⭐openGauss数据库源码解析系列文章——AI DeepSQL⭐
❤️大家好,我是Gauss松鼠会,欢迎进来学习啦~❤️
上一篇介绍了 8.6 AI查询时间预测的相关内容,本篇我们介绍“8.7 DeepSQL、8.8 小结”的相关精彩内容介绍。
8.7 DeepSQL
前面提到的功能均为AI4DB领域,AI与数据库结合还有另外一个大方向,即DB4AI。在本章中,我们将介绍openGauss的DB4AI能力,探索通过数据库来高效驱动AI任务的新途径。
使用场景
数据库DB4AI功能的实现,即在数据库内实现AI算法,以更好的支撑大数据的快速分析和计算。目前openGauss的DB4AI能力通过DeepSQL特性来呈现。这里提供了一整套基于SQL的机器学习、数据挖掘以及统计学的算法,用户可以直接使用SQL语句进行机器学习工作。DeepSQL能够抽象出端到端的、从数据到模型的数据研发过程,配合底层的计算引擎及数据库自动优化,让具备基础SQL知识的用户即可完成大部分的机器学习模型训练及预测任务。整个分析和处理都运行在数据库引擎中,用户可以直接分析和处理数据库内的数据,不需要在数据库和其他平台之间进行数据传递,避免在多个环境之间进行不必要的数据移动,并且整合了碎片化的数据开发技术栈。
现有技术
如今,学术界与工业界在DB4AI这个方向已经了取得了许多成果。很多传统的商业关系数据库都已经支持了DB4AI能力,通过内置AI组件适配数据库内的数据处理和环境,可以对数据库存储的数据进行处理,最大程度地减少数据移动的花费。同时,很多云数据库、云计算数据分析平台也都具备DB4AI能力。同时还可能具备Python、R语言等接口,便于数据分析人员快速入门。
在DB4AI领域,同样具备很出色的开源软件,例如Apache顶级开源项目MADlib。它兼容PostgreSQL数据库,很多基于PostgreSQL数据库源码基线进行开发的数据库也可以很容易进行适配。MADlib可以为结构化和非结构化数据提供统计和机器学习的方法,并利用聚集函数实现在分布式数据库上的并行化计算。MADlib支持多种机器学习、数据挖掘算法,例如回归、分类、聚类、统计、图算法等,累计支持的算法达到70多个,在目前发布的1.17版本中MADlib支持深度学习。MADlib使用类SQL语法作为对外接口,通过创建UDF(user-defined function,用户自定义函数)的方式将AI任务集成到数据库中。
当前openGauss的DB4AI模块,兼容开源的MADlib,在原始MADlib开源软件的基础上进行了互相适配和增强,性能相比在PostgreSQL数据库上运行的MADlib性能更优。同时,openGauss基于MADlib框架,实现了其他工业级的、常用的算法,例如XGBoost、Prophet、GBDT以及推荐系统等。与此同时,openGauss还具备原生的AI执行计划与执行算子,该部分特性会在后续版本中开源。因此,本章内容主要介绍openGauss是如何兼容MADlib的。
关键源码解析
1. MADLib的项目结构
MADlib的文件结构及说明如表8-16所示,MADlib的代码可通过其官方网站获取:https://madlib.apache.org/。
表8-16 MADlib的主要文件结构
文件结构
| 说明 | ||
cmake | - | Cmake相关文件 | |
/array_ops | 数组array操作模块 | ||
/kmeans | Kmeans相关模块 | ||
/sketch | 词频统计处理相关模块 | ||
/stemmer | 词干处理相关模块 | ||
/svec | 稀疏矩阵相关模块 | ||
/svec_util | 稀疏矩阵依赖模块 | ||
/utils | 其他公共模块 | ||
src/bin | - | 工具模块,用于安装、卸载、部署等 | |
src/bin/madpack | - | 数据库交互模块 | |
src/dbal | - | 词干处理相关模块 | |
src/libstemmer | - | 工具依赖文件 | |
src/madpack | - | 里面包含公共的模块 | |
src/modules | - | 关联规则算法 | |
/assoc_rules | 包括凸算法的实现 | ||
/convex | 包括条件随机场算法 | ||
/crf | 弹性网络算法 | ||
/elastic_net | 广义线性模型 | ||
/glm | 隐狄利克雷分配 | ||
/lda | 线性代数操作 | ||
/linalg | 线性系统模块 | ||
/linear_systems | 概率模块 | ||
/prob | 决策树和随机森林 | ||
/recursive_partitioning | 回归算法 | ||
/regress | 采样模块 | ||
/sample | 数理统计类模块 | ||
/stats | 时间序列 | ||
/utilities | 包含pg,gaussdb平台相关接口 | ||
src/ports | - | 接口,链接db | |
src/ports/postgres | - | 针对pg系,相关算法 | |
/dbconnector | 关联规则算法 | ||
/modules | 贝叶斯算法 | ||
/modules/bayes | 共轭梯度法 | ||
/modules/conjugate_gradient | 包括多层感知机 | ||
/modules/convex | 条件随机场 | ||
/modules/crf | 弹性网络 | ||
/modules/elastic_net | Prophet时序预测 | ||
/modules/gbdt | Gdbt算法 | ||
/modules/glm | 广义线性模型 | ||
/modules/graph | 图模型 | ||
/modules/kmeans | Kmeans算法 | ||
/modules/knn | Knn算法 | ||
/modules/lda | 隐狄利克雷分配 | ||
/modules/linalg | 线性代数操作 | ||
/modules/linear_systems | 线性系统模块 | ||
