【ELT.ZIP】OpenHarmony啃论文成长计划——多维探秘通用无损压缩

-
本文出自
ELT.ZIP团队,ELT<=>Elite(精英),.ZIP为压缩格式,ELT.ZIP即压缩精英。 -
成员:
- 上海工程技术大学大二在校生
- 合肥师范学院大二在校生
- 清华大学大二在校生
- 成都信息工程大学大一在校生
-
我们是来自4个地方的同学,我们在
OpenHarmony成长计划啃论文俱乐部里,通过啃论文方式学习操作系统技术...
@[toc]
引言
压缩的标准方法是定义产生不同类型数据源的类别,假设数据是由某一类源产生的,并应用为其特殊设计的压缩算法,若可以在近似为输出的数据上良好运行,便可被称为通用压缩算法。
熵编码器
- 熵编码器(entropy coder)是一种
根据字符出现的概率为字母表中的每个字符分配编码的方法。更有可能出现的字符被分配的编码比不太可能出现的更短,这种方式可以使压缩序列的预期长度最小。目前流行的熵编码器是Huffman编码器和算术编码器,这两种方法都做到了相对最优,所以不能分配比预期长度更小的压缩序列编码。其中,Huffman在分配整数长度编码的方法类中是最优的,算术编码则不受这种限制,因此,它通常可产生更短的期望编码长度。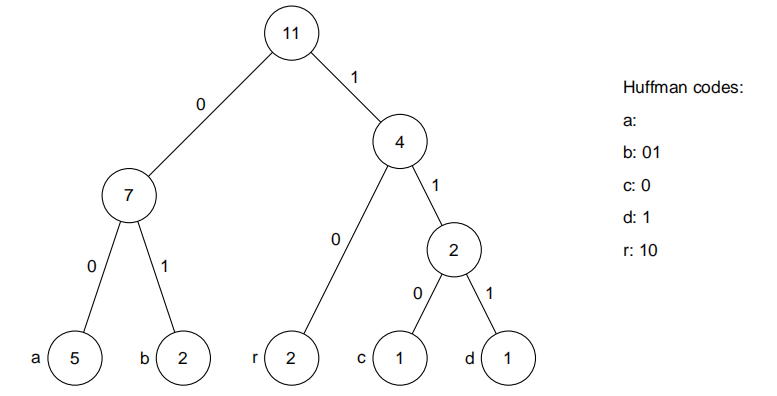 图1:序列abracadabra的Huffman树
图1:序列abracadabra的Huffman树
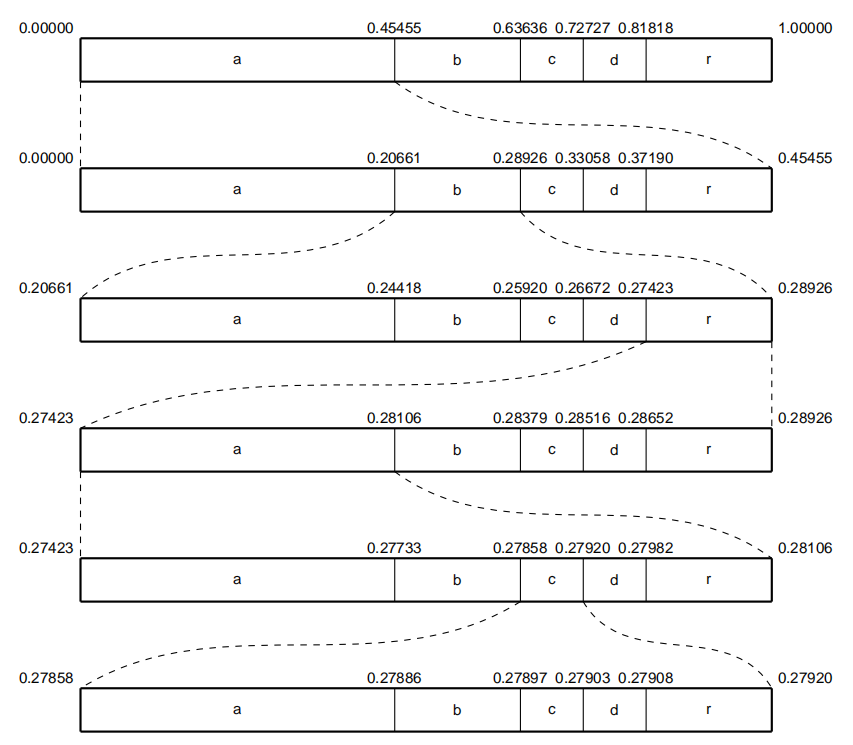 图2:算术编码过程
图2:算术编码过程
BWT算法
-
块排序压缩算法(block-sorting compression algorithm),通常被称为Burrows-Wheeler变换算法*(Burrows–Wheeler compression algorithm)***,是一个被应用在数据压缩技术(如bzip2)中的算法,于1994年被Michael Burrows和David Wheeler在位于加利福尼亚州帕洛阿尔托的DEC系统研究中心发明。
-
原理思想:
- 构造矩阵,其行存储压缩序列的所有单字符循环移位
- 按字典顺序对行进行排序
- 使用矩阵最后一列进行后续处理
BWT算法与以往的压缩算法有所不同,比较著名的压缩算法如Lempel-Ziv(LZ77,LZ78)、PPM、DMC针对的是通用的数据流模型,比如无记忆源(Memoryless sources),马尔可夫源(Markov sources),有限阶FSM源(finite-order FSM sources),一次读取一个或多个字节,而BWT可以处理成块的数据。BWT算法的核心思想是对一个字符串中的字符进行位置变换,使相同的字符相邻的概率增大。 上述过程被称为Burrows-Wheeler变换*(BWT)*。随后,变换的输出由一个前移变换处理,最后阶段,由熵编码器压缩,可以是Huffman编码或算术编码。结果是,获得了一个序列,其中出现在相似上下文中的所有字符被分组。 字符串经过BWT算法转换后并没有被压缩,而是因其极有规律性的字母内聚的特点使其他文本压缩算法大大简化,提高压缩速率和压缩比。
基于BWT算法的重要特点是运行速度快、压缩比合理,比LZ算法好得多,只比现有最佳部分匹配*(PPM, prediction by partial matching)*算法稍差;是Ziv-Lempel快速压缩算法和PPM算法的有趣替代品,前者压缩比较差,后者压缩比较好,但工作速度较慢
- 对于一个长度为n的序列x,可以将序列轮转形成一个的矩阵:
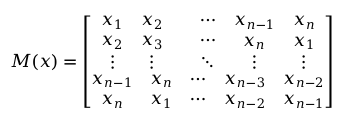 然后将矩阵
然后将矩阵以行为单位按照字母表顺序重新排列成矩阵,得到,并用R(x)记录在新矩阵中原序列x所在的行数。取矩阵的最后一列记为即得到BWT的最终结果。

下面我们用字符序列x=“abracadabra”,且为了获得更好的关系类型的序列,我们在x前加上哨兵字符“$”。最终得到x^bwt^ = $drcraaaabba,R(x) = 1。可以看出通过BWT算法,一些字符连续出现的概率增大。
BWT算法的逆过程则比较复杂,但在编程实现上也比较简单。其主要思想是以x^bwt^为基础,对字符序列进行转移、排序和组合构建BWT转换后得到的矩阵M~(x)。还是以$drcraaaabba为例:
| 输入 | 转移 | 排序 | 组合 |
|---|---|---|---|
| -----------$ | $----------- | a----------- | a----------$ |
| -----------d | d----------- | a----------- | a----------d |
| -----------r | r----------- | a----------- | a----------r |
| -----------c | c----------- | a----------- | a----------c |
| -----------r | r----------- | a----------- | a----------r |
| -----------a | a----------- | b----------- | b----------a |
| -----------a | a----------- | b----------- | b----------a |
| -----------a | a----------- | c----------- | c----------a |
| -----------a | a----------- | d----------- | d----------a |
| -----------b | b----------- | r----------- | r----------b |
| -----------b | b----------- | r----------- | r----------b |
| -----------a | a----------- | $----------- | $----------a |
| 输入 | 转移 | 排序 | 组合 |
|---|---|---|---|
| a----------$ | $a---------- | ab---------- | ab---------$ |
| a----------d | da---------- | ab---------- | ab---------d |
| a----------r | ra---------- | ac---------- | ac---------r |
| a----------c | ca---------- | ad---------- | ad---------c |
| a----------r | ra---------- | a$---------- | a$---------r |
| b----------a | ab---------- | br---------- | br---------a |
| b----------a | ab---------- | br---------- | br---------a |
| c----------a | ac---------- | ca---------- | ca---------a |
| d----------a | ad---------- | da---------- | da---------a |
| r----------b | br---------- | ra---------- | ra---------b |
| r----------b | br---------- | ra---------- | ra---------b |
| $----------a | a$---------- | $a---------- | $a---------a |
| 输入 | 转移 | 排序 | 组合 |
|---|---|---|---|
| ab---------$ | $ab--------- | abr--------- | abr--------$ |
| ab---------d | dab--------- | abr--------- | abr--------d |
| ac---------r | rac--------- | aca--------- | aca--------r |
| ad---------c | cad--------- | ada--------- | ada--------c |
| a$---------r | ra$--------- | a$a--------- | a$a--------r |
| br---------a | abr--------- | bra--------- | bra--------a |
| br---------a | abr--------- | bra--------- | bra--------a |
| ca---------a | aca--------- | cad--------- | cad--------a |
| da---------a | ada--------- | dab--------- | dab--------a |
| ra---------b | bra--------- | rac--------- | rac--------b |
| ra---------b | bra--------- | ra$--------- | ra$--------b |
| $a---------a | a$a--------- | $ab--------- | $ab--------a |
| 输入 | 转移 | 排序 | 组合 |
|---|---|---|---|
| abr--------$ | $abr-------- | abra-------- | abra-------$ |
| abr--------d | dabr-------- | abra-------- | abra-------d |
| aca--------r | raca-------- | acad-------- | acad-------r |
| ada--------c | cada-------- | adab-------- | adab-------c |
| a$a--------r | ra$a-------- | a$ab-------- | a$ab-------r |
| bra--------a | abra-------- | brac-------- | brac-------a |
| bra--------a | abra-------- | bra$-------- | bra$-------a |
| cad--------a | acad-------- | cada-------- | cada-------a |
| dab--------a | adab-------- | dabr-------- | dabr-------a |
