比特跳动公司的二面
在上周通过著名公司【比特跳动】的一面之后,程序员小扎迎来了至关重要的二面,很往常一样,今天小扎的身体又不舒服了,按照惯例和领导请了半天假。由于早上要去现场面试了,早早起床的小扎快速的完成了洗漱,穿上格子衬衣,背个电脑包,骑上共享单车,提前半小时来到了比特跳动公司了。“你好,我是小扎,我是来面试的”,程序员小扎和美丽的前台小姐姐说道,“好的,稍等,面试官还没到,我先领你到这边会议室,你先等会”。
在等了大概半小时后,一位大腹便便的老面试官走了进来,这时他们面面相觑,双方都笑了,因为他们撞衫了,在尴尬之后,双方点头示意,老面试官一本正经的端坐在椅子上,看着小扎的简历,心想:至今10个人有9个跪在我这里,况且如果让你过了,以后我这个典藏的格子衬衣还能穿吗,今天得放大招了。小扎万万没想到今天因为一件格子衬衣,让他陷入一场苦战。
Redis篇
「老面试官」:如果要实现一个排行的功能,你有什么想法?
「小扎」:可以用Redis的zset,把要参与排序的权重作为分值,设置到zset中。
「老面试官」:那如果我要知道小明的排名,该用什么命令呢?
「小扎」:(这老东西,竟然问这么细),用zrank key 小明即可获得小明的排名。
「老面试官」:那zset的底层是什么数据结构?
「小扎」:用的跳跃表。
「老面试官」:那你给我介绍下跳跃表的好处是什么?
「小扎」:(。。。,看来这是个面霸),好的,我们先来看看没有跳跃表的时候会怎么样:

比如现在如果我要找7这个数字,那么由于zset是顺序的,只能重头开始一个一个找,要找到最后(1->2->3->4->5->6->7),很显然,速度是挺慢的,但是如果现在我给1、4、7分别再加一层
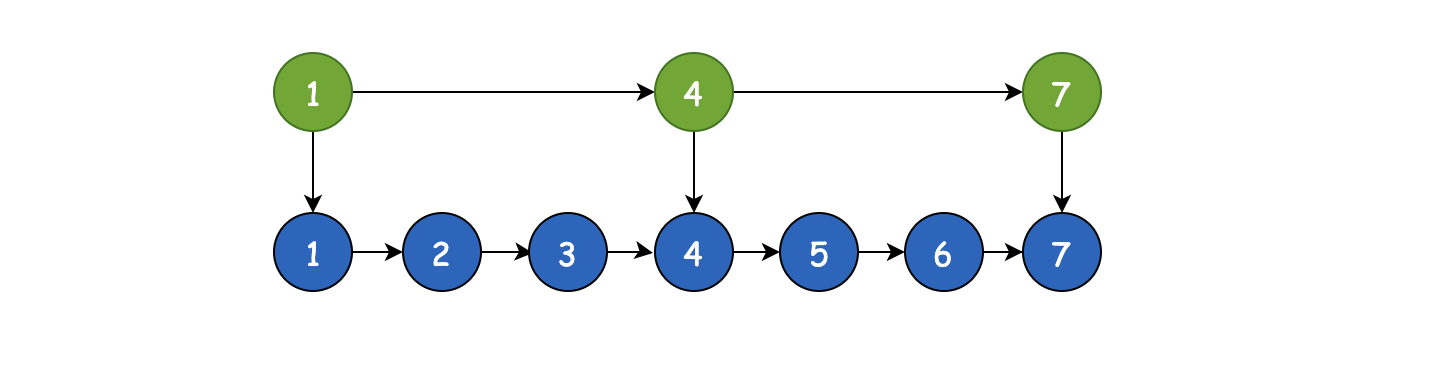
那么此时找7,只需要1->4->7三步即可,大大减少了时长,这就是跳跃表的好处。
「老面试官」:那Redis的zet除了使用跳跃表还有使用其他的数据结构吗?

「小扎」:(这是要打破砂锅问到底呀~,今天我是和你刚上了),还有hash表,hash表记录了value和score的映射,比如我要取某个成员的分值时,通过hash可以达到O(1)的时间复杂度。
「老面试官」:这样啊,那还有其他数据结构吗?
