云溪分布式数据库事务并发控制介绍

1.事务并发控制原理概述
1.1为什么要进行并发控制
数据库是共享资源,通常有许多个事务同时在运行。当多个事务并发地存取数据库时就会产生同时读取和/或修改同一数据的情况。若对并发操作不加控制就可能会存取和存储不正确的数据,破坏数据库的一致性。所以数据库管理系统必须提供并发控制机制。
下图左事务T2在t6时刻的写操作W(A)将事务T1在t5时刻的写操作覆盖了,造成事务T1的更新丢失;下图右事务T2读到了事务T1回滚了的写操作,该数据不合法,称为脏读。除此之外,由于事务的并发执行,还会产生不可重复读、幻读、读写偏序等问题,在此不一一介绍。
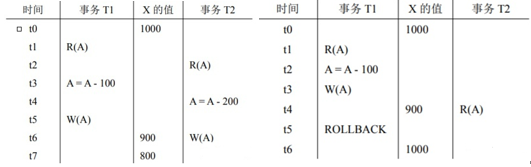
图1 左为更新丢失,右为脏读
数据库为了提高资源利用率和事务执行效率、降低响应时间,允许事务并发执行。但是多个事务同时操作同一对象,必然存在冲突,事务的中间状态可能暴露给其它事务,导致一些事务依据其它事务中间状态,把错误的值写到数据库里。需要提供一种机制,保证事务执行不受并发事务的影响,让用户感觉,当前仿佛只有自己发起的事务在执行,这就是隔离性。由于隔离性对事务的执行顺序要求较高,很多数据库提供了不同选项,用户可以牺牲一部分隔离性,提升系统性能。这些不同的选项就是事务隔离级别。事务的隔离级别一般划分为四个,由低到高分别为:读未提交、读已提交、可重复读、串行化。最终的目的是将并发执行的事务按照合理的顺序做到逻辑上的串行操作,避免按照时序执行破坏数据库的一致性。
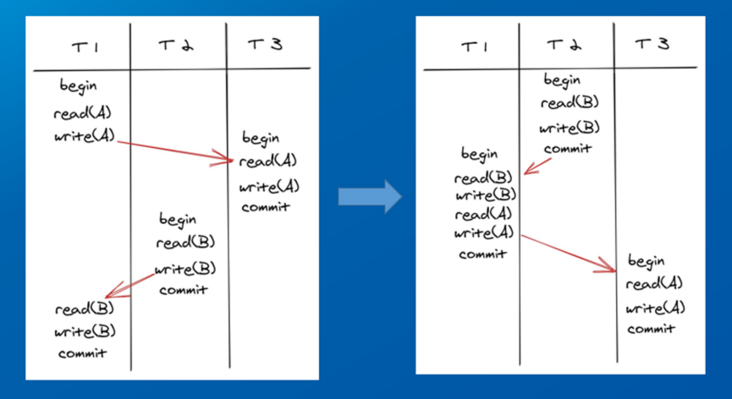
图2 并发操作的串行执行顺序
1.2 常用的并发控制方方式
常用的并发控制有锁、时间戳、有效性检查、快照、多版本机制,在此我们介绍几个和云溪数据库相关的并发控制。
1.2.1 锁
为了最大化数据库事务的并发能力,数据库中的锁被设计为两种模式,分别是共享锁和互斥锁。当一个事务获得共享锁之后,它只可以进行读操作,所以共享锁也叫读锁;而当一个事务获得一行数据的互斥锁时,就可以对该行数据进行读和写操作,所以互斥锁也叫写锁。如果当前事务没有办法获取该行数据对应的锁时就会陷入等待的状态,直到其他事务将当前数据对应的锁释放才可以获得锁并执行相应的操作。
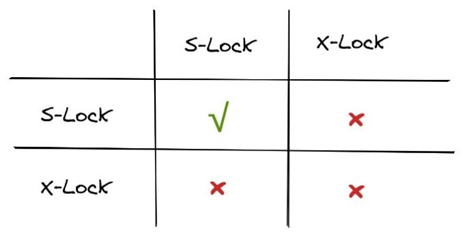
图3 互斥锁和共享锁的相容性
两阶段锁协议(2PL)是一种能够保证事务可串行化的协议,它将事务的获取锁和释放锁划分成了增长(Growing)和缩减(Shrinking)两个不同的阶段。在增长阶段,一个事务可以获得锁但是不能释放锁;而在缩减阶段事务只可以释放锁,并不能获得新的锁。
死锁在多线程编程中是经常遇到的事情,一旦涉及多个线程对资源进行争夺就需要考虑当前的几个线程或者事务是否会造成死锁.通过有向等待图是否产生环可以判断是否有死锁产生。如何从死锁中恢复其实非常简单,最常见的解决办法就是选择整个环中一个事务进行回滚,以打破整个等待图中的环。
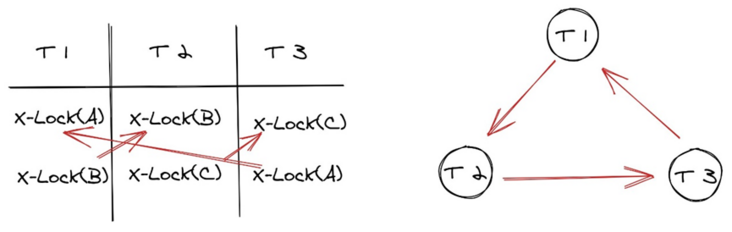
图4 死锁的产生
1.2.2 时间戳
为每个事务分配timestamp,并以此决定事务执行顺序。当事务1的timestamp小于事务2时,数据库系统要保证事务1先于事务2执行基于T/O的并发控制,读写不需加锁, 每行记录都标记了最后修改和读取它的事务的timestamp。当事务的timestamp小于记录的timestamp时(不能读到”未来的”数据),需要abort后重新执行。假设记录X上标记了读写两个timestamp:WTS(X)和RTS(X),事务的timestamp为TTS,可见性判断如下:
读:
TTS < WTS(X):该对象对该事务不可见,abort事务,取一个新timestamp重新开始。