| rac--------b | brac-------- | raca-------- | raca-------b |
| ra$--------b | bra$-------- | ra$a-------- | ra$a-------b |
| $ab--------a | a$ab-------- | $abr-------- | $abr-------a |
| 输入 | 转移 | 排序 | 组合 |
|---|---|---|---|
| abra-------$ | $abra------- | abrac------- | abrac------$ |
| abra-------d | dabra------- | abra$------- | abra$------d |
| acad-------r | racad------- | acada------- | acada------r |
| adab-------c | cadab------- | adabr------- | adabr------c |
| a$ab-------r | ra$ab------- | a$abr------- | a$abr------r |
| brac-------a | abrac------- | braca------- | braca------a |
| bra$-------a | abra$------- | bra$a------- | bra$a------a |
| cada-------a | acada------- | cadab------- | cadab------a |
| dabr-------a | adabr------- | dabra------- | dabra------a |
| raca-------b | braca------- | racad------- | racad------b |
| ra$a-------b | bra$a------- | ra$ab------- | ra$ab------b |
| $abr-------a | a$abr------- | $abra------- | $abra------a |
按照这样的规律一直操作下去,最终可以得到:
| 输入 | 转移 | 排序 | 组合 |
|---|---|---|---|
| abracadabr-$ | $abracadabr- | abracadabra- | abracadabra$ |
| abra$abrac-d | dabra$abrac- | abra$abraca- | abra$abracad |
| acadabra$a-r | racadabra$a- | acadabra$ab- | acadabra$abr |
| adabra$abr-c | cadabra$abr- | adabra$abra- | adabra$abrac |
| a$abracada-r | ra$abracada- | a$abracadab- | a$abracadabr |
| bracadabra-a | abracadabra- | bracadabra$- | bracadabra$a |
| bra$abraca-a | abra$abraca- | bra$abracad- | bra$abracada |
| cadabra$ab-a | acadabra$ab- | cadabra$abr- | cadabra$abra |
| dabra$abra-a | adabra$abra- | dabra$abrac- | dabra$abraca |
| racadabra$-b | bracadabra$- | racadabra$a- | racadabra$ab |
| ra$abracad-b | bra$abracad- | ra$abracada- | ra$abracadab |
| $abracadab-a | a$abracadab- | $abracadabr- | $abracadabra |
最后一次操作的得到的组合即为x对应的矩阵M~(x),矩阵的第一行去掉最后的“$“就得到原字符序列x=”abracadabra”。
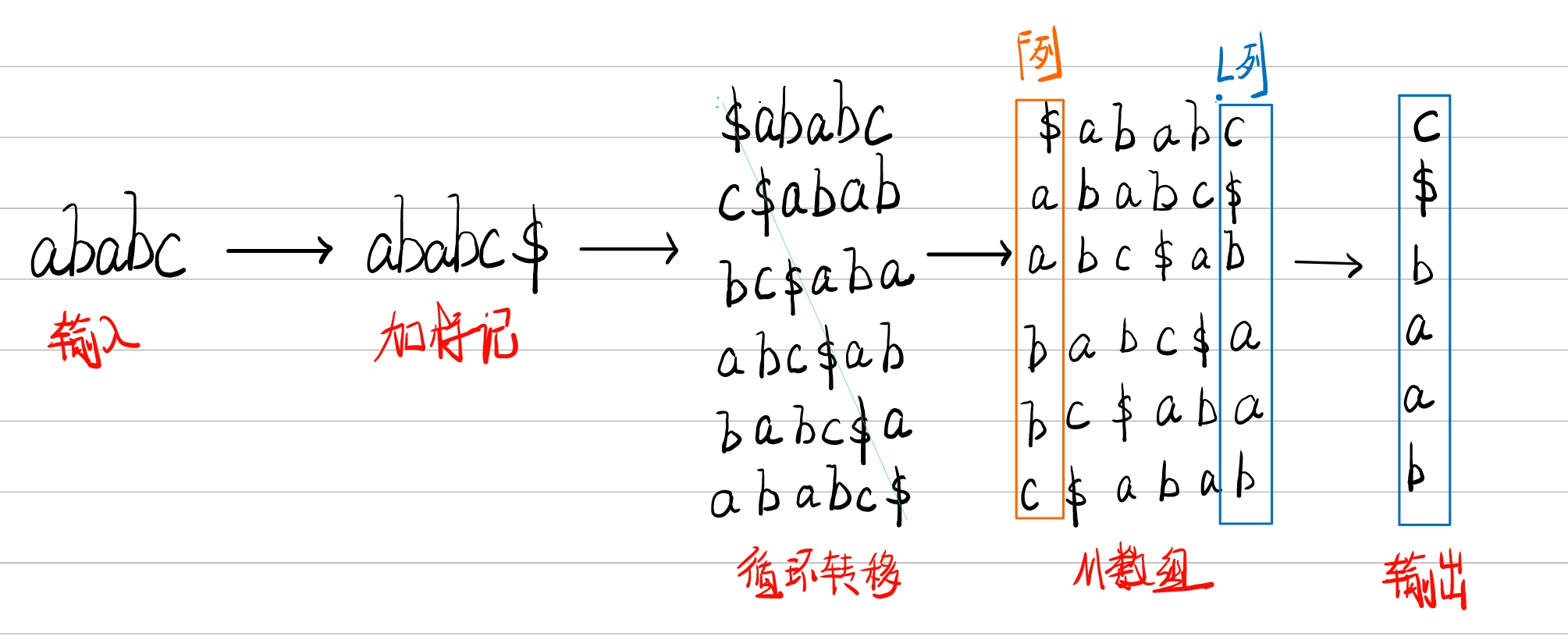 BWT就是一个加标记,循环转移,算出数组,输出结果的过程。
BWT就是一个加标记,循环转移,算出数组,输出结果的过程。
① 这里我们输入字符串ababc,并给其加上标记得到ababc$这个标记$要比所有字符都要小。 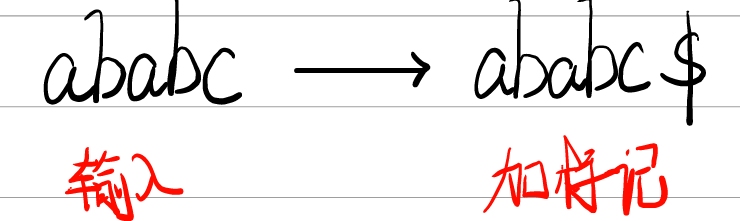
② 之后我们对处理后的字符串进行循环转移,此时你可以把ababc$当作一个圆,然后让其旋转,使得F列(第一列)的字符按照ASCII码从小到大排列。 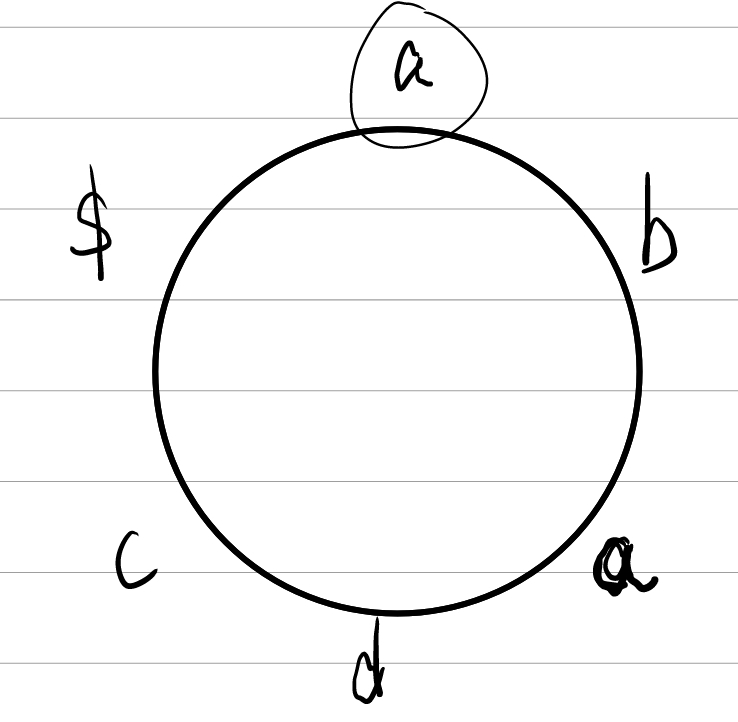
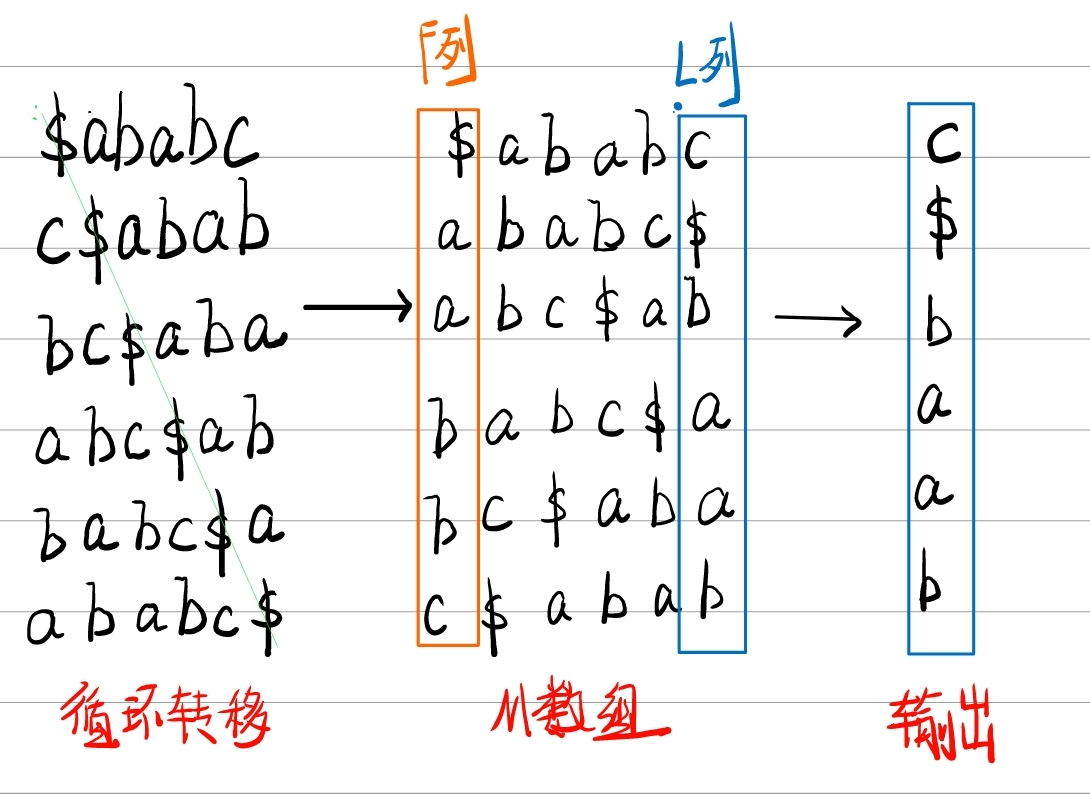
③ 得到的M数组最后一列便是输出的L列
BWT编码及解码的C++实现:
#include <iostream>
#include <string>
#include <algorithm>
#include <string.h>
using namespace std;
///编码,生成last数组
int getLastArray(char *lastArray,const string &str){ ///子串排序
int len=str.size();
string array[len];
for(int i=0;i<len;i++){
array[i] = str.substr(i);
}
sort(array,array+len);
for(int i=0;i<len;i++){
lastArray[i] = str.at((2*len-array[i].size()-1)%len);
}
return 0;
}
int getCountPreSum(int *preSum,const string &str){
memset(preSum,0,27*sizeof(int));
for(int i=0;i<str.size();i++){
if(str.at(i) == '#')
preSum[0]++;
else
preSum[str.at(i)-'a'+1]++;
}
for(int i=1;i<27;i++)
preSum[i] += preSum[i-1];
return 0;
}
///解码,使用last数组,恢复原来的文本块
int regainTextFromLastArray(char *lastArray,char *reGainStr,int *preSum){
int len=strlen(lastArray);
int pos=0;
char c;
for(int i=len-1;i>=0;){
reGainStr[i] = lastArray[pos];
c = lastArray[pos];
pos = preSum[c-'a']+count(lastArray,lastArray+pos,c);
i--;
}
return 0;
}
int main (){
string str("sdfsfdfdsdfgdfgfgfggfgdgfgd#");
int preSum[27];
int len=str.size();
char *lastArray = new char[len+1];
char *reGainStr = new char[len+1];
lastArray[len]='';
reGainStr[len]='';
getCountPreSum(preSum,str);
getLastArray(lastArray,str);
regainTextFromLastArray(lastArray,reGainStr,preSum);
cout<<" str: "<<str<<endl;
cout<<"lastArray : "<<lastArray<<endl;
cout<<"reGainStr : "<<reGainStr<<endl;
delete lastArray;
delete reGainStr;
return 0;
}
研究者提出一种基于 Burrows-Wheeler 变换的改进算法,该算法在获得最佳压缩比的同时,其运算速度可以与该类算法中最快的算法媲美。
基于BWT的改进算法
一般结构
算法的第一阶段是Burrows-Wheeler变换。BWT输出序列在第二阶段经历一个加权频率计数变换,第三阶段是零运行长度编码,它减少了0次运行的长度。在最后阶段,序列x^(rle-0)^由二进制算术编码器编码。算术编码是一种行之有效的熵编码方法,其中最重要的部分是概率估计方法。BWT只是对序列x的转换,并不起到压缩的作用,经过BWT算法编码后的序列还需要通过其他压缩算法才可以完成整个压缩任务:  图3:基于BWT的改进算法
图3:基于BWT的改进算法
- MTF*(Move-To-Front)*是一种数据编码方式,作为一个额外的步骤,用于
提高数据压缩技术效果。MTF主要使用的是数据“空间局部性”,也就是最近出现过的字符很可能在接下来的文本附近再次出现。MTF的主要思想是:
- 首先维护一个序列字符集大小的栈表,其中每个不同的字符在其中占一个位置,位置从0开始编号
- 扫描需要重新编码的序列数据,对于每个扫描到的字符,使用该字符在
栈表中的索引替换,并将该字符提到栈表的栈顶的位置(索引为0的位置) - 重复上一步骤,直到序列扫描结束
以经过BWT算法得到的x^bwt^ = drcraaaabba为例:
| 迭代 | 序列 | 栈表 |
|---|---|---|
| d | 3 | abcdr |
| r | 4 | dabcr |
| c | 4 | rdabc |
| r | 1 | crdab |
| a | 3 | rcdab |
| a | 0 | arcdb |
| a | 0 | arcdb |
| a | 0 | arcdb |
| b | 4 | barcd |
| b | 0 | barcd |
| a | 1 | abrcd |
最终的得到的x^mtf^为34413000401. 相比于BWT算法,MTF算法的解码过程更为简单,其实就是上述过程的逆过程:
| 序列 | 栈表 | 字符 |
|---|---|---|
| 34413000401 | abrcd | a |
| 3441300040 | barcd | b |
| 34413000 | arcdb | a |
| 3441300 | arcdb | a |
| 344130 | arcdb | a |
| 34413 | arcdb | a |
| 3441 | rcdab | r |
| 344 | crdab | c |
| 34 | rdabc | r |
| 3 | dabcr | d |
根据上表所示过程即可解码x^mtf^.