/modules/pca | PCA降维 | ||
/modules/prob | 概率模块 | ||
/modules/recursive_partitioning | 决策树和随机森林 | ||
/modules/sample | 回归算法 | ||
/modules/stats | 采样模块 | ||
/modules/summary | 数理统计类模块 | ||
/modules/svm | 描述性统计的汇总函数 | ||
/modules/tsa | Svm算法 | ||
/modules/validation | 时间序列 | ||
/modules/xgboost_gs | 交叉验证 | ||
src/utils | - | Xgboost算法 | |
2. MADlib在openGauss上的执行流程
用户通过调用UDF即可进行模型的训练和预测,相关的结果会保存在表中,存储在数据库上。以训练过程为例,MADlib在openGauss上执行的整体流程如图8-22所示。
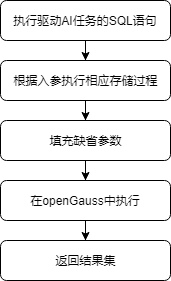
图8-22 MADlib在openGauss上训练模型的流程图
基于MADlib框架的扩展
前文展示了MADlib各个模块的功能和作用,从结构上看,用户可以针对自己的算法进行扩展。前文中提到的XGBoost、GBDT和Prophet三个算法是我们在原来基础上扩展的算法。本小节将以自研的GBDT模块为例,介绍基于MADlib框架的扩展。
GBDT文件结构如表8-17所示。
表8-17 GBDT算法的主要文件结构
文件结构 | 说明 |
gbdt/gbdt.py_in | python代码 |
gbdt/gbdt.sql_in | 存储过程代码 |
gbdt/test/gbdt.sql | 测试代码 |
在sql_in文件中,定义上层SQL-like接口,使用PL/pgSQL或者PL/python实现。
在SQL层中定义UDF函数,下述代码实现了类似重载的功能。
CREATE OR REPLACE FUNCTION MADLIB_SCHEMA.gbdt_train( training_table_name TEXT, output_table_name TEXT, id_col_name TEXT, dependent_variable TEXT, list_of_features TEXT, list_of_features_to_exclude TEXT, weights TEXT ) RETURNS VOID AS $$ SELECT MADLIB_SCHEMA.gbdt_train($1, $2, $3, $4, $5, $6, $7, 30::INTEGER); $$ LANGUAGE sql VOLATILE; CREATE OR REPLACE FUNCTION MADLIB_SCHEMA.gbdt_train( training_table_name TEXT, output_table_name TEXT, id_col_name TEXT, dependent_variable TEXT, list_of_features TEXT, list_of_features_to_exclude TEXT ) RETURNS VOID AS $$ SELECT MADLIB_SCHEMA.gbdt_train($1, $2, $3, $4, $5, $6, NULL::TEXT); $$ LANGUAGE sql VOLATILE; CREATE OR REPLACE FUNCTION MADLIB_SCHEMA.gbdt_train( training_table_name TEXT, output_table_name TEXT, id_col_name TEXT, dependent_variable TEXT, list_of_features TEXT ) RETURNS VOID AS $$ SELECT MADLIB_SCHEMA.gbdt_train($1, $2, $3, $4, $5, NULL::TEXT); $$ LANGUAGE sql VOLATILE;
其中,输入表、输出表、特征等必备信息需要用户指定。其他参数提供缺省的参数,比如权重weights,如果用户没有指定自定义参数,程序会用默认的参数进行运算。
在SQL层定义PL/python接口,代码如下:
CREATE OR REPLACE FUNCTION MADLIB_SCHEMA.gbdt_train( training_table_name TEXT, output_table_name TEXT, id_col_name TEXT, dependent_variable TEXT, list_of_features TEXT, list_of_features_to_exclude TEXT, weights TEXT, num_trees INTEGER, num_random_features INTEGER, max_tree_depth INTEGER, min_split INTEGER, min_bucket INTEGER, num_bins INTEGER, null_handling_params TEXT, is_classification BOOLEAN, predict_dt_prob TEXT, learning_rate DOUBLE PRECISION, verbose BOOLEAN, sample_ratio DOUBLE PRECISION ) RETURNS VOID AS $$ PythonFunction(gbdt, gbdt, gbdt_fit) $$ LANGUAGE plpythonu VOLATILE;
PL/pgSQL或者SQL函数最终会调用到一个PL/python函数。
“PythonFunction(gbdt, gbdt, gbdt_fit)”是固定的用法,这也是一个封装的m4宏,会在编译安装的时候,会进行宏替换。
