Java程序员涨薪必备的性能调优知识点,收好了!
Java 应用性能优化是一个老生常谈的话题,典型的性能问题如页面响应慢、接口超时,服务器负载高、并发数低,数据库频繁死锁等。尤其是在“糙快猛”的互联网开发模式大行其道的今天,随着系统访问量的增加和代码的日渐臃肿,各种性能问题开始纷至沓来。Java 应用性能的瓶颈点非常多,比如磁盘、内存、网络 I/O 等系统因素,Java 应用代码,JVM GC,数据库,缓存等。将 Java 性能优化分为 4 个层级:应用层、数据库层、框架层、JVM 层。
每层优化难度逐级增加,涉及的知识和解决的问题也会不同。
- 应用层需要理解代码逻辑,通过 Java 线程栈定位有问题代码行等;
- 数据库层面需要分析 SQL、定位死锁等;
- 框架层需要懂源代码,理解框架机制;
- JVM 层需要对 GC 的类型和工作机制有深入了解,对各种 JVM 参数作用了然于胸。
围绕 Java 性能优化,有两种最基本的分析方法:现场分析法和事后分析法。现场分析法通过保留现场,再采用诊断工具分析定位。现场分析对线上影响较大,部分场景(特别是涉及到用户关键的在线业务时)不太合适。事后分析法需要尽可能多收集现场数据,然后立即恢复服务,同时针对收集的现场数据进行事后分析和复现。下面我们从性能诊断工具出发,分享回顾HeapDump性能社区中的一些经典案例与实践。
性能诊断工具
性能诊断一种是针对已经确定有性能问题的系统和代码进行诊断,还有一种是对预上线系统提前性能测试,确定性能是否符合上线要求。本文主要针对前者,后者可以用各种性能压测工具(例如 JMeter)进行测试,不在本文讨论范围内。针对 Java 应用,性能诊断工具主要分为两层:OS 层面和 Java 应用层面(包括应用代码诊断和 GC 诊断)。
OS 诊断
OS 的诊断主要关注的是 CPU、Memory、I/O 三个方面。
CPU 诊断
对于 CPU 主要关注平均负载(Load Average),CPU 使用率,上下文切换次数(Context Switch)。
