有数据的基础上增加了lock、write列:
lock:用作是WW冲突检查,实际使用时lock会区分Primary Lock和Secondary Lock;
write:可理解为commit log,事务提交仍然走2PC,Coordinator决定Commit时会在write列写一条commit log,写完之后事务即认为Committed。
同时,作为一个分布式的SI方案,仍然需要依赖2PC实现原子性提交;而prewrite和commit过程,则很好地将事务的加锁和2PC的prepare结合到一起,并利用Bigtable的单行事务,来避免了HBaseSI方案中的诸多冲突处理。这里将Percolator实现的快照隔离记为PercolatorSI。
Omid
Omid是Yahoo的作品,同样是基于HBaseSI,但和Percolator的Pessimistic方法相比,Omid是一种Optimistic的方式。其架构相对优雅简洁,工程化做得也不错,近几年接连在ICDE、FAST、PVLDB发表文章。
Percolator的基于Lock的方案虽然简化了事务冲突检查,但是将事务的驱动交给客户端,在客户端故障的情况下,遗留的Lock清理会影响到其他事务的执行,并且维护额外的lock和write列,显然也会增加不小的开销。而Omid这样的Optimistic方案完全由中心节点来决定Commit与否,在事务Recovery方面会更简单;并且,Omid其实更容易适配到不同的分布式存储系统,侵入较小。
ICDE 2014 的文章奠定Omid架构:
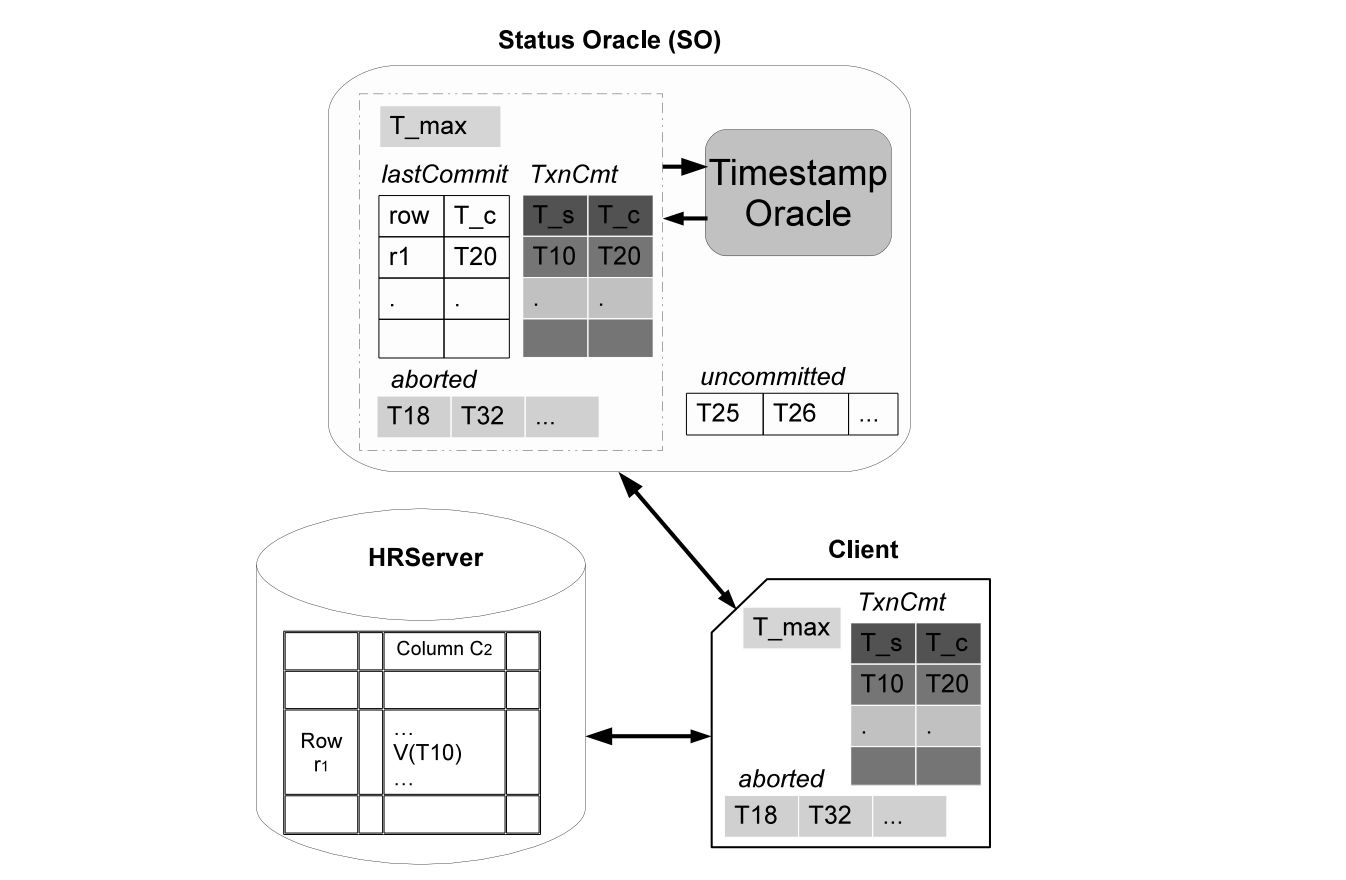
TSO(TimestampOracle):负责时间戳分配、事务提交;
BookKeeper: 分布式日志组件,用来记录事务的Commit Log;
DataStore:用HBase存储实际数据,也可适配到其他的分布式存储系统。
TSO维护如下几个状态:
时间戳:单调递增的时间戳用于SI的StartTS和CommitTS;
lastCommit: 所有数据的提交时间戳,用于WW冲突检测,这里会根据事务的提交时间进行一定裁剪,使得在内存中能够存下;
committed:一个事务提交与否,事务ID用StartTS标识,这里记录StartTS -> CommitTS的映射即可;