- RLE-0(Zero run length encoding)叫做
零游程编码,不同于一般的RLE算法,它只对序列中的0进行替换。在这里使用RLE-0处理序列是由于经过BWT和MTF两个过程,一般在序列中会存在大量的连续的零,因此用RLE-0对x^mtf^进行编码会起到一定的压缩效果。
RLE-0的原理是:
- 统计序列中由0组成的子序列含0的个数
- 用0~a~和0~b~符号表示数字m
第2步的具体做法是,先将(m+1)转换成二进制数,然后用0~a~代替0,0~b~代替1,最后舍弃最高位:
| 0的个数m | m+1的二进制表示 | 替换后 | RLE-0 编码 |
|---|---|---|---|
| 1 | 10 | 0~b~0~a~ | 0~a~ |
| 2 | 11 | 0~b~0~b~ | 0~b~ |
| 3 | 100 | 0~b~0~a~0~a~ | 0~a~0~a~ |
| 4 | 101 | 0~b~0~a~0~b~ | 0~a~0~b~ |
| 5 | 110 | 0~b~0~b~0~a~ | 0~b~0~a~ |
| 6 | 111 | 0~b~0~b~0~b~ | 0~b~0~b~ |
| 7 | 1000 | 0~b~0~a~0~a~0~a~ | 0~a~0~a~0~a~ |
| ... | ... | ... | ... |
所以,x^mtf^ = 34413000401 经过RLE-0算法得到的序列为x^rle-0^ = 344130~a~0~a~40~a~1,由于这里的序列x过短,所以零游程编码的压缩效果并未很好的体现出来;RLE-0的解码过程就是根据个数和编码的对应关系将序列中的0~a~,0~b~替换成对应个数的0。
实际效率
- 选择测试数据 为了比较压缩算法,需要一组文件。通常情况下,有两种选择测试文件的方式:
- 使用一个众所周知的数据集
- 为测试准备新的数据集
- 多标准优化 通常情况下,现实世界中有许多标准,我们
不能优化所有的标准,所以不得不选择一种折衷方案。如果没有详细了解将压缩应用于的具体情况,我们就无法选择最佳的压缩方法。因此,这种情况下便需要讨论多标准优化*(multi criteria optimisation)。 1896-1897年,Pareto首次对该领域进行了研究,讨论了满足许多排他性标准的问题。1906年,Pareto在他的著名著作《Manuale di economia politica, conuna introduzione alla scienca Sociale》中提出了非支配解决方案(non-dominated solutions)*的概念。其在经济学术语中提出这样一种解决方案:作为一种解决方案,没有任何一个人可以更满意而别人一点不满意。目前,称此解决方案为Pareto最优解,即,不是非劣势解的解为劣势解。
有一些标准Q~1~,Q~2~...,Q~m~取决于一些变量: (1) Q~i~ = Q~i~(q~1~,q~2~,...,q~r~), 当 i = 1, 2, ... , m 一组变量: (2) q = <q~1~,q~2~,...,q~r~> 被称为优化中的一个点。点q被称为Pareto-optimal,如果没有其他点p例如 (3) ∀1≤i≤m Q~i~(p) ≥ Q~i~(q) 多标准优化的目标是找到所有Pareto最优点的集合。Pareto最优集(方程3)的公式适用于所有标准Q~i~最大化的情况。一般情况下,所有或某些标准可以被最小化。 压缩质量至少有三个标准:压缩比、压缩速率、解压速率。通过每个输入字符(bpc)的平均输出位数度量压缩比,因此压缩比越小,效果越好。
算法比较
检验算法
- A02 —— 基于BWT的算法,反演频率变换作为第二阶段,结果来自Arnavut的工作
- acb —— Buyanovsky的关联编码器,压缩结果来自于acb 2.00c项目的实验
- B97 —— Bunton提出的PPM算法的最佳版本
- boa —— 由Sutton编写的boa 0.58b压缩程序,是PPM算法的实现
- BS99 —— Balkenhol和Shtarkov提出的基于BWT的算法
- BW94 —— 初始Burrows-Wheeler算法
- Bzip —— Seward编写的bzip 0.21压缩程序,实现了与Fenwick方法的相同压缩比
- CTW —— Willems等提出的上下文树加权方法
- DM —— 基于BWT的改进算法,第二阶段是移动到前端的变换
- DW —— 基于BWT的改进算法,第二阶段是加权频率计数变换
- F96 —— Fenwick提出的基于BWT的算法,在Silesia corpus实验的bzip 0.21程序中取得了相同压缩比
- gzip —— 标准gzip程序,是著名的LZ77算法的实现
- LDMC —— 目前最好的动态Markov编码算法,最初由Cormack和Horspool 引入,是由Bunton改进的LazyDMC版本
- lgha —— 速度优化的ha压缩程序,由Lyapko提供实现
- LZMA —— Pavlov提出的Ziv-Lempel算法,结果来自7-zip程序的实验
- LZW —— 标准UNIX压缩程序,是LZW算法的一个实现
- MH —— Shkarin提出的cPPMII算法,结果来自PPMonstr var. H程序的实验
- MI4 —— Shkarin的cPPMII算法,结果来自4阶PPMonstr var. I程序的实验
- MI64 —— Shkarin的cPPMII算法,结果来自64阶PPMonstr var. I程序的实验
- PPMdH —— Shkarin提出的PPMII算法,结果来自PPMd var. H程序的实验
- PPMN —— Smirnov 的 PPMN 算法,结果来自*ppmnb1+*程序的实验
- rar —— rar 2.90压缩程序
- szip —— Schindler提出的基于BWT的算法,结果来自szip程序的实验
- T98 —— Teahan提出的PPMD+算法,结果来自*ppmd+*程序的实验
- ufa —— Pavlov提出的二进制PPM算法,结果来自* ufa 0.04 Beta 1*程序的实验
- VW98 —— Volf和Willems提出的切换算法
- WM01 —— 基于BWT的最佳算法,无第二阶段,结果来自Wirth和Moffat的工作
- ybs —— 基于BWT的压缩程序,距离编码器变换作为第二阶段,是Yoockin的实现