通过 top 命令可以查看系统平均负载和 CPU 使用率。 PerfMa开源的XPocket插件容器中集成了top_x,它是linux top的增强版, 可以显示CPU占用率/负载,CPU及内存进程使用的list。这个插件对于繁杂的top命令输出进行了功能的拆分和整理,更加清晰易用,支持管道化,尤其可以直接拿到top进程或线程tid、pid;。mem_s命令增加了按照进程swap大小占用排序增强了原有top功能。 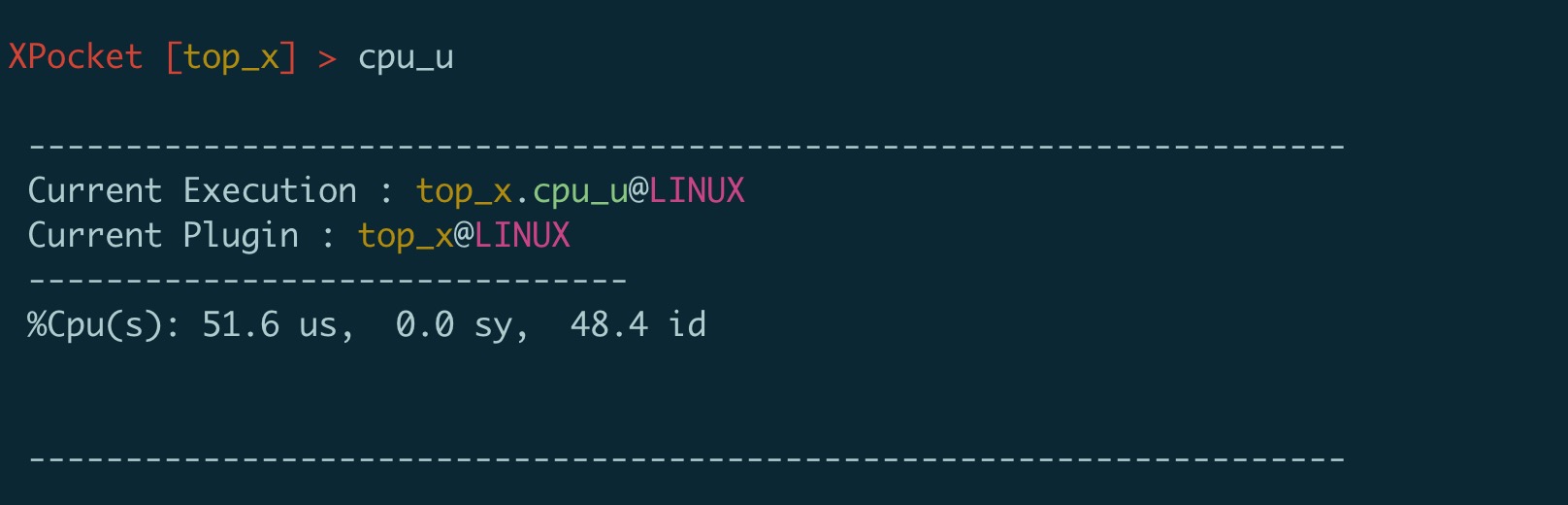 图上显示当前系统的 cpu被使用了51%多。在发现某些进程占用cpu比较高时,可以使用top_x的 cpu_t命令,该命令会自动获取当前cpu占用最高进程的cpu情况,也可以通过-p参数指定进程pid,直接使用cpu_t可以看到:
图上显示当前系统的 cpu被使用了51%多。在发现某些进程占用cpu比较高时,可以使用top_x的 cpu_t命令,该命令会自动获取当前cpu占用最高进程的cpu情况,也可以通过-p参数指定进程pid,直接使用cpu_t可以看到: 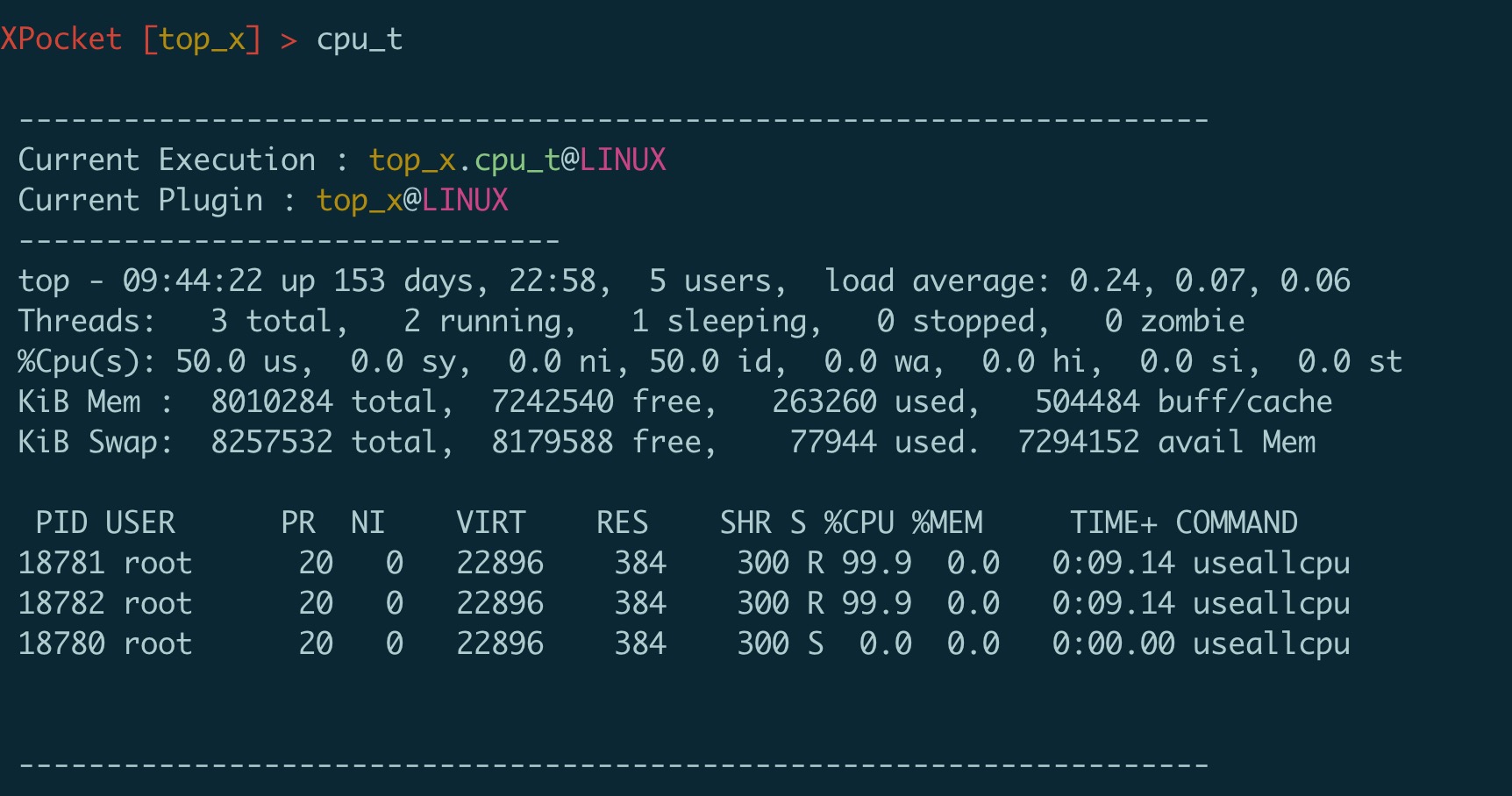 通过 vmstat 命令可以查看 CPU 的上下文切换次数,XPocket同样集成了vmstat工具。
通过 vmstat 命令可以查看 CPU 的上下文切换次数,XPocket同样集成了vmstat工具。 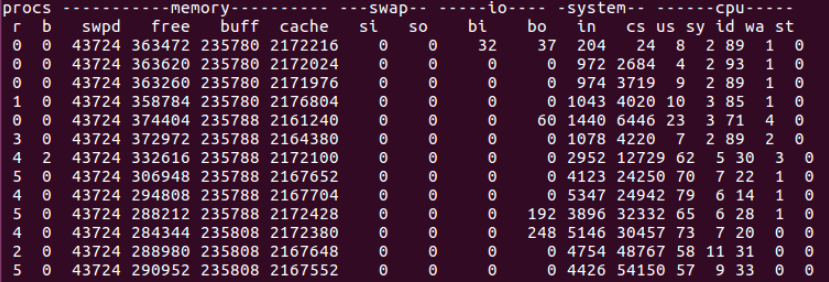
上下文切换次数发生的场景主要有如下几种:
- 时间片用完,CPU 正常调度下一个任务
- 被其它优先级更高的任务抢占
- 执行任务碰到 I/O 阻塞,挂起当前任务,切换到下一个任务
- 用户代码主动挂起当前任务让出 CPU
- 多任务抢占资源,由于没有抢到被挂起
- 硬件中断。
Java 线程上下文切换主要来自共享资源的竞争。一般单个对象加锁很少成为系统瓶颈,除非锁粒度过大。但在一个访问频度高,对多个对象连续加锁的代码块中就可能出现大量上下文切换,成为系统瓶颈。作者朱纪兵的CPU上下文切换导致服务雪崩一文中就记录了在log4j使用异步AsyncLogger写日志导致的CPU频繁上下文切换最终导致服务雪崩的案例。AsyncLogger使用了disruptor框架,而disruptor框架在核心数据结构RingBuffer上处理MultiProducer。在写入日志的时候需要Sequence,但是此时RingBuffer已经满了,获取不到Sequence,disruptor会调用Unsafe.park会将当前线程主动挂起。简单来说就是消费速度跟不上生产速度的时候,生产线程做了无限重试,重试间隔为1 nano,导致cpu频繁挂起唤醒,发生大量cpu切换,占用cpu资源。把Distuptor版本和og4j2版本分别到3.3.6 和 2.7问题得以解决。