uncommitted:分配了CommitTS但还未提交的事务;
T_max:lastCommit所保留的低水位,小于这个时间戳的事务来提交时一律Abort。
这里的lastCommit即关键所在,表明了事务提交时不再采用和Percolator一样的先加锁再检测冲突的Pessimistic方式,而是:
将Commit请求发到TSO来进行Optimistic的冲突检测;
根据lastCommit信息,检测一个事务的WriteSet是否与lastCommit存在时间和空间的重叠。如果没有冲突,则更新lastCommit,并写commit log到BookKeeper;
TSO的lastCommit显然会占用很多内存,并且成为性能瓶颈。为此,仅保留最近的一段lastCommit信息,用Tmax维护低水位,小于这个Tmax时一律abort。
另外提出了一个客户端缓存Committed的优化方案,减少到TSO的查询;在事务的start请求中,TSO会将截止到start时间点的committed事务返回给客户端,从而客户端能够直接判断一个事务是否已经提交,整体架构如下图所示。
![]()
在FAST 2017中,Omid对之前的架构进行了调整,做了一些工程上的优化:
commit log不再存储于BookKeeper,而是用一张额外的HBase表存储;
客户端不再缓存committed信息,而是缓存到了数据表上;因此大部分时候,用户读数据时根据commit字段就能够判断这行数据是否已经提交了。
在PLVDB 2018中,Omid再次进行了大幅的工程优化,覆盖了更多的场景:
Commit Log不再由TSO来写,而是offload到客户端,提高了扩展性,也降低了事务延迟;
优化单行读写事务,在数据上增加一个maxVersion的内存记录,实现了单行的读写事务不再需要进行中心节点校验。
去中心化快照隔离
上述都是针对分布式SI的实现,它们都有一个共同特征:保留了中心节点,或用于事务协调,或用于时间戳分配。对于大规模或者跨区域的事务系统来说,这仍然存在风险。针对这点,就有了一系列对去中心化快照隔离的探索。
Clock-SI
Clock-SI首先指出,Snapshot Isolation的正确性包含三点:
Consistent Snapshot:所谓Consistent,即快照包含且仅包含Commit先于SnapshotTS的所有事务;