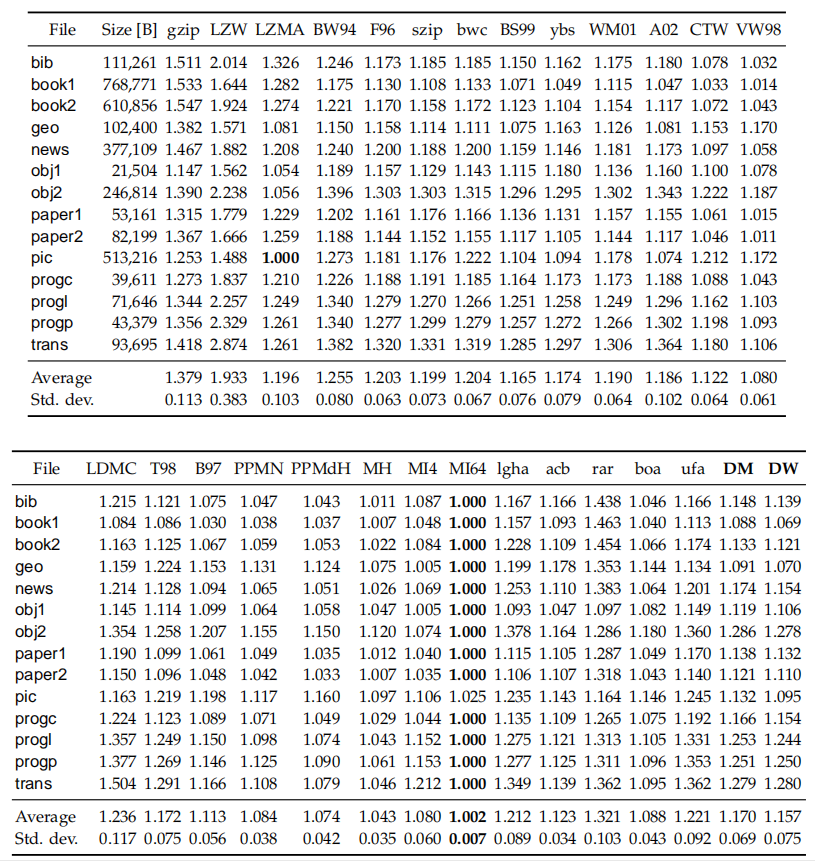 表1:以bpc为单位的压缩比
表1:以bpc为单位的压缩比
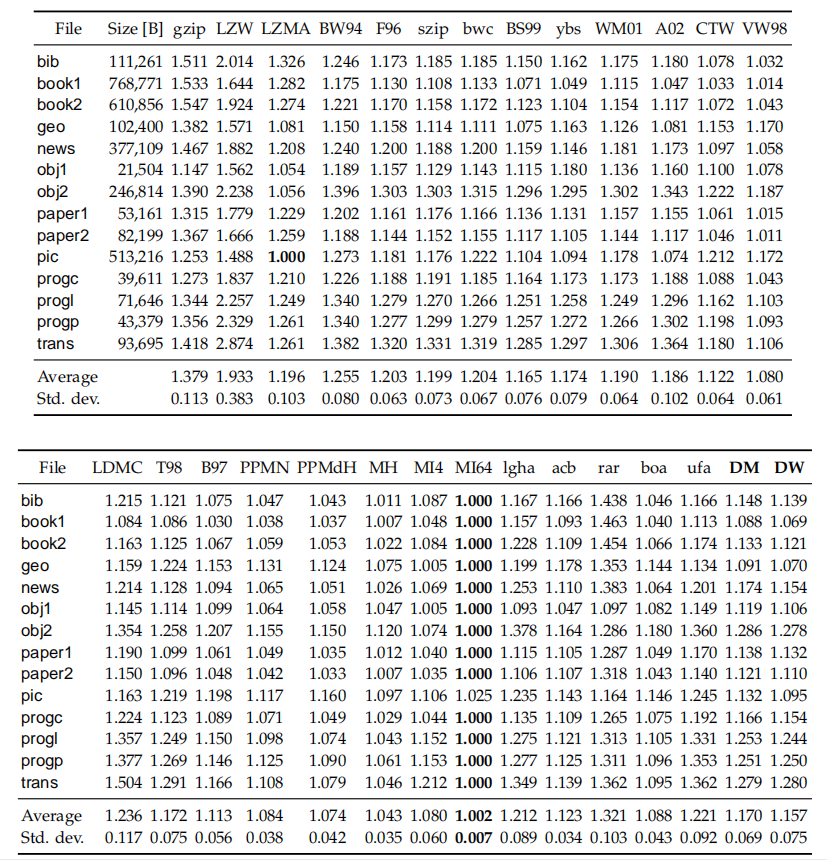 表2:以bpc为单位的标准化压缩比
表2:以bpc为单位的标准化压缩比
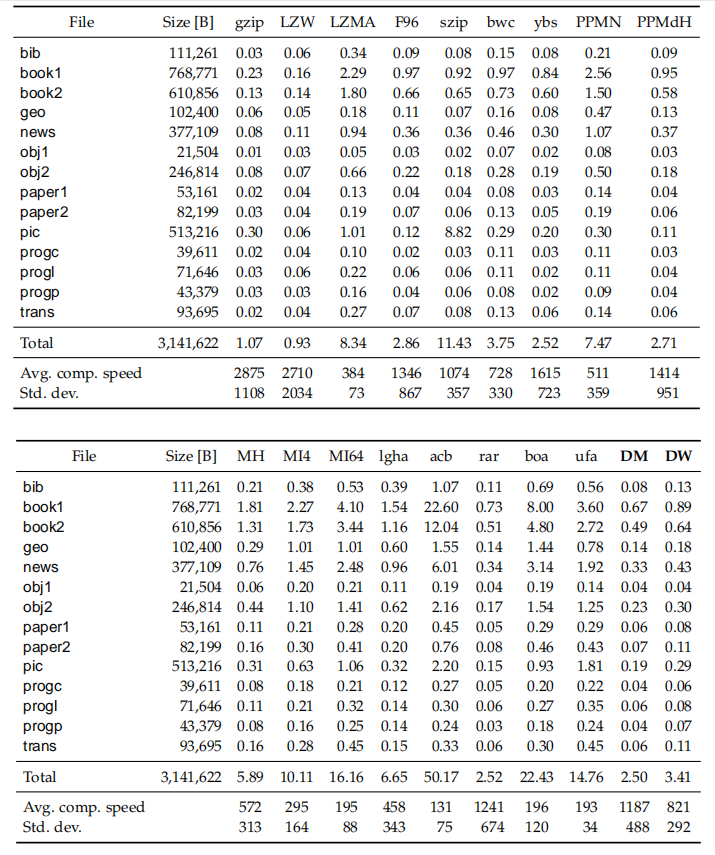 表3:以秒为单位的压缩时间
表3:以秒为单位的压缩时间
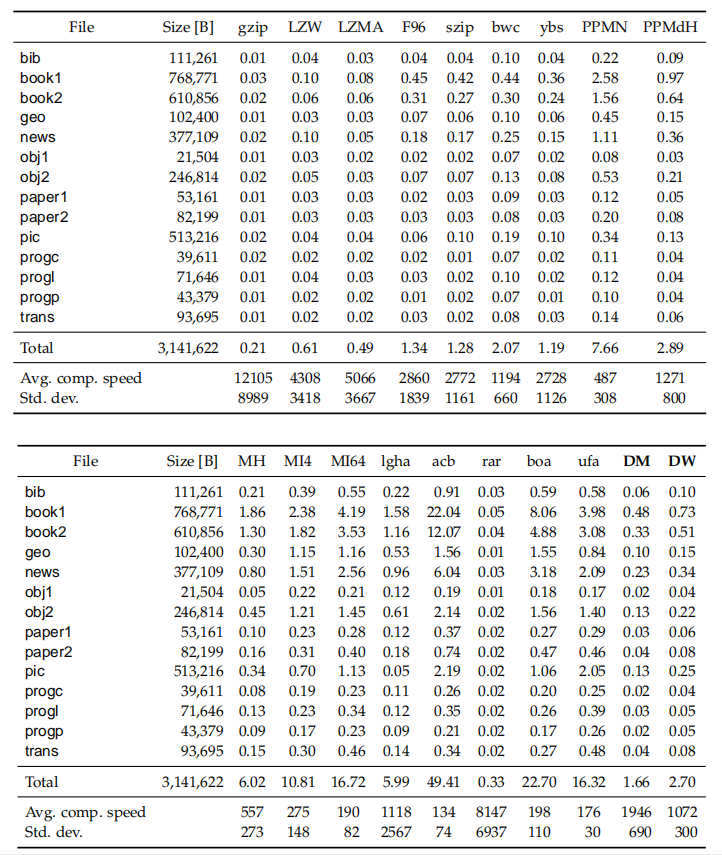 表4:以秒为单位的解压时间
表4:以秒为单位的解压时间
以上其中几幅表对解压速度和压缩比进行了比较。我们可以看到,PPM算法的解压速度几乎与其压缩速度相同;LZ算法解压比压缩快得多;基于BWT算法的解压与压缩速度之间有着明显的差异,但低于LZ算法;PPMdH算法仅支配了两种基于BWT的算法,但其平均解压缩速度的标准差远远高于这两种算法;DM算法是Pareto最优的,而其在基于BWT的算法中取得了最佳压缩比;测试中的LZMA算法实现了LZ系列中的最佳压缩比,但其压缩速度慢,比最慢的基于BWT的算法慢两倍以上,解压速度方面优于所有基于BWT的算法及LZW算法。
实验结论
| 算法 | 优点 | 缺点 |
|---|---|---|
| cPPMII | 压缩比显著优 | 运行速度慢、内存消耗高 |
| LZMA | 压缩比明显优、解压速度快 | 压缩速度慢 |
| PPM | 压缩比明显优 | 压缩、解压速度慢 |
| 基于BWT系列 | 大文件压缩速度较快 | 小文件压缩比较差 |
- 从多准则优化的角度对实验结果进行分析,可将这些方法粗略地分为三组:
- 包括PPM、CTW、DMC算法,达到了最佳压缩比,但速度较慢
- 包括LZ算法,速度较快,但压缩比较差
- 包括基于BWT系列算法,比PPM运行速度快,比LZ有更好的压缩比
在基于BWT系列中,最佳压缩比的是本文改进算法——DW,其运行速度与其他BWT系列算法相当。对不同大小文件的测试表明,DW的压缩与解压速度比其他基于BWT的大尺寸块算法相对更稳定。
Lempel-Ziv Parsing
概述
Lempel-Ziv 算法由 Abraham Lempel 和 Jacob Ziv 在《A Universal Algorithm for Sequential Data Compression》最早引入。和 Burrows-Wheeler 算法一样,Lempel-Ziv的名称也是由其发明者命名。
Lempel-Ziv 算法有两个版本,根据发明日期分别为 1977年的LZ77 和 1978年的LZ78,其后又衍生出了不少像deflate,lzx,lzma这样优秀的变体算法。 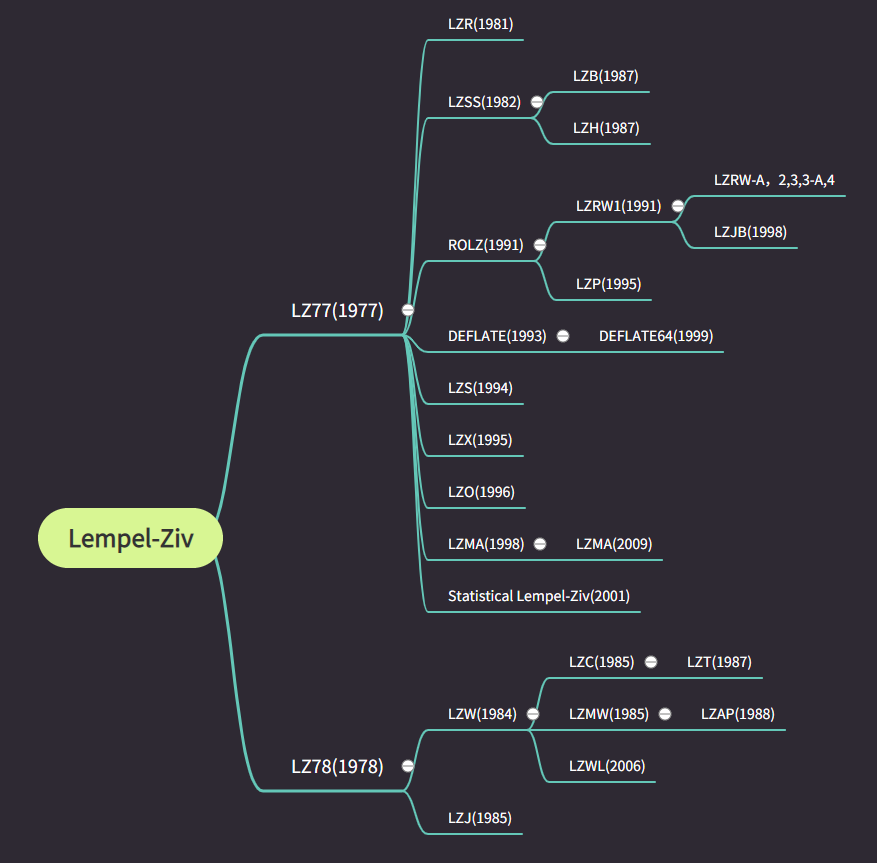
这里有一个比较有意思的事情,仔细看,会发现先发明出的LZ77算法的变体比LZ78多,是因为LZ77被人们使用的时间长吗?并不是,这是因为LZ78算法在1984年被Sperry申请了其变体lzw算法的专利,并开始起诉相关软件供应商等在没有许可证的情况下使用率GIF格式,之后LZ78算法的普及逐渐衰减。尽管LZW的专利问题已经平息,并出现了很多 LZW变体,但目前只有在 GIF压缩中被普遍使用,占据主导地位的仍是LZ77算法。
尽管 Lempel-Ziv算法有很多变体,但它们都有一个共同的思想:<u>如果一些文本不是均匀随机的,也就是说,所有字母出现的可能性不一样,那么已经出现过的子串会比没有看过的子串更可能再次出现。</u>举个例子,在我们日常生活中,我们都有一些日用语,比如“你好”,“你好吗”;那么,“你好”,“你好吗”,“你好吗”中包含字串“你好”,我们便可以把“你好”简化为更短的二进制码,来替换“你好吗”中的“你好”,从而简化编码。
LZ78
LZ78 算法通过构建出现在⽂本中的⼦字符串字典来⼯作。
算法有两种情况:
- 若当前字符未出现在字典中,则将该字符编码进字典
- 若当前字符出现在字典中,则从当前字符开始与字符做最长匹配,并将匹配到的最长子串后的第一个字符做特殊处理,并编码进字典。
举例:假设我们有字符串 AABABBBABA ,我们使用 LZ78算法对其进行压缩 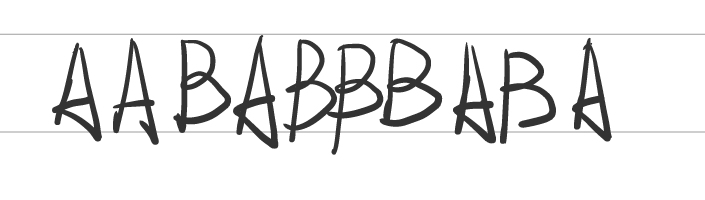
① 先从左边最短并从未出现过的短语开始,这里是A,放入字典。 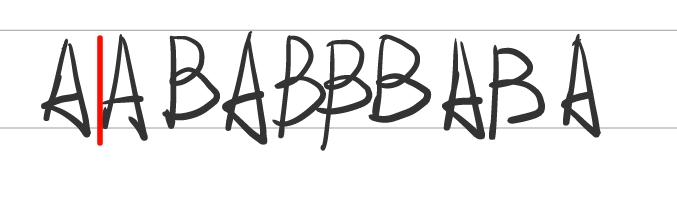
② 接下来考虑剩下的字符串,由于之前已经见过A了,匹配最长字串A,并取最长字串的下一个字符做特殊处理,取AB放入字典 
③ 再考虑剩下的字符串,由于之前已经见过A了,继续匹配下一位B,此时最长字串为AB,继续匹配下一位,未匹配到最长字串,取ABB编入词典 
④ 考虑剩下的字符串,第一个字符是B,未匹配到最长字串,编入词典 
⑤ 同理,匹配剩下的字符,匹配到最长字串AB,连同下一位编入词典 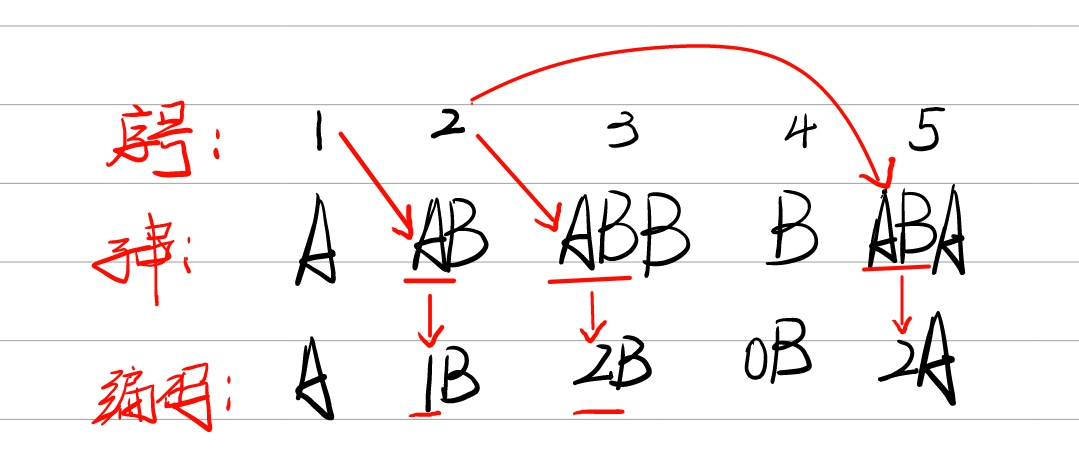
由于序号(index)2的字串AB中有A,可以用A的序号来替换字串A,编码AB为1B。同理,序号(index)3的字串ABB中有最长字串AB,可以用AB的序号替换ABB中的AB,编码为2B。序号(index)4的字串B与前面的字串没有匹配,为空集Ø,编码为0B。序号(index)5的ABA编码为2A。 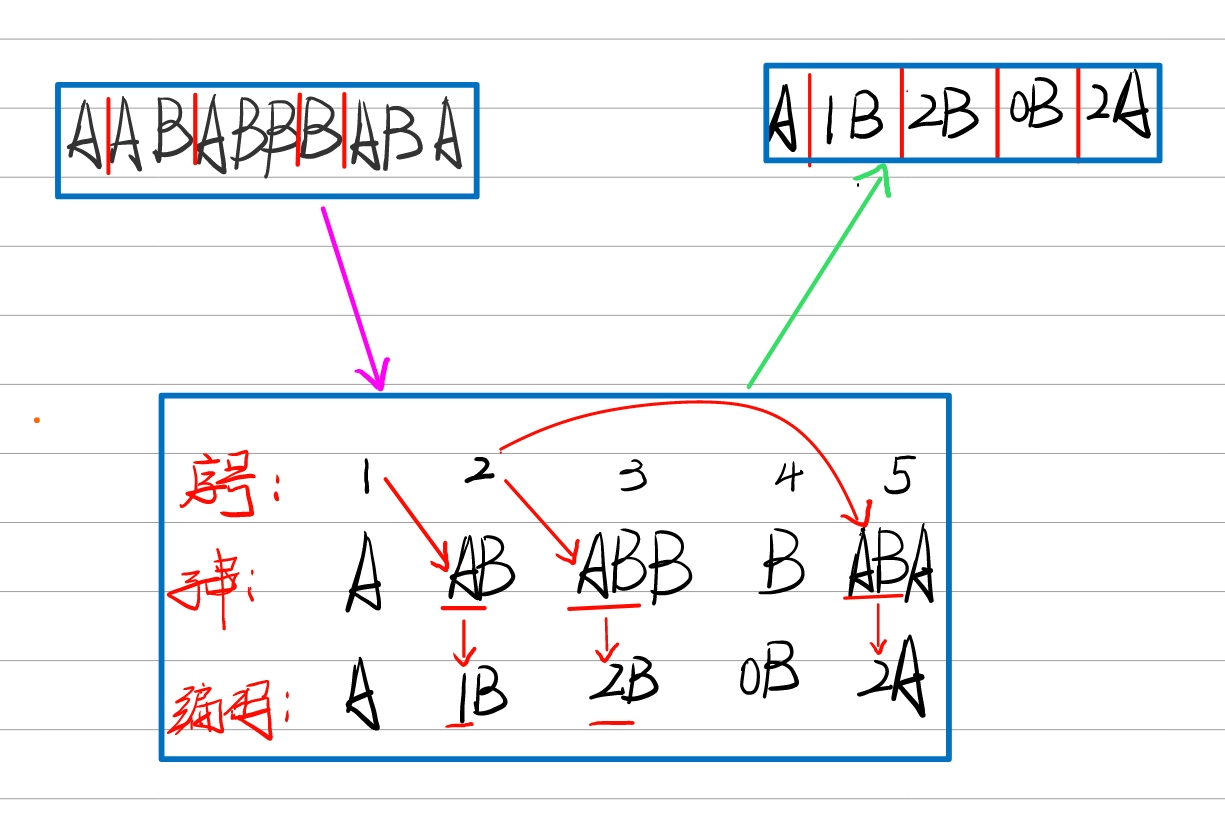
此时,我们就用字典将原来的字串编码成了一个更简单的串,简化了相关变量,此时我们只需要给A和B赋值即可得到最终编码的二进制串。这里假设A=0,B=1。 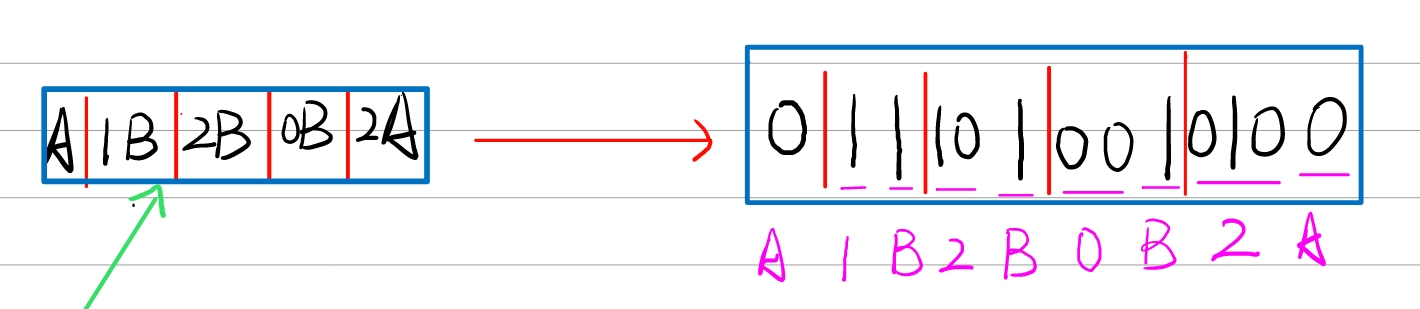
- LZ78 算法动态构建其字典,只遍历数据一次,这意味着不必在开始编码之前接收整个⽂档。
双标准数据压缩

概述
-
问题: 解决 LZ77解析的<u>压缩空间大小</u>和<u>解压缩时间</u>的问题。
-
目标:
- 确定一个 LZ77 解析,<u>在给定的时间T最小化压缩文件的空间占用</u>
- 相应的,交换时间与空间两种角色,<u>在预先给定压缩空间中最小化压缩时间</u>
- 如何实现目标:
- 引入新的 Bicriteria LZ77-Parsing 问题,它以一种原则性的方式形式化了数据压缩器传统上通过启发式方法处理问题
- 通过证明和部署加权图的一些特定结构属性,在