Memory
从操作系统角度,内存关注应用进程是否足够,可以使用 free –m 命令查看内存的使用情况。通过 top 命令可以查看进程使用的虚拟内存 VIRT 和物理内存 RES,根据公式 VIRT = SWAP + RES 可以推算出具体应用使用的交换分区(Swap)情况,使用交换分区过大会影响 Java 应用性能,可以将 swappiness 值调到尽可能小。因为对于 Java 应用来说,占用太多交换分区可能会影响性能,毕竟磁盘性能比内存慢太多。
I/O
I/O 包括磁盘 I/O 和网络 I/O,一般情况下磁盘更容易出现 I/O 瓶颈。通过 iostat 可以查看磁盘的读写情况,通过 CPU 的 I/O wait 可以看出磁盘 I/O 是否正常。如果磁盘 I/O 一直处于很高的状态,说明磁盘太慢或故障,成为了性能瓶颈,需要进行应用优化或者磁盘更换。
除了常用的 top、 ps、vmstat、iostat 等命令,还有其他 Linux 工具可以诊断系统问题,如 mpstat、tcpdump、netstat、pidstat、sar 等。此处总结列出了 Linux 不同设备类型的性能诊断工具,如下图所示,可供参考。 
Java 应用诊断工具
应用代码诊断
应用代码性能问题是相对好解决的一类性能问题。通过一些应用层面监控报警,如果确定有问题的功能和代码,直接通过代码就可以定位;或者通过 top+jstack,找出有问题的线程栈,定位到问题线程的代码上,也可以发现问题。对于更复杂,逻辑更多的代码段,通过 Stopwatch 打印性能日志往往也可以定位大多数应用代码性能问题。
常用的 Java 应用诊断包括线程、堆栈、GC 等方面的诊断。
jstack
jstack 命令通常配合 top 使用,通过 top -H -p pid 定位 Java 进程和线程,再利用 jstack -l pid 导出线程栈。由于线程栈是瞬态的,因此需要多次 dump,一般 3 次 dump,一般每次隔 5s 就行。将 top 定位的 Java 线程 pid 转成 16 进制,得到 Java 线程栈中的 nid,可以找到对应的问题线程栈。