TTS > WTS(X):该对象对事务可见,更新RTS(X) = max(TTS,RTS(X))。为了满足repeatable read,事务复制X的值。
写:
TTS < WTS(X) || TTS < RTS(X):abort事务,重新开始。
TTS > WTS(X) && TTS > RTS(X): 事务更新X,WTS(X) = TTS。
它缺陷包括:长事务容易饿死,因为长事务的timestamp偏小,大概率会在执行一段时间后读到更新的数据,导致abort;读操作也会产生写(写RTS)。
1.2.3 多版本并发控制
数据库维护了一条记录的多个物理版本。事务写入时,创建写入数据的新版本,读请求依据事务/语句开始时的快照信息,获取当时已经存在的最新版本数据。它带来的最直接的好处是:写不阻塞读,读也不阻塞写,读请求永远不会因此冲突失败(例如单版本T/O)或者等待(例如单版本2PL)。对数据库请求来说,读请求往往多于写请求。主流的数据库几乎都采用了这项优化技术。

图5 多版本并发读写操作
2. 云溪数据库并发控制机制
云溪数据库采用Percolator的并发控制模型,云溪数据库中的值不直接写入存储层; 相反,所有东西都是以临时状态写成的,称为“Write Intent”,并添加了一个附加值,用于标识值所属的事务记录(transaction record)。每当操作遇到Write Intent时,它会查找事务记录的状态以了解它应如何处理Write Intent值。
2.1事务记录
为了跟踪事务执行的状态,我们将一个事务记录的值写入KV存储,事务所有的write intents都指向该记录,该记录允许所有事务检查它们遇见的write intents。这个在分布式环境中对并发性支持很重要。事务记录表达了以下事务的状态之一:
- PENDING: 所有值的初始状态,表示Write Intent的事务仍在进行中。
- COMMITTED: 事务完成后,此状态表示可以读取该值。
- STAGING:用于启用并行提交功能。根据此记录引用的写入意图的状态,事务可能处于提交状态,也可能不处于提交状态。
- ABORTED: 如果事务失败或被客户端中止,它将进入此状态。
- Record does not exist:如果事务遇到不存在事务记录的写意图,它将使用写意图的时间戳来确定如何继续。如果写意图的时间戳在事务活跃度阈值内,则写意图的事务将被视为
PENDING,否则将被视为事务ABORTED。
2.2 写意图
它们本质上是多版本的并发控制值(也称为MVCC,在存储层中有更深入的解释),并添加了一个附加值,用于标识值所属的事务记录。可以把它们视为复制锁和复制临时value的组合。
每当操作遇到Write Intent(而不是MVCC值)时,它会查找事务记录的状态以了解它应如何处理Write Intent值。如果事务记录丢失,操作将检查write intents的时间戳,并评估它是否过期。
每当操作遇到key的Write Intent时,它会尝试“解析”它,其结果取决于Write Intent的事务记录:
- COMMITTED: 该操作读取Write Intent并通过删除Write Intent指向事务记录的指针,来将其转换为MVCC值。
- ABORTED: Write Intent被忽略并删除。
- PENDING: 这表示存在事务冲突,必须解决。
- STAGING:需要通过事务协调器去检查这个事务记录的心跳是否还在,如果存在则需要等待
2.3解决冲突
2.3.1写写冲突
1.如果事务具有明确的优先级设置,则比较优先级决定 push操作,优先级高的事务会将优先级低的事务回滚
2.如果没有优先级之分,时间戳大的事务会进入时间戳小的事务的队列中等待事务记录变为committed或者aborted
