云溪数据库事务模型简介

一. 架构介绍
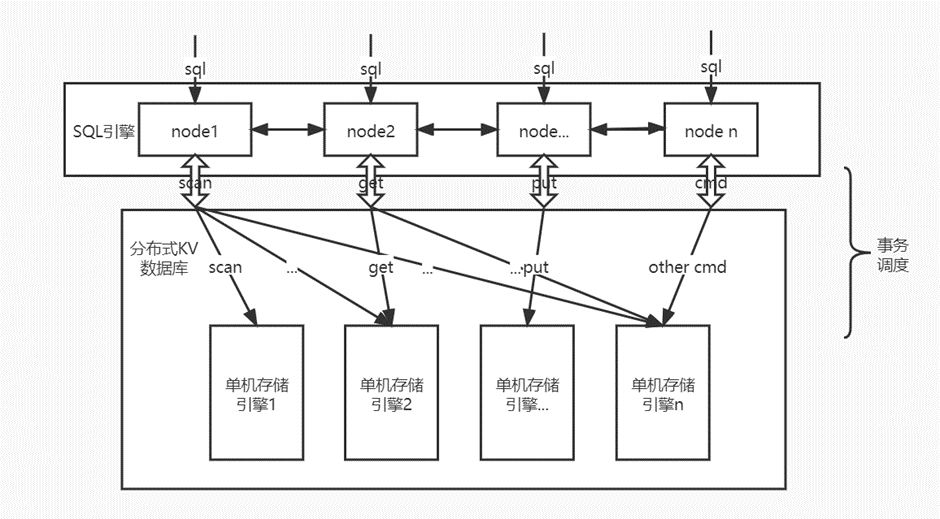
从宏观上看,云溪数据库由两部分组成:上层的SQL引擎和下层的作为一个整体的分布式KV数据库。任何针对于数据库的SQL操作,经过SQL引擎的解析之后,都会把它们分解成一组组的kv操作,比如“select * from t”会被分解成scan操作,”update t set a = 1”会被分解成scan和put(conditionalPut)操作......事务主要是在下层的KV数据库对kv操作进行调度,以完成对更底层的存储引擎的并发读写。
二. Percolar事务模型介绍
云溪数据库的事务模型是从Percolator发展而来。Percolator是构建在BigTable之上的,通过提供一个TSO中央授时服务和一个client lib来封装BigTable的接口,最终将BigTable改造成了一个带有ACID快照隔离语义的支持跨行、跨表事务的分布式多维map。

Percolator的特点是没有集中式的事务处理措施,比如中心事务管理器、全局死锁探测器......事务产生的锁也是和数据关联在一起分布式存储的。就事务的角度而言,全局的唯一单点就是TSO。因此Percolator模型具有良好的水平扩展能力。但是也正式这种无中心的实现方式,导致各种冲突处理都需要通过必要的网络交互来实现,所以事务的延迟相对较高。如果照搬这种实现方式,是无法满足OLTP数据库对于高性能的事务处理的要求的。
三. 云溪数据库事务模型介绍
云溪数据库事务模型是从Percolator发展而来的。一方面,它进一步实现了去中心化,通过使用HLC代替TSO,消除了最后一个单点,是系统的水平扩展能力进一步提高;另一方面,它也做了许多努力来减小Percolator模型事务延迟较高的弊端,比如具体的优化有异步释放锁 、 并行提交 、事务流水线、一阶段提交......