Commit Total Order:所有事务提交构成一个全序关系,每次提交都会生成一个快照,由CommitTS标识;
Write-Write Conflict: 事务Ti和Tj有冲突,即它们WriteSet有交集,且[SnapshotTS, CommitTS]有交集。
基于这三个点,Clock-SI提出了如下的算法:
StartTS:直接从本地时钟获取。
Read:当目标节点的时钟小于StartTS时,进行等待,即下图中的Read Delay;当事务处于Prepared或者Committing状态时,也进行等待;等待结束之后,即可读小于StartTS的最新数据;这里的Read Delay是为了保证Consistent Snapshot。
CommitTS:区分出单Partition事务和分布式事务,单Partition事务可以使用本地时钟作为CommitTS直接提交;而分布式事务则选择max{PrepareTS}作为CommitTS进行2PC提交;为了保证CommitTS的全序,会在时间戳上加上节点的id,和Lamport Clock的方法一致。
Commit:不论是单partition还是多partition事务,都由单机引擎进行WW冲突检测。
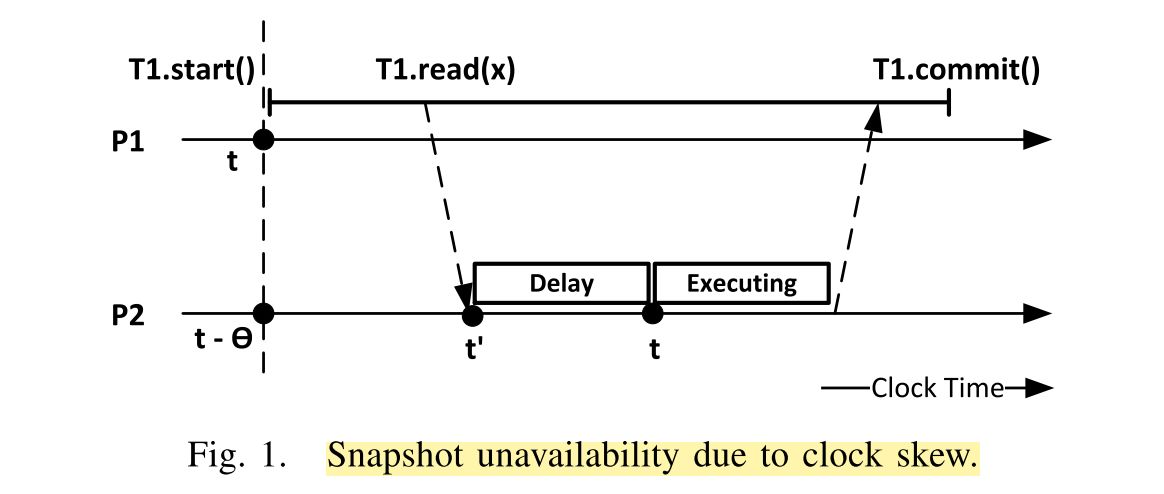
Clock-SI有几点创新:
使用普通的物理时钟,不再依赖中心节点分配时间戳。
对单机事务引擎的侵入较小,能够基于一个单机的Snapshot Isolation数据库实现分布式的SI。
区分单机事务和分布式事务,几乎不会降低单机事务的性能,分布式使用2PC进行原子性提交。
在工程实现中,还需考虑这几个问题:
StartTS选择:可以使用较旧的快照时间,从而不被并发事务阻塞;
时钟漂移:虽然算法的正确性不受时钟漂移的影响,但时钟漂移会增加事务的延迟,增加abort rate;
Session Consistency:事务提交后将时间戳返回给客户端记为latestTS,客户端下次请求带上这个latestTS,并进行等待。
论文实验结果很突出,不过正确性论证较为简略,还有待进一步证明。
ConfluxDB
如果说Clock-SI还有什么不足,那可能就是依赖了物理时钟,在时钟漂移的场景下会对事务的延迟和abort rate造成影响。能否不依赖物理时钟,同时又能够实现去中心化呢?