PythonFunction中,第一个参数是文件夹名,第二个参数是文件名,第三个参数是函数名。PythonFunction宏会被替换为“from gdbt.gdbt import gbdt_fit”语句。所以要保证文件路径和函数正确。
在python层中,实现训练函数,代码如下:
def gbdt_fit(schema_madlib,training_table_name, output_table_name,
id_col_name, dependent_variable, list_of_features,
list_of_features_to_exclude, weights,
num_trees, num_random_features,
max_tree_depth, min_split, min_bucket, num_bins,
null_handling_params, is_classification,
predict_dt_prob = None, learning_rate = None,
verbose=False, **kwargs):
…
plpy.execute("""ALTER TABLE {training_table_name} DROP COLUMN IF EXISTS gradient CASCADE
""".format(training_table_name=training_table_name))
create_summary_table(output_table_name, null_proxy, bins['cat_features'],
bins['con_features'], learning_rate, is_classification, predict_dt_prob,
num_trees, training_table_name)在python层实现预测函数,代码如下:
def gbdt_predict(schema_madlib, test_table_name, model_table_name, output_table_name, id_col_name, **kwargs):
num_tree = plpy.execute("""SELECT COUNT(*) AS count FROM {model_table_name}""".format(**locals()))[0]['count']
if num_tree == 0:
plpy.error("The GBDT-method has no trees")
elements = plpy.execute("""SELECT * FROM {model_table_name}_summary""".format(**locals()))[0]
…在py_in文件中,定义相应的业务代码,用python实现相应处理逻辑。
在安装阶段,sql_in和py_in会被GNU m4解析为正常的python和sql文件。这里需要指出的是,当前MADlib框架只支持python2版本,因此,上述代码实现也是基于python2完成的。
MADlib在openGauss上的使用示例
这里以通过支持向量机算法进行房价分类为例,演示具体的使用方法。
(1) 数据集准备,代码如下:
DROP TABLE IF EXISTS houses; CREATE TABLE houses (id INT, tax INT, bedroom INT, bath FLOAT, price INT, size INT, lot INT); INSERT INTO houses VALUES (1 , 590 , 2 , 1 , 50000 , 770 , 22100), (2 , 1050 , 3 , 2 , 85000 , 1410 , 12000), (3 , 20 , 3 , 1 , 22500 , 1060 , 3500), … (12 , 1620 , 3 , 2 , 118600 , 1250 , 20000), (13 , 3100 , 3 , 2 , 140000 , 1760 , 38000), (14 , 2070 , 2 , 3 , 148000 , 1550 , 14000), (15 , 650 , 3 , 1.5 , 65000 , 1450 , 12000);
(2) 模型训练
① 训练前配置相应schema和兼容性参数,代码如下:
SET search_path="$user",public,madlib; SET behavior_compat_options = 'bind_procedure_searchpath';
② 使用默认的参数进行训练,分类的条件为‘price < 100000’,SQL语句如下:
DROP TABLE IF EXISTS houses_svm, houses_svm_summary;
SELECT madlib.svm_classification('public.houses','public.houses_svm','price < 100000','ARRAY[1, tax, bath, size]');(3) 查看模型,代码如下:
\x on SELECT * FROM houses_svm; \x off
结果如下:
-[ RECORD 1 ]------+-----------------------------------------------------------------
coef | {.113989576847,-.00226133300602,-.0676303607996,.00179440841072}
loss | .614496714256667
norm_of_gradient | 108.171180769224
num_iterations | 100
num_rows_processed | 15
num_rows_skipped | 0
dep_var_mapping | {f,t}(4) 进行预测,代码如下:
DROP TABLE IF EXISTS houses_pred;
SELECT madlib.svm_predict('public.houses_svm','public.houses','id','public.houses_pred');(5) 查看预测结果,代码如下:
SELECT *, price < 100000 AS actual FROM houses JOIN houses_pred USING (id) ORDER BY id;
结果如下:
id | tax | bedroom | bath | price | size | lot | prediction | decision_function | actual ----+------+---------+------+--------+------+-------+------------+-------------------+-------- 1 | 590 | 2 | 1 | 50000 | 770 | 22100 | t | .09386721875 | t 2 | 1050 | 3 | 2 | 85000 | 1410 | 12000 | t | .134445058042 | t … 14 | 2070 | 2 | 3 | 148000 | 1550 | 14000 | f | -1.9885277913972 | f 15 | 650 | 3 | 1.5 | 65000 | 1450 | 12000 | t | 1.1445697772786 | t (15 rows
查看误分率,代码如下:
SELECT COUNT(*) FROM houses_pred JOIN houses USING (id) WHERE houses_pred.prediction != (houses.price < 100000);
结果如下:
count ------- 3 (1 row)
(6) 使用svm其他核进行训练,代码如下:
DROP TABLE IF EXISTS houses_svm_gaussian, houses_svm_gaussian_summary, houses_svm_gaussian_random; SELECT madlib.svm_classification( 'public.houses','public.houses_svm_gaussian','price < 100000','ARRAY[1, tax, bath, size]','gaussian','n_components=10', '', 'init_stepsize=1, max_iter=200' );
进行预测,并查看训练结果。
DROP TABLE IF EXISTS houses_pred_gaussian;
SELECT madlib.svm_predict('public.houses_svm_gaussian','public.houses','id', 'public.houses_pred_gaussian');
SELECT COUNT(*) FROM houses_pred_gaussian JOIN houses USING (id) WHERE houses_pred_gaussian.prediction != (houses.price < 100000);结果如下:
count -------+ 0 (1 row)
(7) 其他参数
除了指定不同的核方法外,还可以指定迭代次数、初始参数,比如init_stepsize,max_iter,class_weight等。
演进路线
openGauss当前通过兼容开源的Apache MADlib机器学习库来具备机器学习能力。通过对原有MADlib框架的适配,openGauss实现了多种自定义的工程化算法扩展。
除兼容业界标杆PostgreSQL系的Apache MADlib来获得它的业务生态外,openGauss也在自研原生的DB4AI引擎,并支持端到端的全流程AI能力,这包括模型管理、超参数优化、原生的SQL-like语法、数据库原生的AI算子与执行计划等,性能相比MADlib具有5倍以上的提升。该功能将在后续逐步开源。
8.8 小结
本章中,介绍了openGauss团队在AI与数据库结合中的探索,并重点介绍了AI4DB中的参数自调优、索引推荐、异常检测、查询时间预测、慢SQL发现等特性,以及openGauss的DB4AI功能。无论从哪个方面讲,AI与数据库的结合远不止于此,此处介绍的这些功能也仅是一个开端,在openGauss的AI功能上还有很多事情要做、还有很多路要走。包括AI与优化器的进一步结合;打造全流程的AI自治能力,实现全场景的故障发现与自动修复;利用AI改造数据库内的算法与逻辑等都是演进的方向。
虽然AI与数据库结合已经取得了长远的进步,但是还面临着如下的挑战。
(1) 算力问题:额外的AI计算产生的算力代价如何解决?会不会导致性能下降。
(2) 算法问题:使用AI算法与数据库结合是否会带来显著的收益?算法额外开销是否很大?算法能否泛化,适用到普适场景中?选择什么样的算法更能解决实际问题?
(3) 数据问题:如何安全的提取和存储AI模型训练所需要的数据,如何面对数据冷热分类和加载启动问题?
上述问题在很大程度上是一个权衡问题,既要充分利用AI创造的灵感,又要充分继承和发扬数据库现有的理论与实践,这也是openGauss团队不断探索的方向。
感谢大家学习第8章 AI技术中“8.7 DeepSQL、8.8 小结”的精彩内容,下一篇我们开启“第9章 安全管理源码解析”的相关内容的介绍。
敬请期待。
|








- 上一条: 乘「风」破「浪」的国产图数据库 2021-09-29
- 下一条: ❤️如何使用pg_chameleon迁移MySQL数据库至openGauss❤️ 2021-10-08
- 前沿科技探究DeepSQL:库内AI算法 2022-03-25
- ⭐openGauss数据库源码解析系列文章—— 安全管理源码解析⭐ 2021-10-12
- openGauss数据库源码解析系列文章——存储引擎源码解析(三) 2021-12-22
- openGauss数据库源码解析系列文章—— AI技术(一) 2021-09-02
- openGauss数据库源码解析系列文章—— AI技术之“智能索引推荐” 2021-09-13