XPocket中集成了jstack_x工具,可以使用stack -t nid命令查看某个等待锁线程的调用栈,通过调用栈来定位业务代码。 
XElephant、XSheepdog
XElephant是HeapDmp性能社区免费提供的一款在线分析Java内存Dump文件的产品。可以让内存里对象之间的各种依赖关系更加清晰明了,无需安装软件,提供上传方式,不受本地机器内存限制,支持超大Dump文件分析。 
XSheepdog是HeapDmp性能社区免费提供的一款在线分析线程Dump文件的产品,将线程、线程池、栈、方法及锁的关系梳理清楚,通过多种视角呈献给用户,让线程问题一目了然。 
GC 诊断
Java GC 解决了程序员管理内存的风险,但 GC 引起的应用暂停成了另一个需要解决的问题。JDK 提供了一系列工具来定位 GC 问题,比较常用的有 jstat、jmap,还有第三方工具 MAT 等。
jstat
jstat 命令可打印 GC 详细信息,Young GC 和 Full GC 次数,堆信息等。其命令格式为 jstat –gcxxx -t pid <interval> <count>。 
MAT
MAT 是 Java 堆的分析利器,提供了直观的诊断报告,内置的 OQL 允许对堆进行类 SQL 查询,功能强大,outgoing reference 和 incoming reference 可以对对象引用追根溯源。 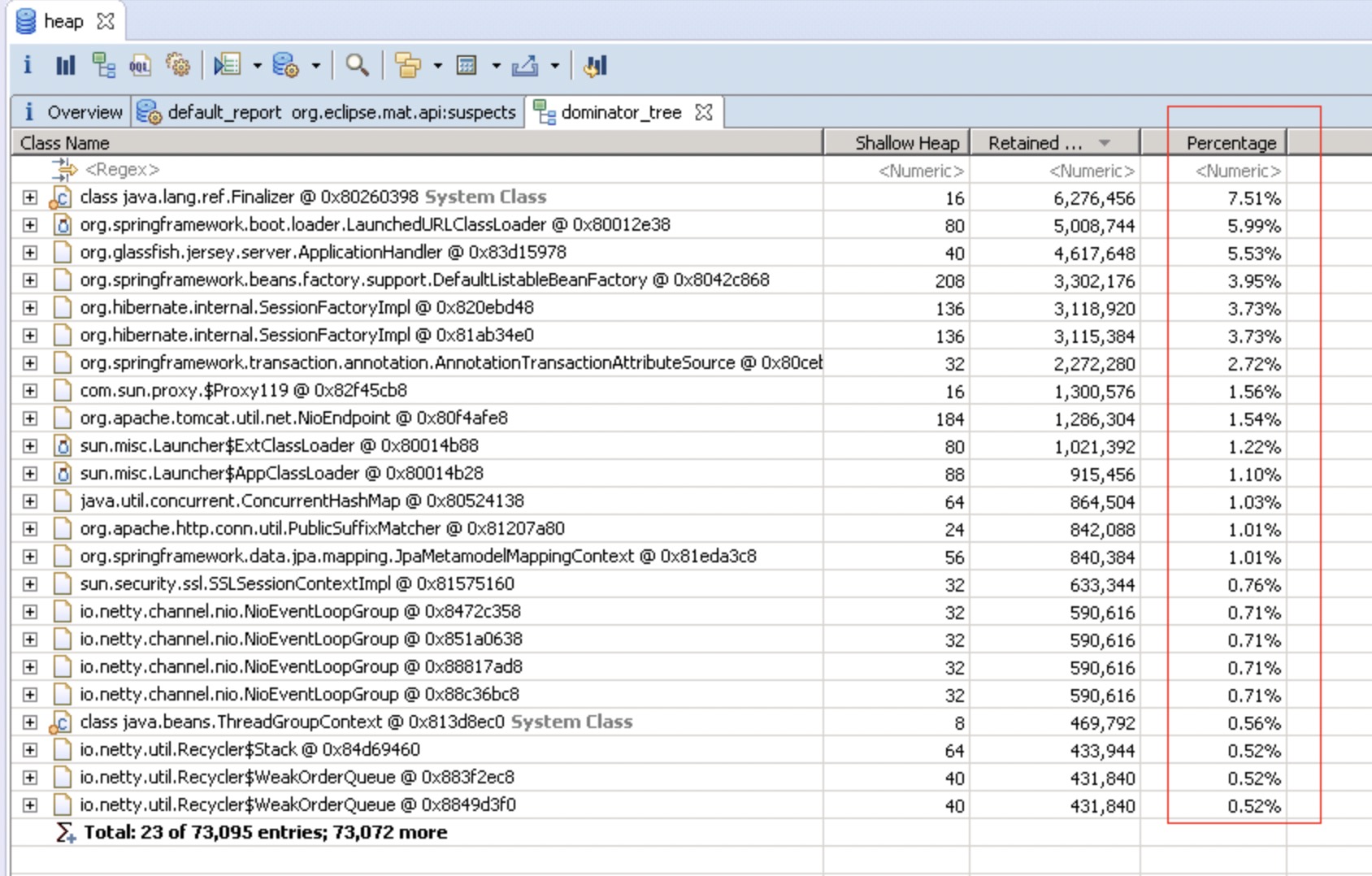
MAT 有两列显示对象大小,分别是 Shallow size 和 Retained size,前者表示对象本身占用内存的大小,不包含其引用的对象,后者是对象自己及其直接或间接引用的对象的 Shallow size 之和,即该对象被回收后 GC 释放的内存大小,一般说来关注后者大小即可。对于有些大堆 (几十 G) 的 Java 应用,需要较大内存才能打开 MAT。通常本地开发机内存过小,是无法打开的,建议在线下服务器端安装图形环境和 MAT,远程打开查看。或者执行 mat 命令生成堆索引,拷贝索引到本地,不过这种方式看到的堆信息有限。
为了诊断 GC 问题,建议在 JVM 参数中加上-XX:+PrintGCDateStamps。