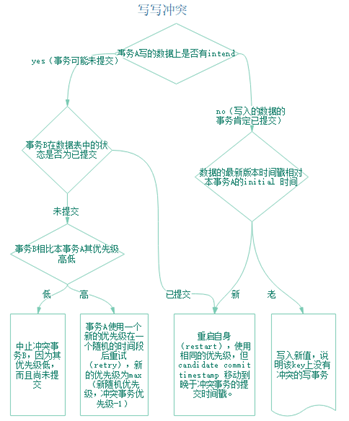
2.3.2写读冲突
1.如果事务具有明确的优先级设置,则比较优先级决定 push操作,优先级高的事务会将优先级低的事务的是时间戳推到高优先级事务之后
2.如果没有优先级之分,时间戳大的事务会进入时间戳小的事务的队列中等待事务记录变为committed或者aborted

2.3.3读后写
读操作读取值的时候都会把读时间戳存储到一个时间戳缓存,该缓存显示读取值的高水位线写操作发生时,对照这个时间戳缓存检查时间戳,如果写事务时间戳小于时间戳缓存最新值,那么就是发生了读后写。写事务时间戳会被后推,该操作可能影响事务发生重启(read refreshing)
3.云溪数据库并发控制器
3.1 为什么要做并发控制器
- 将请求同步处理和事务冲突处理集中在一个位置,允许单独记录、理解和测试主题。
- 简化了事务排队过程,降低了事务推送RPC的频率,并允许等待者在意图解析后立即继续。
- 创建一个锁的框架,可以做kv 级别 SELECT for update 和SELECT for share功能 。
- 当事务发生冲突时,围绕公平性提供更有力的保证,以减少竞争场景下的尾部延迟
3.2 并发控制器基本结构
并发管理器是一种结构,它对传入的请求进行排序,并在发出那些要执行冲突操作的请求的事务之间提供隔离。在排序过程中,通过被动排队和主动推送相结合的方式发现冲突并解决任何发现的冲突。一旦请求被排序,它就可以自由地进行evaluate,而不必担心与其他请求发生冲突。这种隔离在请求的生存期内得到保证,但在请求完成后终止。
事务中的每个请求都应该与其他请求隔离,无论是在请求的生存期内还是在请求完成后(假设它获得了锁),但请求都应该在事务的生存期内。
核心是两部分:latch manager和lock table。
- lm是将request排序,保证他们的隔离性
- lt给request提供锁和排序,它是一个在每个节点内存中的数据结构,保存获得锁的正在进行的事务集合。lock机制要和write intent兼容,所以当请求在evaluate过程中发现了外部锁,则会将这些信息引入。

3.3 并发控制器控制过程
- 从请求 SequenceReq 获取 Latch 保证没有 req 冲突并检查内存 locktable,如果有冲突则释放 latch 后等待对应锁
- 后开始正常执行请求,执行 apply 后会向 locktable 增加当前事务的锁信息
- 并在请求完成后 FinishReq 释放 Latch 继续其他请求
- 最后在事务提交或回滚后的 resolve intent 完成后释放 locktable 中事务占的锁,并唤醒其他等待事务的请求。

3.4 latch manager
latch manager给传入请求进行排序,并在并发管理器的监督下提供这些请求之间的隔离。latch就像一个低级别的持续时间段的mutex
工作方式:
1.某个range的写请求会被这个range的LeaseHolder序列化,置于某种顺序中
2.为了强化这个序列化,LeaseHolder采用对这些写的值采用latch提供无竞争访问
3.其他请求进入LeaseHolder请求被latch锁的同一组key,必须先获取latch才能继续
4.读请求也能产生latch,并且多个读请求对于相同的key可以同时持有latch(相容),但 是读latch和写latch不能相容。
另一种看待latch的方式类似于互斥锁,它只在单个低级请求的持续时间内需要。为了协调运行时间更长、级别更高的请求(即客户端事务),我们使用持久的写意图系统。
3.5 lock table