O(n log n²)时间和O(n)空间字中有效地解决了这个问题,直到可以忽略的附加常数输入文件的 LZ77 解析 - 进行初步实验,表明所制作的新型压缩器对市面上高度工程化的竞争对手 (如 Snappy,LZMA,Bzip2)都具有很强的竞争力。
介绍

压缩思想
随着<u>海量数据集的出现</u>以及<u>随之而来的高性能分布式存储系统的设计</u>,不少大厂纷纷行动,企图制作出一款可以实现<u>有效压缩比</u>和非常<u>高效的解压缩速度</u>的压缩器,例如 Google的<a herf="[BigTable_百度百科 (baidu.com)](https://baike.baidu.com/item/BigTable/3707131)">BigTable </a>,Facebook的<a herf="[cassandra(开源分布式NoSQL数据库系统)_百度百科 (baidu.com)](https://baike.baidu.com/item/cassandra/20140772)">Cassandra</a>,Apache的<a herf="[Hadoop_百度百科 (baidu.com)](https://baike.baidu.com/item/Hadoop)">Hadoop</a>等等,这些无不都重新点燃了科学界对更优秀的无损压缩器的设计的激情。
解决无损压缩器的有效压缩比与实现非常高效的解压缩速度之间的问题,打破性能瓶颈的方法有很多种,但从很多无损压缩器相关的论文中,都有一种思想:"<u><font color="red">compress once,decompress many times</font></u>"。(参考翻译软件及个人理解,翻译为:一次压缩,多次解压缩)。
这种思想又可以被分为两大家族,<font size="2" color="red">①</font><u>基于 Burrows-Wheeler 变换的压缩器</u>和<font size="2" color="red">②</font><u>基于 Lempel-Ziv 解析方案的压缩器</u>。  这两大家族的压缩器在压缩和解压数据时需要的时间都是线性的,并且需要的压缩空间可以用输入的K阶经验熵来约束。
这两大家族的压缩器在压缩和解压数据时需要的时间都是线性的,并且需要的压缩空间可以用输入的K阶经验熵来约束。
对两个问题的思考
一直以来,时间和空间似乎一直是算法中相互对立,但又相互依存的两个因素,经常刷 leetcode 的人一定对此深有感触,当我们解开一道算法题,很多人又会精进自己的算法,试图用“空间换时间”,“时间换空间”,以及尝试平衡两者来降低自己的执行用时和内存消耗,来获得更多的效益。 
压缩算法也是如此,要么牺牲有效压缩比,要么牺牲解压缩速度,或者尝试用强大的技巧来平衡两者,一直以来研究这个无损压缩器的人归根到底都是在研究这个问题。由于研究困难,于是引出了两个应用方面具有挑战性的问题:
-
分布式存储系统问题(时间是主要影响因素): 分布式存储系统,将数据分散存储在多台独立的设备上,可以拓展存储空间,Google,阿里等互联网公司,管理超过千万亿字节级别的大数据,它们对性能的要求很高,需要更低的解压缩时间。于是Snappy,LZ4等压缩器出现,帮助解决分布式存储系统上对解压缩时间要求更低的情况。
-
空间是主要影响因素的问题: 我们日常用的手机,手表,平板等等,这些设备对空间拓展比较难,需要尽可能在不改变其解压缩速度的情况下降低其压缩比,来让这些难以拓展内存的设备更好地利用内存。
Bicriteria Data Compression(双标准数据压缩),即解决这个问题: 
简单描述,两个参数(输入文件S,限定时间T),解决一个目标(<u>控制解压缩时间这个变量,尽可能的降低其压缩比</u>),再反过来(<u>控制其压缩比,尽可能地降低其解压缩时间</u>)。
想要解决这个问题,我们就要解决<font color="red">两个因素</font>:
-
① 将该双标准优化将在S的压缩版本中进行。 解决这个因素,原文采取基于LZ77的压缩器类别,因为它们在理论上和实践中占主导地位。使用主流压缩器,可以借鉴前人经验,帮助我们解决更多问题。
-
② 衡量待优化资源的计算模型 对于这个因素,可以从几个常用计算模型中得到启发,这些模型对多级内存层次和连续内存字的获取进行了抽象。
三大贡献:
-
- 提出新的图模型 在《On the bit-complexity of Lempel-Ziv compression》中,提出了一个特殊的加权DAG,这个DAG由<font size="2" color="red">①</font><u>
n=|S|个 节点(nodes),每个节点代表 S 的一个字符</u>和<font size="2" color="red">②</font><u>m=O(n²) 条边(edges),每条边代表 LZ77 解析 S后可能出现的短语</u>组成: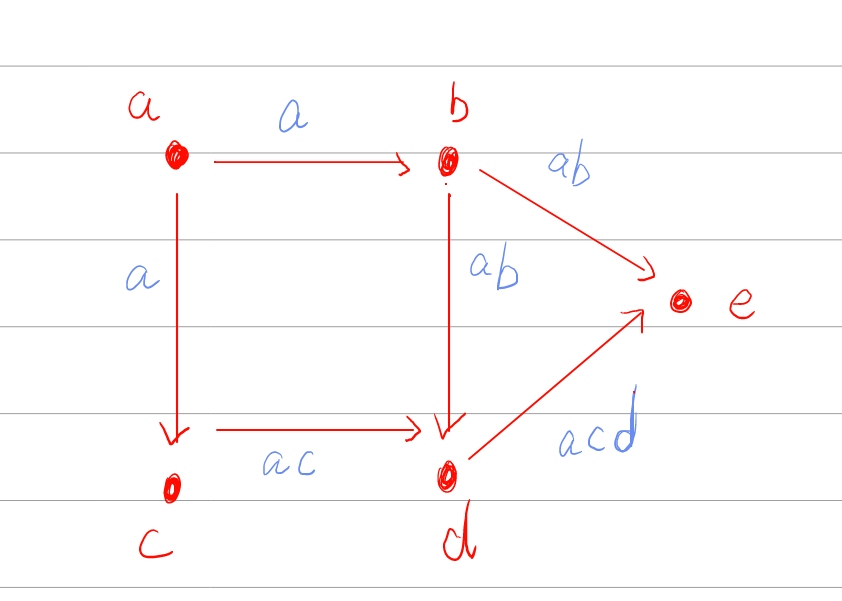
- 提出新的图模型 在《On the bit-complexity of Lempel-Ziv compression》中,提出了一个特殊的加权DAG,这个DAG由<font size="2" color="red">①</font><u>
具有两个权重(时间权重,空间成本)的新的图模型,<u><font color="red">时间权重</font>即解压缩短语的时间(根据上面提到的分层记忆模型派生)</u>,<u><font color="red">空间成本</font>即用于计算存储与该边关联的 LZ77 短语所需的位数(根据压缩机中采用的整数 编码器导出)</u>
-
- 证明并使用加权DAG的一些结构特性 之后证明了上述的加权DAG的一些结构特性,使得我们能够设计一种算法,在
O(n log² n )时间和O(n)的工作空间内近似地解决我们版本的 WCSPP。
- 证明并使用加权DAG的一些结构特性 之后证明了上述的加权DAG的一些结构特性,使得我们能够设计一种算法,在
-
- 将新的压缩器与其它压缩器对比 最后提出了一组初步的实验结果,将我们的压缩器的实现与最先进的基于LZ77 的算法(Snappy、LZMA、LZ4、gzip)和基于BWT的算法(具有有界和无界 的内存占用)进行比较。
首先,它们为本文开始时 提出的两个相关问题提供了实际依据,并为文中新颖的双标准数据压缩问题引入的理论分析。 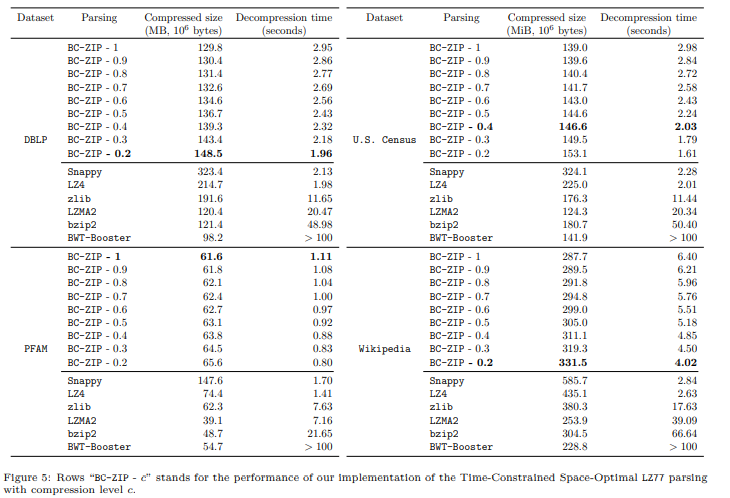