对于 Java 应用,通过 top+jstack+jmap+MAT 可以定位大多数应用和内存问题,可谓必备工具。有些时候,Java 应用诊断需要参考 OS 相关信息,可使用一些更全面的诊断工具,比如 Zabbix(整合了 OS 和 JVM 监控)等。在分布式环境中,分布式跟踪系统等基础设施也对应用性能诊断提供了有力支持。
性能优化实践
在介绍了一些常用的性能诊断工具后,下面将结合我们在 Java 应用调优中的一些实践,从 JVM 层、应用代码层以及数据库层进行案例分享。
JVM 调优:GC 之痛
作者阿飞Javaer的FullGC实战:业务小姐姐查看图片时一直在转圈圈 一文中记录了接口耗时长导致图片无法访问的情况,排除掉数据库、同步日至阻塞问题、系统问题后,开始排查GC问题。使用jstat命令后输出结果如下所示
bash-4.4$ /app/jdk1.8.0_192/bin/jstat -gc 1 2s S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 170496.0 170496.0 0.0 0.0 171008.0 130368.9 1024000.0 590052.8 70016.0 68510.8 8064.0 7669.0 983 13.961 1400 275.606 289.567 170496.0 170496.0 0.0 0.0 171008.0 41717.2 1024000.0 758914.9 70016.0 68510.8 8064.0 7669.0 987 14.011 1401 275.722 289.733 170496.0 170496.0 0.0 0.0 171008.0 126547.2 1024000.0 770587.2 70016.0 68510.8 8064.0 7669.0 990 14.091 1403 275.986 290.077 170496.0 170496.0 0.0 0.0 171008.0 45488.7 1024000.0 650767.0 70016.0 68531.9 8064.0 7669.0 994 14.148 1405 276.222 290.371 170496.0 170496.0 0.0 0.0 171008.0 146029.1 1024000.0 714857.2 70016.0 68531.9 8064.0 7669.0 995 14.166 