ConfluxDB提出的方案中,仅仅依赖逻辑时钟来捕获事务的先于关系,基于先于关系来检测冲突:
当事务Ti准备提交时,2PC的Coordinator向所有参与者请求事务的concurrent(Ti)列表,这里的concurrenct(Ti)定义为begin(Tj) < commit(Ti)的事务;
Coordinator在收到所有参与者的concurrent(Ti)之后,将其合并成一个大的gConcurrent(Ti),并发回给所有参与者;
参与者根据gConcurrent(Ti),检查是否存在一个事务Tj,dependents(Ti,Tj) ∧ (Tj ∈ gConcurrent(Ti)) ∧ (Tj ∈ serials(Ti)),即存在一个事务Tj,在不同的partition中有不同的先后关系,违背了Consistent Snapshot的规则;
参与者将冲突检测的结果发回给Coordinator,Coordinator据此决定是Commit还是Abort;
除此之外Coordinator需要给这个事务生成一个CommitTS,这里选择和ClockSI类似的方式,commitTS=max{prepareTS},这里的prepareTS和commitTS会按照Logical Clock的方式在节点之间传递。
ConfluxDB的这种方案不需要依赖物理时钟,不需要任何wait,甚至不需要单机的事务引擎支持读时间点快照的功能。但是这个方案的不足是,可能Abort rate并不是很好,以及在执行分布式事务时的延迟问题。
Generalized SI
Generalized SI将Snapshot Isolation应用到Replicated Database中,使得事务的Snapshot可以从复制组的从节点读取。这带来的意义有两点,使用一个旧的快照,不会被当前正在运行的事务阻塞,从而降低事务延迟;而从Secondary节点读取数据,则可以实现一定程度上的读写分离,扩展读性能。
Parallel SI
上面的方案中,可以将读请求offload到Secondary节点,一定程度上能够扩展读性能。那么继续将这个思路延伸一下,能不能把事务的提交也交给Secondary节点来执行呢?
这就是Parallel Snapshot Isolation的思路,在跨区域复制的场景下,业务通常会有地理位置局部性的要求,在上海的用户就近把请求发到上海的机房,在广州的用户把请求发到广州的机房;并且在实际的业务场景中,往往可以放松对一致性和隔离性的要求。Parallel放弃了Snapshot Isolation中对Commit Total Order的约束,从而实现了多点的事务提交。在通用数据库中可能很难使用这样的方案,但实际的业务场景中会很有价值。
Serializable SI
Snapshot Isolation所区别于Serializable的是Write Skew异常,为了解决这个异常,可以基于Snapshot Isolation进行优化,并且尽量保留Snapshot Isolation的优秀性质,进而提出了Serializable SI。
论文 Serializable isolation for snapshot databases 是 Alan D. Fekete 和 Michael J. Cahill 在2009年发表的,是早期研究SSI的理论成果。
论文从串行化图理论说起,在Multi-Version的串行图中,增加一种称之为RW依赖的边,即事务T1先写了一个版本,事务T2读了这个版本,则产生RW依赖。当这个图产生环时,则违背了Serializable。
在论文中作者证明,SI产生的环中,两条RW边必然相邻,也就意味着会有一个pivot点,既有出边也有入边。那么只要检测出这个pivot点,选择其中一个事务abort掉,自然就打破了环的结构。算法的核心就在于动态检测出这个结构,因此会在每个事务记录一些状态,为了减少内存使用,使用inConflict和outConflict两个bool值来记录;在事务执行读写操作的过程中,会将与其他事务的读写依赖记录于这两个状态中。
虽然用bool值减少了内存使用,但显然也增加了false positive,会导致一部分没有异常的事务被abort。
据文中的实验结果表明,性能好于S2PL(严格两阶段锁,可实现串行化),abort较低,给Snapshot Isolation带来的开销也比较小。
但据后来的PostgreSQL的SSI实现,为了减少内存占用仍需要不少的工作量,有兴趣可参考 Serializable Snapshot Isolation in PostgreSQL。
Write SI