实验结果表现出文中解析策略通过表现出接近Snappy和LZ4(即已知 最快的)的解压速度,以及接近基于BWT和LZMA的压缩器(即更简洁的)的压缩率, 在所有高度工程化的竞争对手中占了优势。
连续小波变换
**连续小波变换(CWT)**通常被用于信号分析,即科学研究类。小波变换现在被大量不同的应用领域采纳,有时甚至会取代了傅里叶变换的位置,在许多领域都有这样的转变。例如很多物理学的领域亦经历了这个转变,包括分子动力学,从头计算(ab initio calculations),天文物理学,密度矩阵局部化,地球物理学,光学,湍流,和量子力学。其他经历了这种变化的学科有图像处理,血压,心率和心电图分析,DNA分析,蛋白质分析,气象学,通用信号处理,语言识别,计算机图形学,和多分形分析。
小波分析的产生是由于,最初用于处理信息的技术,FT傅里叶变换,仅可在忽略时频分量的情况下进行,但是相对于实际应用情形,绝大多数信息的时频分量是一个不可忽视的因素,为此对FT进行一定程度的优化,得到STFT即短时傅里叶变换。短时距傅立叶变换是傅立叶变换的一种变形用于决定随时间变化的信号局部部分的正弦频率和相位。实际上,计算短时距傅立叶变换(STFT)的过程是将长时间信号分成数个较短的等长信号,然后再分别计算每个较短段的傅立叶转换。通常拿来描绘频域与时域上的变化,为时频分析中其中一个重要的工具。但是在实际应用的过程中我们又遇见了新的问题,人们无法知道信号的确切时频表示,即人们无法获知在何种时间实例中存在何种频谱分量。人们可知晓的是某些频段存在的时间间隔,(其根源可以追溯到海森堡不确定性原理,但在这里我们不做详细论述。)这是一个分辨率问题。
例证:
- 我们使用的窗口函数只是一个高斯函数,形式为e^{-a \left( \frac{t^2}{2} \right)} 其中 a 确定窗口的长度,t 是时间。下图显示了由 a 的值确定的不同支持区域的四个窗口函数。请
忽略 a 的数值,因为计算此函数的时间间隔也决定了函数。只需记下每个窗口的长度即可。上面给出的示例是使用第二个值 a = 0.001 计算得出的。现在,我们将显示上面给出的与其他窗口计算的相同信号的STFT。
首先,让我们看一下第一个最窄的窗口。我们预计STFT具有非常好的时间分辨率,但频率分辨率相对较差: 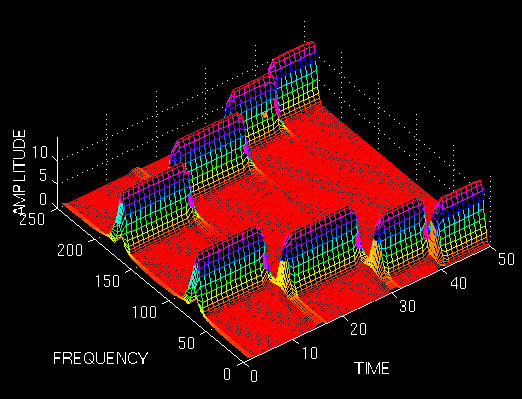
下图显示了此 STFT。该图从顶部鸟瞰图显示,并带有一个角度,以便更好地解释。请注意,这四个峰值在时间上彼此之间有很好的分离。另请注意,在频域中,每个峰值都覆盖一个频率范围,而不是单个频率值。现在,让我们将窗口变宽,并查看第三个窗口(第二个窗口已在第一个示例中显示)。 
请注意,与之前的情况不同,峰值在时间上彼此之间没有很好的分离,但是,在频域中,分辨率会进一步提升,我们进一步增加窗口的宽度。左图就明显的体现出了当窗口过宽时分辨率比较差。 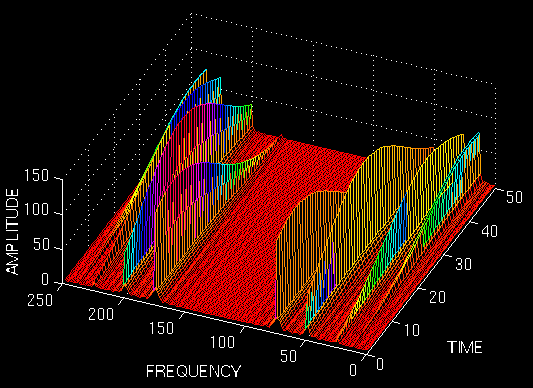
鉴于上述问题CWT(连续小波变换)应运而生。
STFT与CWT之间的两个主要区别
- 不采用窗口信号的傅里叶变换,因此将看到对应于正弦的单个峰值,即不计算负频率。
- 当为每个光谱分量计算变换时,窗口的宽度会发生变化,这可能是小波变换最重要的特征。
公式表达:
CWT_x^\psi(\tau,s) = \Psi_x^\psi(\tau,s) = \frac{1}{\sqrt{|s|}} \int x(t) \psi^* \left( \frac{t - \tau}{s} \right) dt
如上面的等式所示,变换后的信号是两个变量的函数,tau 和 s,分别是平移和标度参数。\psi(t) 是变换函数,称为母小波,母小波是用于生成其他窗口函数的原型。 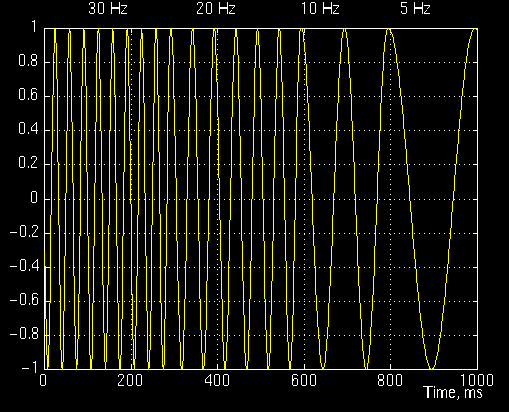 如图所示,信号由 30 Hz、20 Hz、10 Hz 和 5 Hz 的四个频率分量组成。
如图所示,信号由 30 Hz、20 Hz、10 Hz 和 5 Hz 的四个频率分量组成。
请注意,轴是平移和缩放,而不是时间和频率。然而,平移与时间严格相关,因为它指示母小波的位置。母小波的平移可以被认为是自 t = 0 以来经过的时间。
较小的刻度对应于较高的频率,即频率随着刻度的增加而降低,因此,比例约为零的图形部分实际上对应于分析中的最高频率,而具有高尺度的标度对应于最低频率。 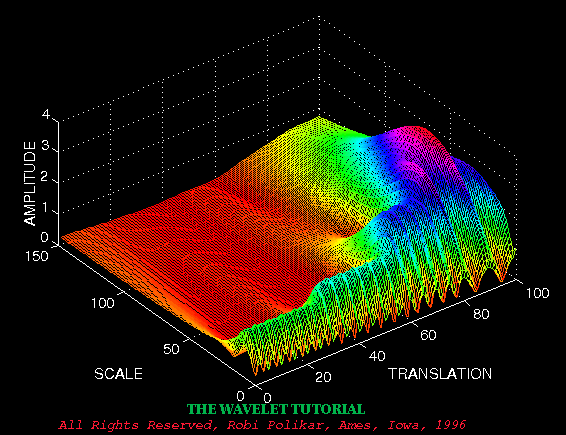
信号首先具有 30 Hz(最高频率)分量,这在 0 到 30 的转换时以最低刻度显示。然后是20 Hz分量,第二高频率,依此类推。5 Hz 分量出现在平移轴的末端(如预期的那样),并按预期再次以较高的比例(较低频率)显示。 
OpenHarmony内核子系统之Linux
OpenHarmony的Linux内核基于开源Linux内核LTS 4.19.y / 5.10.y 分支演进,在此基线基础上,回合CVE补丁及OpenHarmony特性,作为OpenHarmony Common Kernel基线。针对不同的芯片,各厂商合入对应的板级驱动补丁,完成对OpenHarmony的基线适配。
EROFS文件系统
EROFS 文件系统代表增强型只读文件系统。与其他只读文件系统不同,它旨在为灵活性、可扩展性而设计,但要保持简单和高性能。EROFS由华为于2018年开源,现已合入Linux内核主线,在4.19版本发布: 
数据压缩
- EROFS 实现了
LZ4 固定大小算法的输出压缩,与其他现有的固定大小的输入解决方案相比,它从可变大小的输入生成固定大小的压缩数据块。使用固定大小的输出压缩可以获得相对更高的压缩率,因为现在流行的数据压缩算法大多基于 LZ77,这种固定大小的输出方法可以从历史字典中受益。 - 具体来说,原始数据被转换成几个
可变大小的范围,同时被压缩成物理集群。为了记录每个可变大小的范围,引入逻辑簇作为压缩索引的基本单元,以指示是否在范围内生成新的范围。
|<- variable-sized extent ->|<- VLE ->|
clusterofs clusterofs clusterofs
| | |
_________v_________________________________v_______________________v________
... | . | | . | | . ...