1406 276.366 290.531 170496.0 170496.0 0.0 0.0 171008.0 118073.5 1024000.0 669163.2 70016.0 68531.9 8064.0 7669.0 998 14.226 1408 276.736 290.962 170496.0 170496.0 0.0 0.0 171008.0 3636.1 1024000.0 687630.0 70016.0 68535.6 8064.0 7669.6 1001 14.342 1409 276.871 291.213 170496.0 170496.0 0.0 0.0 171008.0 87247.2 1024000.0 704977.5 70016.0 68535.6 8064.0 7669.6 1005 14.463 1411 277.099 291.562
几乎每1秒都有一次FGC,且停顿时间相当长。最后关闭了参数 -XX:-UseAdaptiveSizePolicy,优化后重启服务,访问速度又快起来了。
GC 调优对高并发大数据量交互的应用还是很有必要的,尤其是默认 JVM 参数通常不满足业务需求,需要进行专门调优。GC 日志的解读有很多公开的资料,本文不再赘述。GC 调优目标基本有三个思路:降低 GC 频率,可以通过增大堆空间,减少不必要对象生成;降低 GC 暂停时间,可以通过减少堆空间,使用 CMS GC 算法实现;避免 Full GC,调整 CMS 触发比例,避免 Promotion Failure 和 Concurrent mode failure(老年代分配更多空间,增加 GC 线程数加快回收速度),减少大对象生成等。
应用层调优:嗅到坏代码的味道
从应用层代码调优入手,剖析代码效率下降的根源,无疑是提高 Java 应用性能的很好的手段之一。 FGC实战:坏代码导致服务频繁FGC无响应问题分析一文就记录了坏代码导致内存泄漏CPU占用过高大量接口超时的案例。 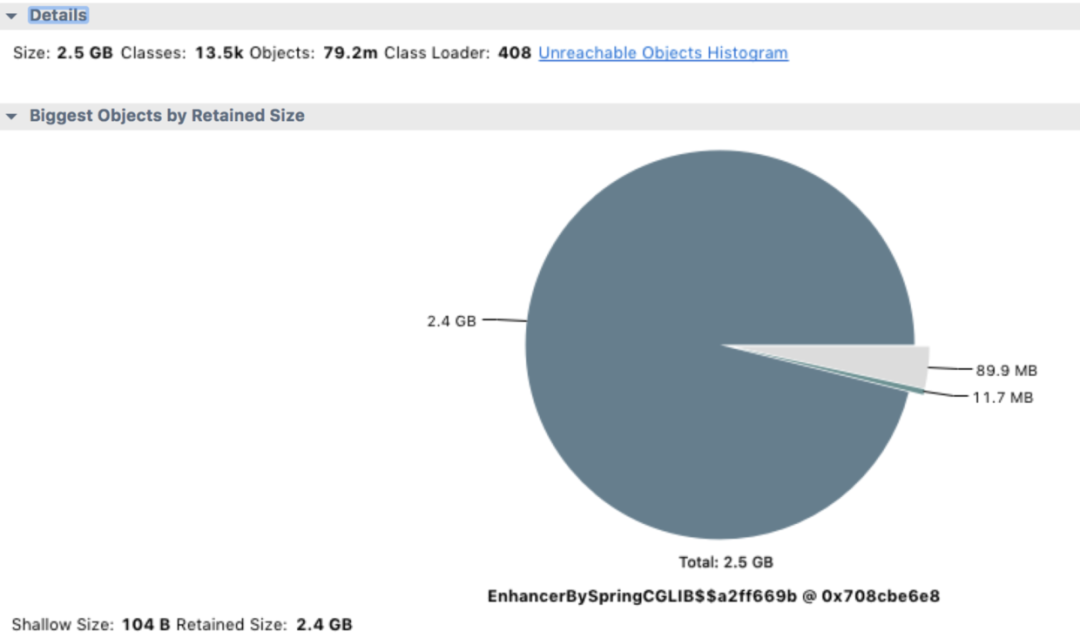 使用MAT工具分析jvm Heap,从上面的饼图中可以看出,绝大多数堆内存都被同一个内存占用了,再查看堆内存详情,向上层追溯,很快就发现了罪魁祸首。