1. 标准时间戳排序协议
云溪数据库通过MVCC+实现戳排序协议实现了SSI的事务隔离级别,下面简单介绍一下时间戳排序协议。
在标准时间戳排序协议中,每个事务都有一个唯一固定的时间戳,在事务开始时获取,读、写、提交都在该时间戳上进行。每个数据项保持两个时间戳,W-timestam表示成功执Write(Q)的所有事务的最大时间戳;R-timestamp表示成功执Read(Q)的所有事务的最大时间戳。
1:假设事务Ti发出read(Q)。
- 若TS(Ti)< W-timestamp(Q),则Ti需要读入的Q值已经被覆盖。因此read操作被拒绝,Ti回滚。
- 若TS(Ti)>= W-timestamp(Q),则执行read操作,R-timestamp(Q)被设置为R-timestamp(Q)于TS(Ti)两者的最大值。
2:假设事务Ti发出write(Q)
- 若TS(Ti)< R-timestamp(Q),则Ti产生的Q值是先前面所需要的值,且系统已经假定该值不会再产生因此,write操作被拒绝,Ti回滚。
- 若TS(Ti)< W-timestamp(Q),则Ti试图写入的Q值已经过时。因此,write操作被拒绝,Ti回滚。
- 其他情况,系统执行write操作,将W-timestamp(Q)设置为TS(Ti)。
2. 标准时间戳排序协议的缺陷
标准时间戳排序协议是一个无锁(free lock)的并发控制协议,读写操作都不需要加锁,这虽然能获得高性能,单却存在级联回滚问题和不可恢复调度。

不可恢复调度问题:当txn1回滚时,txn2本来也应该回滚,因为它读的A是txn1写入的。但是由于txn2已经提交,所以没有办回滚,导致数据的一致性被破坏。
级联回滚问题:txn2依赖txn1,txn3依赖txn2,可能会有txn4依赖txn3……当txn1回滚时,会造成大面积的事务回滚。
为了避免上面这两个问题,云溪数据库会对写入的未提交数据加排他锁,这样在类似上面的场景中,txn2和txn3在读A时会被阻塞,直到txn1提交才回放行。这样就不会产生级联问题和不可恢复调度问题。
3. 云溪数据库对标准时间戳排序协议的优化
时间戳排序协议是一个比较乐观的协议,它假设冲突很少发生,因此在事务开启的时候就确定事务也可以在这个时间戳提交,时间戳排序的冲突处理规则就是建立在这个前提之上的,任何出现违反了这个规则的情况都会导致事务回滚。因此在高并发高冲突的场景中,时间戳排序协议的事务回滚率和回滚代价都是比较高的。为了降低回滚率,云溪数据库引入了时间戳forward(push)机制,规则如下:一个事务维护两个时间戳,readTS和writeTS。事务在readTS上执行所有读取操作,以获取一直性快照;所有的写操作在writeTS发生,当遇到RW冲突时,W事务的writeTS forward到冲突时间戳的ts.next,然后继续执行,在必要时刻或者最终提交时进行检查尝试将readTS refresh到writeTS,如果成功,则事务提交,否则事务回滚。

在这个机制之下,当遇到上图的场景时,由于txn1在commit时能把它的readTS refresh到writeTS,所以txn1还是可以提交。但是在标准的时间戳排序协议中,由于txn1 write(B)时发现B的R-Timestamp大于自己的ts,所以事务txn1需要回滚。
4. 云溪数据库事务模型总结
- 没有单点和集中式处理,扩展性好
- 由于同步点机制,任何冲突都需要访问同步点来确认冲突的最终结果,网络交互多
- 锁和数据一起存储,每个写操作都会给存储引擎产生两三倍的写入压力,冲突处理流程曲折
- HLC的时钟偏移太大,在某些场景下对同一数据的W、R容易导致重试
- 时间戳排序并发控制协议比较乐观、导致事务容易重试和回滚,且代价较大
|








- 上一条: 全链路在线生产数据库压测利器:Apache ShardingSphere 影子库特性升级 2021-12-22
- 下一条: 手把手教你玩 MySQL 删库不跑路,直接把 MySQL 的 binlog 玩溜! 2021-12-28
- 云溪分布式数据库事务并发控制介绍 2021-12-29
- 浪潮云溪分布式数据库 Tracing(二)—— 源码解析 2022-07-07
- 浪潮云溪数据库--关于副本的功能特性和使用方法 2022-02-25
- 云原生分布式数据库事务隔离级别(上) 2022-01-10
- Kubernetes使用云溪数据库简介 2022-02-10