Yabandeh在 论文 A critique of snapshot isolation 中提出Write-Snapshot Isolation。作者首先批判Basic SI,因为Basic SI给人造成了一种误导:进行写写冲突检测是必须的。文章开篇即提出,SI中的LostUpdate异常,不一定需要阻止WW冲突;换成RW检测,允许WW冲突,既能够阻止LostUpdate异常,同时能够实现Serializable,一举两得。
为何WW检测不是必须的?简要论证一下,在MVCC中,写冲突的事务写的是不同的版本,为何一定会有冲突?实际上只有两个事务都是RW操作时才有异常,如果其中一个事务只有W操作,并不会出现Lost Update;换言之,未必要检测WW冲突,RW冲突才是根源所在。
基于RW冲突检测的思想,作者提出Write Snapshot Isolation,将之前的Snapshot Isolation命名为Read Snapshot Isolation。如下图中:
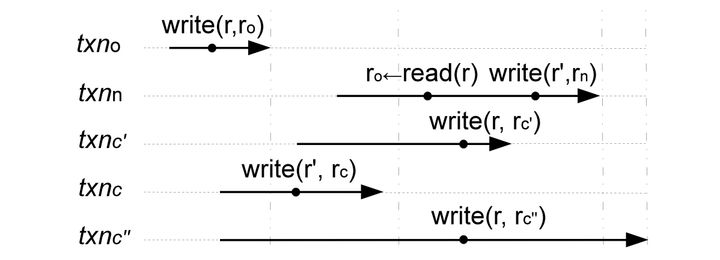
TXNn和TXNc'有冲突,因为TXNc'修改了TXNn的ReadSet;
TXNn和TXNc没有冲突,虽然他们都修改了r'这条记录,Basic SI会认为有冲突,但Write SI认为TXNc没有修改TXNn的ReadSet,则没有RW冲突。
如何检测RW冲突:事务读写过程中维护ReadSet,提交时检查自己的ReadSet是否被其他事务修改过。但实际也不会这么简单,因为通常维护ReadSet的开销比WriteSet要大,且这个冲突检查如何做,难道加读锁?所以在原文中,作者只解释了中心化的Write SI如何实现(BadgerDB使用了这个算法,实现了支持事务的KV引擎)。至于去中心化的实现,可从CockroachDB找到一点影子。
不过RW检测会带来很多好处:
只读事务不需要检测冲突,它的StartTS和CommitTS一样;
只写事务不需要检测冲突,它的ReadSet为空;
更重要的是,这种算法实现的隔离级别是Serializable而不是Snapshot Isolation。
综合上述内容,为实现串行化,传统上只能采用基于锁的并发控制,由于性能问题,很难在实际工程中应用。Serializable SI为高性能的实现可串行化,提供了一种新的路径。
以上内容主要参考 Snapshot Isolation综述。
写在最后
在wiki上PostgreSQL对SSI解释有这么一句话:Documentation of Serializable Snapshot Isolation (SSI) in PostgreSQL compared to plain Snapshot Isolation (SI). These correspond to the SERIALIZABLE and REPEATABLE READ transaction isolation levels, respectively, in PostgreSQL beginning with version 9.1。因此,在讨论任何一款数据库产品实现的隔离级别时,必须了解该隔离级别背后实现的算法原理。
参考文献
1. (https://book.douban.com/subject/26851605/)
2. (https://cs.uwaterloo.ca/~ddbook/)
3. (https://cs.uwaterloo.ca/~ddbook/)
4. (https://dl.acm.org/doi/abs/10.1145/568271.223785)
5. (https://zhuanlan.zhihu.com/p/54979396)
6. (https://zhuanlan.zhihu.com/p/37087894)
7. (https://dgraph.io/blog/post/badger-txn/)
8. (https://wiki.postgresql.org/wiki/SSI)
|








- 上一条: 使用虚拟机在CentOS上安装部署数据库使用 2022-01-13
- 下一条: 近数据处理(NDP)——GaussDB(for MySQL)性能提升的秘密 2022-01-13
- 云原生分布式数据库事务隔离级别(上) 2022-01-10
- 云溪云原生分布式数据库安全功能以及实现介绍 2022-01-17
- 分布式事务的十大神坑 2021-07-18
- 分布式数据库排序及优化 2022-03-07
- 云溪分布式数据库事务并发控制介绍 2021-12-29