使用MAT工具分析jvm Heap,从上面的饼图中可以看出,绝大多数堆内存都被同一个内存占用了,再查看堆内存详情,向上层追溯,很快就发现了罪魁祸首。 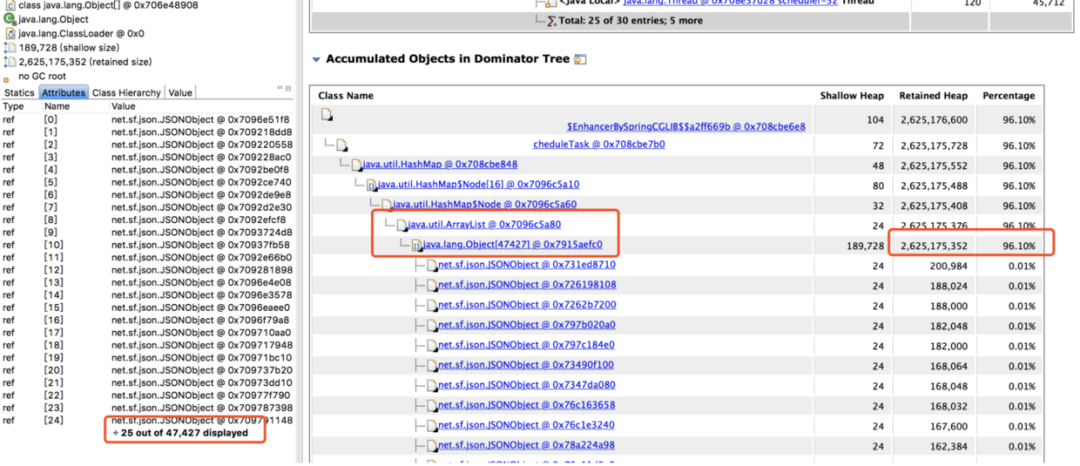 找到内存泄漏的对象了,在项目里全局搜索对象名,它是一个 Bean 对象,然后定位到它的一个类型为 Map 的属性。这个 Map 根据类型用 ArrayList 存储了每次探测接口响应的结果,每次探测完都塞到 ArrayList 里去分析,由于 Bean 对象不会被回收,这个属性又没有清除逻辑,所以在服务十来天没有上线重启的情况下,这个 Map 越来越大,直至将内存占满。内存满了之后,无法再给 HTTP 响应结果分配内存了,所以一直卡在 readLine 那。而我们那个大量 I/O 的接口报警次数特别多,估计跟响应太大需要更多内存有关。
找到内存泄漏的对象了,在项目里全局搜索对象名,它是一个 Bean 对象,然后定位到它的一个类型为 Map 的属性。这个 Map 根据类型用 ArrayList 存储了每次探测接口响应的结果,每次探测完都塞到 ArrayList 里去分析,由于 Bean 对象不会被回收,这个属性又没有清除逻辑,所以在服务十来天没有上线重启的情况下,这个 Map 越来越大,直至将内存占满。内存满了之后,无法再给 HTTP 响应结果分配内存了,所以一直卡在 readLine 那。而我们那个大量 I/O 的接口报警次数特别多,估计跟响应太大需要更多内存有关。
对于坏代码的定位,除了常规意义上的代码审查外,借助 MAT 等工具也可以在一定程度对系统性能瓶颈点进行快速定位。但是一些与特定场景绑定或者业务数据绑定的情况,却需要辅助代码走查、性能检测工具、数据模拟甚至线上引流等方式才能最终确认性能问题的出处。以下是我们总结的一些坏代码可能的一些特征,供大家参考: (1)代码可读性差,无基本编程规范; (2)对象生成过多或生成大对象,内存泄露等; (3)IO 流操作过多,或者忘记关闭; (4)数据库操作过多,事务过长; (5)同步使用的场景错误; (6)循环迭代耗时操作等。
数据库层调优:死锁噩梦
对于大部分 Java 应用来说,与数据库进行交互的场景非常普遍,尤其是 OLTP 这种对于数据一致性要求较高的应用,数据库的性能会直接影响到整个应用的性能。