它是一个在每个节点内存中的数据结构,保存获得锁的正在进行的事务集合。每个锁都有一个与之相关联的队列,等待该锁释放的事务都在里面排队。本地存储的lockWaitQueue中的项目会被RPC传播到现有的TxnWaitQueue上去,该TxnWaitQueue队列存储在事务记录所在的的Raft Group的leader节点上。
并非所有锁都直接存储在管理器的控制下,因此在排序过程中并非所有锁都可以发现。具体来说,write intents(复制的、排他的锁)内联存储在MVCC密钥空间中,因此直到请求evaluation时才可检测到它们。为了适应这种锁存储形式,管理器将有关外部锁的信息集成到并发管理器结构中。
锁的生命周期要大于锁持有者(事务)的生命周期,锁将特定的key上提供的隔离的持续时间延长到锁持有者事务本身的生命周期。它们(通常)仅在事务提交或中止时才被释放。
但是,并非所有锁都直接存储在管理器的控制下,因此在排序过程中并非所有锁都可以发现。具体来说,write intents(复制的、排他的锁)内联存储在MVCC中,因此直到请求evaluation时才可检测到它们。目前,并发管理器在非复制的锁表结构上运行
3.6 TxnWaitQueue
TxnWaitQueue追踪所有他们遇到的无法推动(push)写事务的事务,并且必须等待阻塞事务完成才能继续。他是一个存储阻塞事务ID的数据结构
重点:这些活动发生在单个节点上,该节点是包含事务记录的range的Raft组的leader。
一旦事务确实解决了,一个信号被发送到TxnWaitQueue,它允许被该事务阻塞的所有事务开始执行。
被阻塞的事务会检查自己事务的状态,以确保它们仍处于活动状态。 如果被阻止的事务被中止,则只需将其删除。
如果事务之间存在死锁(即它们各自被彼此的Write Intents阻塞),则其中一个事务被随机中止。
3.7 lockTableWaiter
lockTableWaiter负责lock wait queue中的持有锁的冲突事务,它保证在事务协调器出差或者死锁情况下,请求能够继续进行
waiter实现了请求等待冲突的锁在lock table里面释放的逻辑,类似的,他实现了调用者请求之前的等待冲突请求的逻辑,该锁等待队列是调用者的一部分
此等待状态响应锁表中的一组状态转换:
1.冲突的锁被释放
2.冲突的所被更新使其不再冲突
3.lock wait queue中冲突的请求获得锁
4.lock wait queue中冲突的请求退出lock wait queue
这些状态状态转换通常是反射性的,waiter可以等待锁释放或者被其他参与者退出。
LockManager支持对冲突锁的状态转换作出反应
RequestSequencer接口支持对冲突lock wait-queues的状态转换作出反应
但是,在事务协调器失败或事务死锁的情况下,如果没有waiter的干预,状态转换可能永远不会发生。为了确保向前推进,waiter可能需要主动推送冲突锁的持有者或冲突锁等待队列的头。该行为push需要一个RPC到冲突事务记录的leaseholder,通常会导致RPC在leaseholder的txnWaitQueue中排队。因为这样做的代价很高,所以推送不会立即执行,它只在延迟之后执行。
|








- 上一条: 如何把 MySQL 备份验证性能提升 10 倍 2021-12-28
- 下一条: TDSQL | DB·洞见回顾|基于LSM-Tree存储的数据库性能改进 2021-12-31
- 云溪云原生分布式数据库安全功能以及实现介绍 2022-01-17
- 分布式事务的十大神坑 2021-07-18
- 浪潮云溪分布式数据库 Tracing(二)—— 源码解析 2022-07-07
- 分布式数据库排序及优化 2022-03-07
- 浪潮云溪分布式数据库协议代码解析(1) 2022-05-19