____|____._________|______________|________.___ _|______________|__.________
|-> lcluster <-|-> lcluster <-|-> lcluster <-|-> lcluster <-|
(HEAD) (NONHEAD) (HEAD) (NONHEAD) .
. CBLKCNT . .
. . .
. . .
_______._____________________________.______________._________________
... | | | | ...
_______|______________|______________|______________|_________________
|-> big pcluster <-|-> pcluster <-|
由此可见,操作系统性能的提升能力一定程度上取决于其所采用的文件系统,压缩算法是文件系统设计上尤其重要同时又是不可或缺的一环。按照以上思路,我们得到如下具体实例:
/dev/block/dm-6 on / type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
tmpfs on /dev type tmpfs (rw,seclabel,nosuid,relatime,size=3827176k,nr_inodes=956794,mode=755)
devpts on /dev/pts type devpts (rw,seclabel,relatime,mode=600,ptmxmode=000)
proc on /proc type proc (rw,relatime,gid=3009,hidepid=2)
sysfs on /sys type sysfs (rw,seclabel,relatime)
selinuxfs on /sys/fs/selinux type selinuxfs (rw,relatime)
tmpfs on /mnt type tmpfs (rw,seclabel,nosuid,nodev,noexec,relatime,size=3827176k,nr_inodes=956794,mode=755,gid=1000)
tmpfs on /apex type tmpfs (rw,seclabel,nosuid,nodev,noexec,relatime,size=3827176k,nr_inodes=956794,mode=755)
/dev/block/dm-5 on /patch_hw type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/sdd66 on /metadata type ext4 (rw,seclabel,nosuid,nodev,noatime,discard,data=ordered)
/dev/block/dm-7 on /cust type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /hw_product type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-9 on /odm type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-10 on /preas type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-11 on /preload type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-12 on /vendor type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-13 on /vendor/modem/modem_driver type ext4 (ro,seclabel,relatime,data=ordered)
/dev/block/dm-14 on /vendor/preavs type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-15 on /version type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
none on /dev/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
none on /dev/cg2_bpf type cgroup2 (rw,nosuid,nodev,noexec,relatime)
none on /dev/cpuctl type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
none on /acct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
none on /dev/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset,noprefix,release_agent=/sbin/cpuset_release_agent)
none on /dev/memcg type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
none on /dev/stune type cgroup (rw,nosuid,nodev,noexec,relatime,schedtune)
debugfs on /sys/kernel/debug type debugfs (rw,seclabel,relatime)
none on /config type configfs (rw,nosuid,nodev,noexec,relatime)
bpf on /sys/fs/bpf type bpf (rw,nosuid,nodev,noexec,relatime)
pstore on /sys/fs/pstore type pstore (rw,seclabel,nosuid,nodev,noexec,relatime)
none on /dev/iolimit type cgroup (rw,relatime,iolimit)
overlay on /system/lib type overlay (ro,seclabel,relatime,lowerdir=/patch_hw/overlay/system/lib:/system/lib)
overlay on /system/lib64 type overlay (ro,seclabel,relatime,lowerdir=/patch_hw/overlay/system/lib64:/system/lib64)
none on /mnt/update_engine type tmpfs (rw,seclabel,nosuid,nodev,relatime,size=3827176k,nr_inodes=956794,mode=700)
none on /dev/workingset type cgroup (rw,nosuid,nodev,noexec,relatime,workingset)
adb on /dev/usb-ffs/adb type functionfs (rw,relatime)
hdb on /dev/usb-ffs/hdb type functionfs (rw,relatime)
none on /dev/frz type cgroup (rw,relatime,freezer)
/dev/block/sdd7 on /sec_storage type ext4 (rw,context=u:object_r:teecd_data_file:s0,nosuid,nodev,noatime,discard,nodelalloc,data=journal)
tracefs on /sys/kernel/debug/tracing type tracefs (rw,seclabel,relatime)
/dev/block/sdd18 on /splash2 type ext4 (rw,context=u:object_r:splash2_data_file:s0,nosuid,nodev,noatime,data=ordered)
/dev/block/sdd72 on /data type f2fs (rw,seclabel,nosuid,nodev,noatime,background_gc=on,discard,no_heap,user_xattr,inline_xattr,acl,inline_data,inline_dentry,extent_cache,mode=adaptive,inline_encrypt,sdp_encrypt,active_logs=6,alloc_mode=default,fsync_mode=posix)
/dev/block/sdd23 on /cache type ext4 (rw,seclabel,nosuid,nodev,noatime,data=ordered)
overlay on /system/product/priv-app type overlay (ro,seclabel,relatime,lowerdir=/preas/priv-app:/system/product/priv-app)
overlay on /system/product/app type overlay (ro,seclabel,relatime,lowerdir=/preas/app:/system/product/app)
overlay on /system/product/etc/permissions type overlay (ro,seclabel,relatime,lowerdir=/preas/china/permissions:/system/product/etc/permissions)
/dev/block/sdd3 on /mnt/modem/modem_secure type ext4 (rw,context=u:object_r:modem_secure_file:s0,noatime,noauto_da_alloc,data=ordered)
/dev/block/sdd51 on /vendor/modem/modem_fw type ext4 (ro,context=u:object_r:modem_fw_file:s0,relatime,data=ordered)
/dev/block/sdd10 on /mnt/modem/mnvm2:0 type ext4 (rw,context=u:object_r:modem_nv_file:s0,nosuid,nodev,noatime,noauto_da_alloc,data=ordered)
tmpfs on /storage type tmpfs (rw,seclabel,nosuid,nodev,noexec,relatime,size=3827176k,nr_inodes=956794,mode=755,gid=1000)/dev/block/loop2 on /apex/com.android.apex.cts.shim@1 type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop2 on /apex/com.android.apex.cts.shim type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop3 on /apex/com.android.conscrypt@292103000 type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop3 on /apex/com.android.conscrypt type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop4 on /apex/com.android.media@292103016 type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop4 on /apex/com.android.media type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop5 on /apex/com.android.media.swcodec@292103012 type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop5 on /apex/com.android.media.swcodec type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop6 on /apex/com.android.resolv@292103001 type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop6 on /apex/com.android.resolv type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop7 on /apex/com.android.runtime@1 type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop7 on /apex/com.android.runtime type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop8 on /apex/com.android.tzdata@292103002 type ext4 (ro,dirsync,seclabel,nodev,noatime)
/dev/block/loop8 on /apex/com.android.tzdata type ext4 (ro,dirsync,seclabel,nodev,noatime)
none on /sys/fs/cgroup type tmpfs (rw,seclabel,relatime,size=3827176k,nr_inodes=956794,mode=750,gid=1000)
none on /sys/fs/cgroup/pids type cgroup (rw,relatime,pids)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/translation.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/voicekit.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/dm-ondeviceai.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-facecluster-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-facecompare-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-videomulti-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-videosemantic-common-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-txtimagesr-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/compatible-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-screenshotocr-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-headpose-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-segsemantic-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-tableocr-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/asr.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/nlu-full.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/tts.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-labelobjectdetect-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-portraitseg-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/computecapability-common.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-videoanalysis-common-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-faceparsing-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-labeldetect-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-focusocr-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-scene-common-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-multiobjectdetect-cpu-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-sisr-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-facedetect-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-barcode-common-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-carddetect-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-aestheticsfull-cpu-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-docconverter-common-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-facerating-cpu-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-faceattribute-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-facelandmark-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-clothing-orlando-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-docrefine-common-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-8 on /data/app/com.huawei.hiai-N_iI4NIgGtBfIypkf94yJw==/visionplugin-tracking-common-china-release.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-6 on /data/app/com.huawei.systemmanager-d1_lLcBuvKjGe4gAL6voYA==/AiSecurityPlugin.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-6 on /data/app/com.huawei.systemmanager-d1_lLcBuvKjGe4gAL6voYA==/AntimalPlugin.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-6 on /data/app/com.huawei.systemmanager-d1_lLcBuvKjGe4gAL6voYA==/WlanSecurePlugin.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-6 on /data/app/com.huawei.behaviorauth-qn46_LzogY1uYUaAKOhlnA==/HwBehaviorAuth.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-6 on /data/app/com.android.settings-uITFrNjy4jz1Gl0p_aRLBQ==/Resolution.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/dev/block/dm-6 on /data/app/com.android.settings-uITFrNjy4jz1Gl0p_aRLBQ==/SettingsTheme.apk type erofs (ro,seclabel,relatime,user_xattr,lz4asm)