通常来说,对于数据库层的调优我们基本上会从以下几个方面出发: (1)在 SQL 语句层面进行优化:慢 SQL 分析、索引分析和调优、事务拆分等; (2)在数据库配置层面进行优化:比如字段设计、调整缓存大小、磁盘 I/O 等数据库参数优化、数据碎片整理等; (3)从数据库结构层面进行优化:考虑数据库的垂直拆分和水平拆分等; (4)选择合适的数据库引擎或者类型适应不同场景,比如考虑引入 NoSQL 等。
总结与建议
性能调优同样遵循 2-8 原则,80%的性能问题是由 20%的代码产生的,因此优化关键代码事半功倍。同时,对性能的优化要做到按需优化,过度优化可能引入更多问题。对于 Java 性能优化,不仅要理解系统架构、应用代码,同样需要关注 JVM 层甚至操作系统底层。总结起来主要可以从以下几点进行考虑:
1)基础性能的调优 这里的基础性能指的是硬件层级或者操作系统层级的升级优化,比如网络调优,操作系统版本升级,硬件设备优化等。比如 F5 的使用和 SDD 硬盘的引入,包括新版本 Linux 在 NIO 方面的升级,都可以极大的促进应用的性能提升;
2)数据库性能优化 包括常见的事务拆分,索引调优,SQL 优化,NoSQL 引入等,比如在事务拆分时引入异步化处理,最终达到一致性等做法的引入,包括在针对具体场景引入的各类 NoSQL 数据库,都可以大大缓解传统数据库在高并发下的不足;
3)应用架构优化 引入一些新的计算或者存储框架,利用新特性解决原有集群计算性能瓶颈等;或者引入分布式策略,在计算和存储进行水平化,包括提前计算预处理等,利用典型的空间换时间的做法等;都可以在一定程度上降低系统负载;
4)业务层面的优化 技术并不是提升系统性能的唯一手段,在很多出现性能问题的场景中,其实可以看到很大一部分都是因为特殊的业务场景引起的,如果能在业务上进行规避或者调整,其实往往是最有效的。
|








- 上一条: 2021山东省大学生网络技术大赛网络安全赛道决赛WP 2021-10-25
- 下一条: 面试官问我:从地址栏输入URL到显示页面都发生了什么?(建议收藏) 2021-10-26
- 我招了个“水货”程序员 2021-06-27
- 新手程序员必读的十本经典著作 2021-06-27
- Java多线程知识点汇集 2021-11-18
- ElasticSearch还能性能调优,涨见识、涨见识了!!! 2023-03-29
- Java 程序员必须掌握的 10 款开源工具! 2021-09-09