「小扎」:嗯~(竟然还有其他的,这是要败了呀!等等,我好像想到了什么),我记得好像某些情况下,zset会使用压缩列表,比如在键值对数量少于128个且每个元素的长度小于64字节的时候,zset会使用压缩列表来实现。
「老面试官」:那你能解释下为什么这时候使用压缩列表吗?
「小扎」:是这样的,首先我们知道如果使用跳跃表来实现可以发现因为有不同的层高,因此需要更多的存储空间,但是在数据量不多的情况下,就算重头开始遍历应该也是很快的,但是消耗的内存空间可以更小,这是速度与存储之间的综合考虑吧。
老面试官陷入沉思(这小子不错嘛,这个知识点没啥问的了,再深入我也不会了)。
「老面试官」:我们知道Redis很快,但是你知道哪些操作会导致Redis慢吗?
「小扎」:(这还跟我拐弯抹角呢),你说的是什么会导致Redis阻塞是吧~
「老面试官」:可以这样理解。
「小扎」:首先不要使用keys *命令,这个命令会导致Redis扫描所有的key,那么在没有扫描完成之前,其他的命令会被阻塞。
「老面试官」:那要如何避免这种情况呢?
「小扎」:生产环境一般建议禁止使用这个命令,同时如果要模糊查询某些key,可以通过scan扫描法来检索。
「老面试官」:嗯嗯,那还有其他导致阻塞的原因吗?
「小扎」:有的,操作大key,当我们写入一个大key的时候,会导致redis需要分配更多的内存,这个过程相对耗时,删除一个大key的时候,释放更多的空间也相对耗时。
「老面试官」:不好意思,我打断一下,你说的删除大key会阻塞是吧,那有什么方法删除不阻塞吗?
「小扎」:(强颜欢笑),在Redis4.0版本以后支持,大key支持异步删除,这样可以不阻塞主线程。
「老面试官」:你继续。
「小扎」:好的,当使用一些复杂的指令时可能也会造成阻塞,比如Redis里有个类型叫集合,如果要取多个集合的并集有个指令叫做sunion,当我们sunion多个集合的时候,除了单纯的合并数据以外,Redis还会去重,这个操作不仅耗费内存还会相对耗费CPU,所以可能会阻塞,尤其在数据很多的时候。还有比如AOF持久化使用的是always方案,即每次都刷盘,在QPS较高的情况下,可能会造成阻塞。
「老面试官」:等等,我再打断下,你说的always能具体再说说吗,平时开启AOF,难道不是直接写磁盘吗?
「小扎」:正常情况下,当我们写一个数据到文件的时候,其实是写入的文件系统的缓冲区的,并没有真正的刷到磁盘上,因为磁盘是缓慢的,操作系统为了提升性能,会在缓冲区快满的时候或者定期执行刷盘操作,这样做的好处可以节省多次磁盘IO,但是有丢失数据的风险,Redis的AOF设置成always的意思就是,每次写AOF的时候直接将缓冲区的数据刷入磁盘中。
「老面试官」:(解释的还行),那你继续。

「小扎」:(打断这么多次,我讲到哪了~),哦,如果内存快满了,这时候新的写入可能会导致Redis进行内存淘汰,这个过程可能会相对慢些,大概就这么多
「老面试官」:(还行吧,不会是背的八股文吧,我再来引导看看他的反应如何)嗯~,你知道Redis是如何删除过期key的吗?
「小扎」:这个知道,一共分为两种,一种是惰性删除,一种是定时删除,惰性删除就是我们在读某个key的时候,如果发现已经过期了,那么就顺带删除。定时删除是Redis内部有个定时程序,每隔一段时间会随机检索一批key,检查他们是否过期,过期的话,就删除。
「老面试官」:那如果在某一瞬间,大量的请求进来,并且每个请求的key是不同的,同时每个key都是过期的,这时会出现什么现象。
「小扎」:哦哦,会触发惰性删除,那么就会导致Redis去释放内存,可能会造成阻塞。这也是造成Redis可能阻塞的一个原因。(尴尬,竟然没想到这点,这下他耀武扬威了)。
「老面试官」:(还不错,能想到这个点,不过我背的面试题也就这么多,换个话题吧)

Golang篇
老面试官再次看了看简历,说到:原来你是面试go开发的。
「小扎」:(我xx,现在才发现)是的。
「老面试官」:那我来问问go相关的知识吧,先说说map是线程安全的吗?