/data/media on /mnt/runtime/default/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=1015,multiuser,mask=6,derive_gid,default_normal,reserved=20MB,unshared_obb)
/data/media on /storage/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=1015,multiuser,mask=6,derive_gid,default_normal,reserved=20MB,unshared_obb)
/data/media on /mnt/runtime/read/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=9997,multiuser,mask=23,derive_gid,default_normal,reserved=20MB,unshared_obb)
/data/media on /mnt/runtime/write/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=9997,multiuser,mask=7,derive_gid,default_normal,reserved=20MB,unshared_obb)
/data/media on /mnt/runtime/full/emulated type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=9997,multiuser,mask=7,derive_gid,default_normal,reserved=20MB,unshared_obb)
/data/misc_ce/0/kdfs/storage on /mnt/mdfs/.hmdfs type hmdfs (rw,relatime,sensitive,merge_enable,ra_pages=128,account=10143583112313917499,recv_uid=1023,cache_dir=/data/misc_ce/0/kdfs/cache/16448759908547494974,real_dst=/mnt/mdfs/.hmdfs,offline_stash,dentry_cache)
/data/misc_ce/0/kdfs/storage on /mnt/mdfs/account_trust type hmdfs (rw,relatime,sensitive,merge_enable,ra_pages=128,account=10143583112313917499,recv_uid=1023,cache_dir=/data/misc_ce/0/kdfs/cache/16448759908547494974,real_dst=/mnt/mdfs/.hmdfs,offline_stash,dentry_cache)
/data/media/0 on /mnt/mdfs/sdcard type hmdfs (rw,relatime,insensitive,merge_disable,ra_pages=128,account=10143583112313917499,recv_uid=1023,cache_dir=/data/misc_ce/0/kdfs/cache/16448759910518911873,real_dst=/mnt/mdfs/sdcard,offline_stash,dentry_cache)
/mnt/media_rw on /mnt/mdfs/external_storage type hmdfs (rw,relatime,insensitive,merge_disable,ra_pages=128,account=10143583112313917499,recv_uid=1023,cache_dir=/data/misc_ce/0/kdfs/cache/14998924782874330279,real_dst=/mnt/mdfs/external_storage,no_offline_stash,dentry_cache,external_storage)
/data/misc_ce/0/kdfs/storage on /mnt/mdfs/10143583112313917499 type hmdfs (rw,relatime,sensitive,merge_enable,ra_pages=128,account=10143583112313917499,recv_uid=1023,cache_dir=/data/misc_ce/0/kdfs/cache/16448759908547494974,real_dst=/mnt/mdfs/.hmdfs,offline_stash,dentry_cache)
/dev/fuse on /mnt/appfuse/10008_2 type fuse (rw,fscontext=u:object_r:app_fusefs:s0,context=u:object_r:app_fuse_file:s0,nosuid,nodev,noexec,noatime,user_id=0,group_id=0,default_permissions,allow_other)
mdfs on /mnt/mdfs/groups type fuse (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other)
我们对其进行整理,得到如下参考表格:
| 目录/设备 | 挂载点 | 文件系统 | 键值 | 备注 |
|---|---|---|---|---|
| /dev/block/dm-6 | / | erofs | ro,seclabel,relatime,user_xattr,lz4asm | 系统盘采用华为自研开源EROFS文件系统 面向终端场景 减小了元数据 随机读取性能有明显提高 |
| tmpfs | /storage | tmpfs | rw,seclabel,nosuid,nodev,noexec,relatime,size=3827176k,nr_inodes=956794,mode=755,gid=1000 | 内部存储目录 采用tmpfs临时文件系统 对应于/tmp或swap 在内存利用上有很大价值 |
| /dev/block/sdd72 | /data | f2fs | rw,seclabel,nosuid,nodev,noatime,background_gc=on,discard,no_heap,user_xattr,inline_xattr,acl,inline_data,inline_dentry,extent_cache,mode=adaptive,inline_encrypt,sdp_encrypt,active_logs=6,alloc_mode=default,fsync_mode=posix | 应用核心数据目录 采用18个月不卡的F2FS格式 减轻了存储器内部处理负担 |
| /dev/block/sdd66 | /metadata | ext4 | rw,seclabel,nosuid,nodev,noatime,discard,data=ordered | 各种元数据及缓存目录 采用常规第四代扩展格式 门槛相对较低 优化后可显著提高运行性能 |
| /dev/block/sdd7 | /sec_storage | ext4 | rw,context=u:object_r:teecd_data_file:s0,nosuid,nodev,noatime,discard,nodelalloc,data=journal | |
| /dev/block/sdd23 | /cache | ext4 | rw,seclabel,nosuid,nodev,noatime,data=ordered | |
| /data/media/0 | /mnt/mdfs/sdcard | hmdfs | rw,relatime,insensitive,merge_disable,ra_pages=128,account=10143583112313917499,recv_uid=1023,cache_dir=/data/misc_ce/0/kdfs/cache/16448759910518911873,real_dst=/mnt/mdfs/sdcard,offline_stash,dentry_cache | 数据媒体存取目录 采用鸿蒙全自研跨设备HMDFS 支持多设备数据融合 4倍Samba性能 |
| /mnt/media_rw | /mnt/mdfs/external_storage | hmdfs | rw,relatime,insensitive,merge_disable,ra_pages=128,account=10143583112313917499,recv_uid=1023,cache_dir=/data/misc_ce/0/kdfs/cache/14998924782874330279,real_dst=/mnt/mdfs/external_storage,no_offline_stash,dentry_cache,external_storage | |
| /data/media | /mnt/runtime/default/emulated | sdcardfs | rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=1015,multiuser,mask=6,derive_gid,default_normal,reserved=20MB,unshared_obb | 数据媒体运行时存取目录 sdcardfs管理被作为外部存储的/sdcard目录 若对其进行优化 外存性能的提高极其有助于系统整体性能的提高 |
LZ4 固定大小输出算法
块格式
- LZ4 是 LZ77 型压缩器,具有
固定的、面向字节的编码。没有熵编码器后端,也没有成帧层。假设后者由系统的其他部分处理,这种设计有利于简易及速度,有助于以后进行优化、紧凑及增强功能。
压缩块格式
- LZ4 压缩块由序列组成。序列是
一组文字(未压缩的字节),后跟一个匹配副本。每个序列都从一个标记开始。标记是一个字节值,分为两个4 位字段。因此,每个字段的范围从0 到 15。第一个字段使用了标记的4 个高比特位,它提供了要遵循的文字的长度。 - 如果字段值为 0,则没有文字。如果是15,那么需要多加一些字节来表示全长,然后每个额外的字节代表一个
从 0 到 255 的值,该值被添加到前一个值以产生总长度。当字节值为 255 时,必须读取并添加另一个字节,以此类推。标记后面可以有任意数量的值为“255”的字节,无大小限制:
示例 1:文字长度 48 表示为:
15:4 位高字段的值
33 : (=48-15) 剩余长度达到 48
示例 2:文字长度 280 表示为:
15:4 位高字段的值
255 : 后面的字节最大,因为 280-15 >= 255
10 : (=280 - 15 - 255) ) 剩余长度达到 280
示例 3:文字长度 15 表示为:
15:4 位高字段的值
0 : (=15-15) 必须输出零
- 在标记和可选长度字节之后,是文字本身。它们的数量
与之前解码的一样多(字面量长度),字面量可能为零。文字之后是匹配复制操作。它从偏移量开始,是一个 2 字节的值,采用小端格式(第一个字节是“低”字节,第二个是“高”字节),偏移量表示要复制的匹配的位置。例如,1 表示“当前位置 - 1 个字节”。最大偏移值为 65535,65536 及以上无法编码。0 是无效的偏移值。这种值的存在表示无效*(损坏)*块。 - 然后可以
提取匹配长度。为此,我们使用第二个标记字段,即低 4 位。显然,这个值的范围是 0 到 15。但是在这里,0 意味着复制操作是最小的。匹配的最小长度称为 minmatch,为 4。因此,0 值表示 4 个字节,15 值表示 19+ 个字节。与文字长度类似,在达到可能的最高值 (15) 时,必须读取额外的字节,一次一个,值范围从 0 到 255。它们被添加到总数中以提供最终匹配长度。 255 值意味着还有另一个字节要读取和添加。可以存在的可选“255”字节的数量没有限制。(注意:这指向大约 250 的最大可实现压缩比)。 - 解码匹配长度到达当前序列的末尾。下一个字节是另一个序列的开始。但在移动到下一个序列之前,这时需要
使用解码的匹配位置和长度了。解码器将 matchlength 字节从匹配位置复制到当前位置。 - 在某些情况下,matchlength
可以大于offset。因此,由于 match_pos + matchlength > current_pos,稍后要复制的字节尚未解码,这称为**“重叠匹配”**,需要特别小心处理。<u>常见的情况是偏移量为 1,这意味着最后一个字节重复 matchlength 次。</u>
区块限制终止
- 终止 LZ4 块需要特定的限制:
- 最后一个序列只包含文字,块在他们之后结束
- 输入的最后 5 个字节始终是文字。因此,最后一个序列至少包含 5 个字节
- 特别的,如果输入小于 5 个字节,则只有一个序列,它包含整个输入作为文字。空输入可以用零字节表示,解释为没有文字和匹配的最终标记
- 最后一个匹配必须在块结束前至少 12 个字节开始,紧随其后的是最后一个序列,它只包含文字
- 需要注意,不能压缩 < 13 字节的独立块,因为匹配必须复制“某些东西”,因此至少需要一个前字节
- 但是,当一个块可以引用另一个块的数据时,它可以立即以匹配方式而非文字开始,因此可以压缩正好为 12 个字节的块
当某一个块不符合以上这些终止条件时,允许一致的解码器将会视该块为错误从而拒绝; 这些条件是为了确保与各种历史解码器之间的兼容性,解码器在面向速度的设计中依赖它们。
参考文献
[1] Deorowicz S . Universal Lossless Data Compression Algorithms[J]. Philosophy Dissertation Thesis, 2003. [2] Burrows M , Wheeler D J . A Block-Sorting Lossless Data Compression Algorithm[J]. technical report digital src research report, 1995. [3] Gao X , Dong M , Miao X , et al. EROFS: a compression-friendly readonly file system for resource-scarce devices. 2019. [4] Ni G . Research on BWT and Classical Compression Algorithms[J]. Computer & Digital Engineering, 2010. [5] Farruggia A , Ferragina P , Frangioni A , et al. Bicriteria data compression[J]. Society for Industrial and Applied Mathematics, 2013. [6] Alakuijala J , Farruggia A , Ferragina P , et al. Brotli: A General-Purpose Data Compressor[J]. ACM Transactions on Information Systems, 2018, 37(1):1-30. [7] Overview - The Hitchhiker's Guide to Compression (go-compression.github.io) [8] Wavelet Tutorial - Part 1 [9] Wavlet Tutorial - Part 2 [10] Wavelet Tutorial - Part 3
|








- 上一条: OpenHarmony移植:如何适配utils子系统之KV存储部件 2022-02-25
- 下一条: OpenHarmony移植:XTS子系统之应用兼容性测试套件 2022-03-15
- 【ELT.ZIP】OpenHarmony啃论文俱乐部——云计算数据压缩方案 2022-05-10
- 【ELT.ZIP】OpenHarmony啃论文俱乐部——轻翻那些永垂不朽的诗篇 2022-03-29
- 等个有“源”人|OpenHarmony 成长计划学生挑战赛报名启动 2022-06-13
- Lepton 无损压缩原理及性能分析 2022-07-05
- 数仓无损压缩算法:gzip算法 2021-10-28