「小扎」:不是。
「老面试官」:那如何解决map并发读写的问题呢?
「小扎」:可以加锁,比如sync.Mutex 。
「老面试官」:加锁性能会不会很差?
「小扎」:有点,如果是读多写少的情况下,可以使用sync.map 。
「老面试官」:sync.map为什么适合读多写少的情况?
「小扎」:sync.map其实是用的是空间换时间的思想,它内部其实有两个map,一个是叫read,只提供读的,存的数据是atomic.Value类型,因此读是线程安全的,在大量读的情况下,是不需要加锁的,还有个叫dirty的map,新数据的写入是进dirty的,当我们read map中没读到数据的时候会去dirty中读,这个过程是要加锁的,同时在read miss一定次数后,就会把dirty的数据复制给read,这样read的数据就是最新的了,综合来看相比常规的map无脑加锁,sync.map的读大部分场景还是不需要加锁的,因此在读多写少的情况下,性能还是不错的。
「老面试官」:那slice是线程安全的吗?
「小扎」:slice也不是线程安全的,但是在发生并发的时候,slice不会panic,会存在数据覆盖的问题。
「老面试官」:slice和数组是什么关系?
「小扎」:slice的底层就是引用的数组。
「老面试官」:数组之间是能比较的吗?
「小扎」:同类型的数组是可以比较的,比如[2]int{1,2}和[2]int{2,3},但是如果是[2]int{1,2}和[3]int{1,2,3}是不能比较的,此时连编译都不能通过。
「老面试官」:那slice之间是可以比较的吗?
「小扎」:slice之间是不能比较的,slice只能和nil比较。
「老面试官」:那如果两个都是nil的slice呢?比如:
var a []int
var b []int
fmt.Println(a == b)
「小扎」:也是不行的,正如前面说的,slice只能和nil比较。
「老面试官」:chan有哪些类型?并说说他们的区别
「小扎」:带缓冲的和不带缓冲的,对于不带缓冲的chan来说,应用场景就是阻塞的,对于带缓冲的chan来说,在缓冲没有满的时候可以不阻塞,满了之后就阻塞了。
「老面试官」:给一个已经close的chan发数据会发生什么?
「小扎」:会panic。
「老面试官」:那从一个已经close的chan取数据会发生什么?
「小扎」:会得到chan类型的零值,比如int类型的chan就会拿到0。
MySQL篇
「老面试官」:平时用MySQL多吗?
「小扎」:还行,基本数据存储都用MySQL
「老面试官」:那你先说说唯一索引和普通索引区别
「小扎」:唯一索引会有唯一性校验,而普通的索引没有这个校验,但是在索引的结构上,它们没什么区别,都是B+树索引
「老面试官」:可以从插入和查询方面来介绍他们的区别吗?
「小扎」:(。。。果然不简单)好的,从插入方面来说,由于唯一索引需要唯一性,因此要先确认数据是否已经存在,但是普通索引就不需要检验唯一性,找到合适位置无脑插入即可。从查询方面来说,对唯一索引来说,因为唯一性的原因,在查到第一个满足的数据立即返回即可,但是对于普通索引来说,因为是非唯一的,那么就不知道后面还有多少数据,只能继续向后检索,直至找到第一个不满足的数据为止,因此其实非唯一索引其实是要多检索一条数据的。
「老面试官」:嗯,change buffer了解吗?了解的话,说说change buffer的好处。
「小扎」:(不了解的话,是不是出门右拐...),了解一点,change buffer主要是为了减少离散的磁盘IO的。
「老面试官」:哦~,细说看看。
「小扎」:首先正常我们更新一个数据的时候,如果对应的数据不在内存里的话,就要先去磁盘把对应的数据页读到内存里,然后更新,如果每次更新都要去磁盘读一次的话,性能会稍差,于是就出现了change buffer,change buffer的好处就是即使数据不在内存里,也不去磁盘上读,把要更新的数据先放在change buffer里,然后后台有个线程定时去把change buffer的数据同步到磁盘上,这样的话,当同一个数据页上发生多次变更,只需要merge一次到磁盘上。
「老面试官」:等等,你说后台有个线程定时去把数据merge到磁盘上?那如果还没来的及merge,另一个线程发生了读,该怎么办?
「小扎」:如果线程还没来得及同步,但是又发生了读操作,那么也会触发把change buffer的数据merge到磁盘的事件。
「老面试官」:那是不是所有的索引数据都用change buffer就可以得到极大的收益?
「小扎」:(有坑),不是的,唯一索引就用不到,唯一索引必须要要确认数据的唯一性,因此如果数据不在内存里,就必须去磁盘读取数据确认是否已经存在。
「老面试官」:(8错8错,难道我的格子衬衣要退休了吗),那你说说InnoDB存储引擎的隔离级别吧~
「小扎」:有读未提交、读提交、可重复读、串行化。
「老面试官」:读提交会造成什么?
「小扎」:读提交主要会造成不可重复读的问题。(想让我掉坑吗,幻读是属于可重复读的,小菜一碟)。
「老面试官」:说说MySQL中DECIMAL(M,D) 中M和D分别代表什么?
「小扎」:M是最大位数,D是小数点右边的位数 比如decimal(5,2),最大可以表示999.99。
「老面试官」:那你再说说varchar和char的区别吧
「小扎」:varchar是变长,char是定长,在存取方面定长的char更快一点,但是当用char来存储的数据位数不够时,会导致用空格填充,同时char最大可存储255个字符长度,而对于varchar来说,当存储的字符串长度小于255字节时,其需要1字节的空间,当大于255字节时,需要2字节的空间,varchar最多能存储65535个字节的数据。
「老面试官」:varchar最多能存储65535个字节的数据这个不对吧?
「小扎」:这个我没说清楚,其实是这样的,varchar 的最大长度受限于最大行长度(max row size,65535bytes),65535个字节包括所有字段的长度,比如上面说到的如果varchar超过255个字节的时候还需要额外的2个字节来存储,一个字段如果允许为NULL,那么还需要一个字节来标识。因此假设表中只有一个允许为NULL的varchar类型的话,它能支持的最大长度就是65535-2-1=65532个字节。
「老面试官」:你知道MySQL的隐式转换吗?
「小扎」:你说的应该就是如果索引字段是int型,但是查询的时候传过来的是字符型吧?
「老面试官」:算是吧,你说说看。
「小扎」:如果是这样情况的话,字符型会被转换成int型,依然能够使用到索引。
「老面试官」:那如果索引字段是字符型,但是传过来的是个整型数字呢?
「小扎」:(嘿嘿,早知道来这一套)那这时候是用不到索引的,当出现字符串和数字比较的时候,MySQL会把字符串转换成数字,那么这时候索引就失效了。
「老面试官」:你一般都是如何建立索引的,比如怎么判断哪些字段需要加索引?
「小扎」:最简单的就是经常需要出现在where条件中的字段会加索引,同时一些重复度高的字段最好不要加索引,比如像性别字段
「老面试官」:等等,这里能说说为什么性别这样的字段不适合加索引吗?
「小扎」:这个是这样的,假设现在有张表,表中有10w数据并且男女各5w,如果走性别索引的话,那么就要回表5w次,关键这5w次的回表对于主键索引来说,每次都要从根节点开始往下找,这时MySQL会觉得这样效率不高,搞不好还没有全表扫描来的快,最起码全表扫描只要顺着叶子节点一直向后找即可,因此这时就用不到性别索引,还白白浪费了对性别索引的维护。
老面试官满意地笑了笑,然后起身和小扎说了下,你这等一下吧。 “好的”,小扎连连点头,小扎心里想接下来最多就是技术总监来面了,但是一般技术总监都不会问这么细的知识的,暗暗窃喜的小扎万万没想到接下来这位更刚的技术总监会问他...。
未完待续...
最后
码字不易,各位的点赞就是作者最大的创作动力,敬请关注公众号【假装懂编程】,程序员小扎的三面会在这上面首发哦。

推荐阅读:
|








- 上一条: 在Hbase使用过滤器(行键过滤器、列族与列过滤器、值过滤器) 2021-12-06
- 下一条: 关于RS485串口使用的记录 2021-12-06
- 字节跳动 Service Mesh 数据面编译优化实践 2022-04-07
- 二分搜索树的原理与Java源码实现 2021-07-09
- 二叉搜索树(Binary Search Tree)(Java实现) 2021-07-07
- 另有其人?林生斌二婚妻子身份被扒,前任去世一年就成为公司高管 2021-07-05
- 美媒急了:中国或走日本老路,“永远第二” 2021-07-07


